



VToonifyによる実写動画の好きなスタイルでのアニメ化

この記事では、VToonifyを用いて、人の顔の画像や動画を、好きなスタイルでアニメ化する方法を紹介します。
VToonifyとは
VToonifyは、パラメータを自由に調整しながら、動画のスタイル変換を高解像度で行うフレームワークです。
実際のイメージはこちらの3分の公式動画をぜひご覧ください。パラメータをぐりぐり動かして結果が変わっていく様子がよく分かります。
VToonifyのネットワークのイメージは下図のとおりです。Eはencoder、Gはgeneratorを表します。
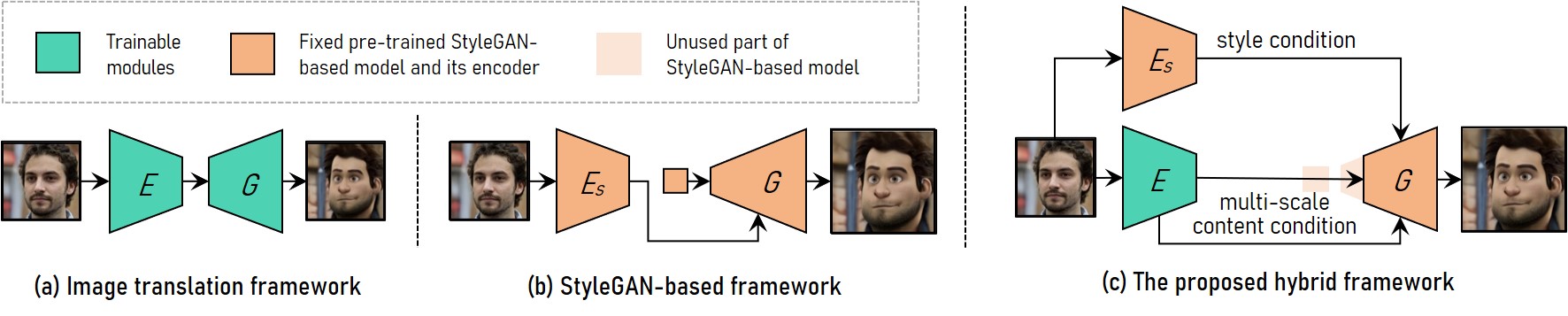
従来のStyleGANベースのフレームワーク(b)は、高解像度のスタイル変換を実現することはできたものの、あらかじめ固定されたサイズにクロップする必要があるという制約がありました。一方、StyleGANから学習用のペア画像を生成し、それによってスタイル変換を学習するというフレームワーク(a)は、入力サイズの制限はないものの、StyleGANの特徴である柔軟なコントロールができません。
そこで、本手法では、(b)のベースは維持したまま、サイズに依存しない(a)のencoderを組み合わせることで、双方のメリットを取り入れたフレームワーク(c)を実現しています。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、環境設定等のすべてのコードを含むノートブックは、以下のリンクから直接参照することができます。
![]()
モデル設定
上記のcolabファイルに沿って環境設定が完了したら、利用するモデルを選択します。提供されている学習済みモデルは7種類あるので、変換後のイメージに合わせて選んでいきます。
style_type = "pixar052" # cartoon026: balanced # cartoon299: big eyes # arcane000: for female # arcane077: for male # pixar052 # caricature039: big mouth # caricature068: balanced
選択したモデルをダウンロードします。
# ダウンロード用関数定義 def get_download_model_command(file_id, file_name): """ Get wget download command for downloading the desired model and save to directory ../checkpoint/. """ current_directory = os.getcwd() save_path = MODEL_DIR if not os.path.exists(save_path): os.makedirs(save_path) url = r"""wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id={FILE_ID}' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id={FILE_ID}" -O {SAVE_PATH}/{FILE_NAME} && rm -rf /tmp/cookies.txt""".format(FILE_ID=file_id, FILE_NAME=file_name, SAVE_PATH=save_path) return url MODEL_PATHS = { "encoder": {"id": "1NgI4mPkboYvYw3MWcdUaQhkr0OWgs9ej", "name": "encoder.pt"}, "faceparsing": {"id": "1jY0mTjVB8njDh6e0LP_2UxuRK3MnjoIR", "name": "faceparsing.pth"}, "arcane_exstyle": {"id": "1TC67wRJkdmNRZTqYMUEFkrhWRKKZW40c", "name": "exstyle_code.npy"}, "caricature_exstyle": {"id": "1xr9sx_WmRYJ4qHGTtdVQCSxSo4HP3-ip", "name": "exstyle_code.npy"}, "cartoon_exstyle": {"id": "1BuCeLk3ASZcoHlbfT28qNru4r5f-hErr", "name": "exstyle_code.npy"}, "pixar_exstyle": {"id": "1yTaKuSrL7I0i0RYEEK5XD6GI-y5iNUbj", "name": "exstyle_code.npy"}, "arcane000": {"id": "1pF4fJ8acmawMsjjXo4HXRIOXeZR8jLVh", "name": "generator.pt"}, "arcane077": {"id": "16rLTF2oC0ZeurnM6hjrfrc8BxtW8P8Qf", "name": "generator.pt"}, "caricature039": {"id": "1C1E4WEoDWzl0nAxR9okKffFmlMOENbeF", "name": "generator.pt"}, "caricature068": {"id": "1B1ko1x8fX2aJ4BYCL12AnknVAi3qQc8W", "name": "generator.pt"}, "cartoon026": {"id": "1YJYODh_vEyUrL0q02okjcicpJhdYY8An", "name": "generator.pt"}, "cartoon299": {"id": "101qMUMfcI2qDxEbfCBt5mOg2aSqdTaIt", "name": "generator.pt"}, "pixar052": {"id": "16j_l1x0DD0PjwO8YdplAk69sh3-v95rr", "name": "generator.pt"}, "cartoon": {"id": "11s0hwhZWTLacMAzZH4OU-o3Qkp54h30J", "name": "generator.pt"}, } # download pSp encoder and face parsinf network path = MODEL_PATHS["encoder"] download_command = get_download_model_command(file_id=path["id"], file_name=path["name"]) !{download_command} path = MODEL_PATHS["faceparsing"] download_command = get_download_model_command(file_id=path["id"], file_name=path["name"]) !{download_command} # download vtoonify path = MODEL_PATHS[style_type] download_command = get_download_model_command(file_id=path["id"], file_name = style_type + '_' + path["name"]) !{download_command} # download extrinsic style code path = MODEL_PATHS[style_type[:-3]+'_exstyle'] download_command = get_download_model_command(file_id=path["id"], file_name = style_type[:-3] + '_' + path["name"]) !{download_command}
ダウンロードしたモデル群をロードします。
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5,0.5,0.5]),
])
vtoonify = VToonify(backbone = 'dualstylegan')
vtoonify.load_state_dict(torch.load(os.path.join(MODEL_DIR, style_type+'_generator.pt'), map_location=lambda storage, loc: storage)['g_ema'])
vtoonify.to(device)
parsingpredictor = BiSeNet(n_classes=19)
parsingpredictor.load_state_dict(torch.load(os.path.join(MODEL_DIR, 'faceparsing.pth'), map_location=lambda storage, loc: storage))
parsingpredictor.to(device).eval()
modelname = './checkpoint/shape_predictor_68_face_landmarks.dat'
if not os.path.exists(modelname):
import wget, bz2
wget.download('http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2', modelname+'.bz2')
zipfile = bz2.BZ2File(modelname+'.bz2')
data = zipfile.read()
open(modelname, 'wb').write(data)
landmarkpredictor = dlib.shape_predictor(modelname)
pspencoder = load_psp_standalone(os.path.join(MODEL_DIR, 'encoder.pt'), device)
exstyles = np.load(os.path.join(MODEL_DIR, style_type[:-3]+'_exstyle_code.npy'), allow_pickle='TRUE').item()
stylename = list(exstyles.keys())[int(style_type[-3:])]
exstyle = torch.tensor(exstyles[stylename]).to(device)
with torch.no_grad():
exstyle = vtoonify.zplus2wplus(exstyle)
推論
まずは、静止画をスタイル変換してみます。
import os from google.colab import files # 画像のアップロード uploaded = files.upload() # ファイルパスの取得 image_path = list(uploaded.keys())[0] # 画像の読込 original_image = load_image(image_path) # 顔の切出し frame = cv2.imread(image_path) frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) scale = 1 kernel_1d = np.array([[0.125],[0.375],[0.375],[0.125]]) paras = get_video_crop_parameter(frame, landmarkpredictor, padding=[200,200,200,200]) if paras is not None: h, w, top, bottom, left, right, scale = paras H, W = int(bottom-top), int(right-left) if scale <= 0.75: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) if scale <= 0.375: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) frame = cv2.resize(frame, (w, h))[top:bottom, left:right] x = transform(frame).unsqueeze(dim=0).to(device) # 描画 visualize(original_image[0], 30)
元画像はこちらです。

ちなみに、このオリジナル画像自体もStable Diffusionで生成したものです。
推論を実行します。
with torch.no_grad(): I = align_face(frame, landmarkpredictor) I = transform(I).unsqueeze(dim=0).to(device) s_w = pspencoder(I) s_w = vtoonify.zplus2wplus(s_w) s_w[:,:7] = exstyle[:,:7] x_p = F.interpolate(parsingpredictor(2*(F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)))[0], scale_factor=0.5, recompute_scale_factor=False).detach() inputs = torch.cat((x, x_p/16.), dim=1) y_tilde = vtoonify(inputs, s_w.repeat(inputs.size(0), 1, 1), d_s = 0.5) y_tilde = torch.clamp(y_tilde, -1, 1) # 描画 visualize(y_tilde[0].cpu(), 60)
左上がオリジナルで、右上がcartoon026、左下がcartoon299、右下がpixar052による変換後です。

続いて、動画のスタイル変換を試してみます。
# 動画のアップロード uploaded = files.upload() # ファイルパスの取得 video_path = list(uploaded.keys())[0] # 動画の読込 video_cap = cv2.VideoCapture(video_path) num = int(video_cap.get(7)) success, frame = video_cap.read() if success == False: assert('load video frames error') frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 顔の切出し scale = 1 kernel_1d = np.array([[0.125],[0.375],[0.375],[0.125]]) paras = get_video_crop_parameter(frame, landmarkpredictor, padding=[200,200,200,200]) if paras is None: print('no face detected!') else: h,w,top,bottom,left,right,scale = paras H, W = int(bottom-top), int(right-left) if scale <= 0.75: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) if scale <= 0.375: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) frame = cv2.resize(frame, (w, h))[top:bottom, left:right]
# 推論 fourcc = cv2.VideoWriter_fourcc(*'mp4v') videoWriter = cv2.VideoWriter(os.path.join(OUT_DIR, 'result.mp4'), fourcc, video_cap.get(5), (4*W, 4*H)) batch_size = 4 with torch.no_grad(): batch_frames = [] for i in tqdm(range(num)): if i == 0: I = align_face(frame, landmarkpredictor) I = transform(I).unsqueeze(dim=0).to(device) s_w = pspencoder(I) s_w = vtoonify.zplus2wplus(s_w) s_w[:,:7] = exstyle[:,:7] else: success, frame = video_cap.read() frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) if scale <= 0.75: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) if scale <= 0.375: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) frame = cv2.resize(frame, (w, h))[top:bottom, left:right] batch_frames += [transform(frame).unsqueeze(dim=0).to(device)] if len(batch_frames) == batch_size or (i+1) == num: x = torch.cat(batch_frames, dim=0) batch_frames = [] x_p = F.interpolate(parsingpredictor(2*(F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)))[0], scale_factor=0.5, recompute_scale_factor=False).detach() inputs = torch.cat((x, x_p/16.), dim=1) y_tilde = vtoonify(inputs, s_w.repeat(inputs.size(0), 1, 1), d_s = 0.5) y_tilde = torch.clamp(y_tilde, -1, 1) for k in range(y_tilde.size(0)): videoWriter.write(tensor2cv2(y_tilde[k].cpu())) videoWriter.release() video_cap.release() viz = torchvision.utils.make_grid(y_tilde, 2, 2) visualize(viz.cpu(), 120)
結果は ./output/result.mp4に保存されます。
先ほどと同様、左上がオリジナルで、右上がcartoon026、左下がcartoon299、右下がpixar052による変換後です。
かなり自然に変換されていることが分かります。
公開されているコードを使って、公式動画にあるように連続的にスタイルを変化させていくことも可能です。
まとめ
高速に推論できて、かつ好きなスタイルに調整できることで、従来に比べて応用範囲が大きく広がりそうな技術です。任意の動画をアップロードするだけで簡単に試すことができるので、ぜひ遊んでみてください。

チーム・カルポ 秀和システム 2021年08月31日頃