



【入門】Vision Transformerによる画像分類

この記事は、Vision Transformerを用いて画像分類を行うチュートリアルです。Vision Transformerの概要の紹介から始め、実装まで行っていきます。
Vision Transformerとは
Transformerは、もともと自然言語処理分野で提案されたモデルです。機械翻訳での利用を想定されていたことから、入力文章をベクトル化(特徴量化)するEncoderと、特徴量を受け取って文章を生成するDecoderから構成されています。当時多く用いられていたRNNやCNNを超える精度を達成したことから大きな話題となり、その後BERTやGPT-3といった高性能事前学習モデルのベースとして採用されています。
Vision Transformer(ViT)は、TransformerのEncoderを画像の特徴量抽出に利用します。画像処理の特徴量抽出はCNNが主流でしたが、ViTが多くのタスクでより良い精度を達成したため、現在では自然言語処理だけでなく、画像処理分野においても欠かせない存在となっています。
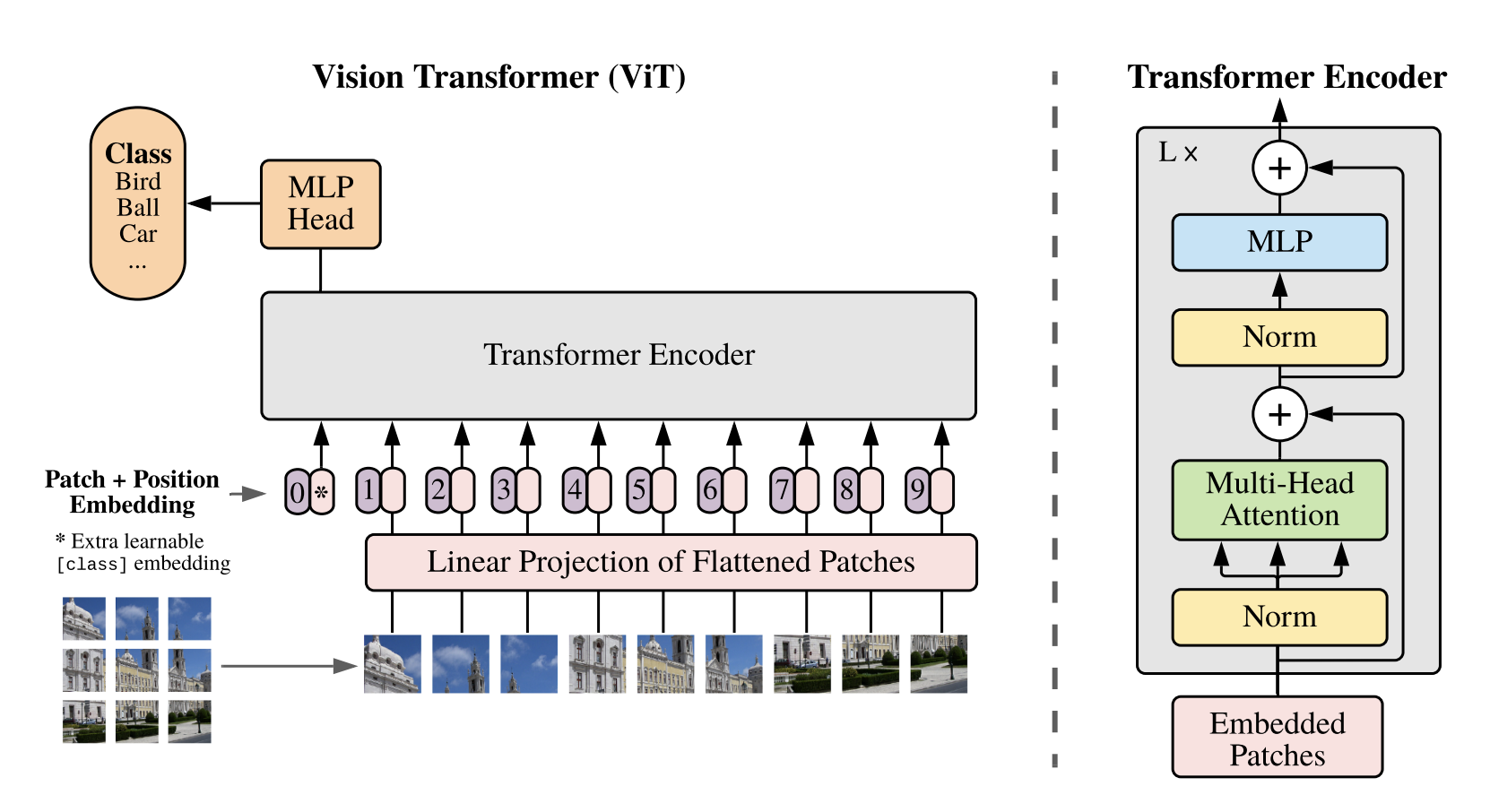
Vision Transformerは、画像をTransformer Encoderに入力できるフォーマットに加工するInput Layer(Linear Projection of Flattened Patches)、特徴量を抽出するTransformer Encoder、そして特徴量を受け取りクラス分類を行うMLP Headからなります。
それぞれの機構の詳細は、以下の参考書籍がとても丁寧で分かりやすいのでオススメです。直感的な説明からスタートし、数式の概要まで段階的に説明されているため、Vision Transformerの全体像をとてもスッキリ理解することができます。

自然言語処理分野での利用例は以下の記事をご覧ください。
画像分類の実装
それでは、Google Colaboratoryを使って分類器を実装していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
事前準備
はじめに、必要となるライブラリのインストール・インポートを行います。
!pip install datasets transformers import random import numpy as np from PIL import ImageDraw, ImageFont, Image from datasets import load_dataset, load_metric from transformers import ViTFeatureExtractor, ViTForImageClassification, TrainingArguments, Trainer import torch
続いて、利用するデータをダウンロードします。今回は、Hugging Faceで公開されている、猫と犬のデータセットを利用します。
ds = load_dataset('Bingsu/Cat_and_Dog')
ダウンロードしたデータはtrainとtestの2つに分割されていますが、さらにtrainからvalidation用のデータを切り分けておきます。
train_val_split = 0.2 split = ds['train'].train_test_split(train_val_split) ds['train'] = split['train'] ds['valid'] = split['test'] # 確認 ds
--- 出力 ---
DatasetDict({
train: Dataset({
features: ['image', 'labels'],
num_rows: 6400
})
test: Dataset({
features: ['image', 'labels'],
num_rows: 2000
})
valid: Dataset({
features: ['image', 'labels'],
num_rows: 1600
})
})
いくつかサンプルを表示してみます。
def show_examples(ds, seed=1234, examples_per_class=2, size=(350, 350)): w, h = size labels = ds['train'].features['labels'].names grid = Image.new('RGB', size=(examples_per_class * w, len(labels) * h)) draw = ImageDraw.Draw(grid) font = ImageFont.truetype("/usr/share/fonts/truetype/liberation/LiberationMono-Bold.ttf", 24) for label_id, label in enumerate(labels): # Filter the dataset by a single label, shuffle it, and grab a few samples ds_slice = ds['train'].filter(lambda ex: ex['labels'] == label_id).shuffle(seed).select(range(examples_per_class)) # Plot this label's examples along a row for i, example in enumerate(ds_slice): image = example['image'] idx = examples_per_class * label_id + i box = (idx % examples_per_class * w, idx // examples_per_class * h) grid.paste(image.resize(size), box=box) draw.text(box, label, (255, 255, 255), font=font) return grid show_examples(ds)

学習
事前学習済みのViTのパラメータをダウンロードします。
model_name_or_path = 'google/vit-base-patch16-224-in21k'
feature_extractor = ViTFeatureExtractor.from_pretrained(model_name_or_path)
上記を用いて画像をベクトル化します。
def transform(example_batch): inputs = feature_extractor([x for x in example_batch['image']], return_tensors='pt') inputs['labels'] = example_batch['labels'] return inputs # ベクトル化 prepared_ds = ds.with_transform(transform) prepared_ds['train'][0:2]
--- 出力 ---
{'pixel_values': tensor([[[[ 0.2157, 0.1765, 0.1608, ..., 0.1373, 0.1451, 0.0980],
[ 0.1216, 0.0745, 0.0667, ..., 0.0667, 0.0588, 0.0039],
[ 0.1373, 0.0980, 0.0824, ..., 0.0824, 0.0353, -0.0353],
...,
[-0.5608, -0.6078, -0.5608, ..., 0.3569, 0.3490, 0.3490],
[-0.5843, -0.6941, -0.7020, ..., 0.3647, 0.3647, 0.3647],
[-0.5608, -0.6627, -0.6706, ..., 0.3647, 0.3725, 0.3725]],
[[ 0.4275, 0.3882, 0.3725, ..., 0.3882, 0.3569, 0.2941],
[ 0.3333, 0.2863, 0.2784, ..., 0.3098, 0.2706, 0.2000],
[ 0.3490, 0.3098, 0.2941, ..., 0.3333, 0.2549, 0.1686],
...,
[-0.4824, -0.5294, -0.4902, ..., 0.6706, 0.6314, 0.6235],
[-0.5373, -0.6549, -0.6627, ..., 0.6784, 0.6471, 0.6392],
[-0.5373, -0.6392, -0.6471, ..., 0.6784, 0.6549, 0.6471]],
[[ 0.2941, 0.2549, 0.2392, ..., 0.3490, 0.3176, 0.2549],
[ 0.2000, 0.1529, 0.1451, ..., 0.2706, 0.2157, 0.1451],
[ 0.2157, 0.1765, 0.1608, ..., 0.2941, 0.1843, 0.0980],
...,
[-0.4431, -0.4980, -0.4510, ..., 0.6078, 0.5922, 0.5922],
[-0.5216, -0.6314, -0.6392, ..., 0.6157, 0.6078, 0.6078],
[-0.5373, -0.6392, -0.6471, ..., 0.6157, 0.6157, 0.6157]]],
[[[ 0.0824, 0.0824, 0.0902, ..., 0.2000, 0.2078, 0.2314],
[ 0.0980, 0.1059, 0.1059, ..., 0.2000, 0.2078, 0.2314],
[ 0.1216, 0.1216, 0.1294, ..., 0.2000, 0.2078, 0.2314],
...,
[ 0.1451, 0.1529, 0.1608, ..., 0.8745, 0.8745, 0.8824],
[ 0.1765, 0.1843, 0.1922, ..., 0.8588, 0.8588, 0.8824],
[ 0.1922, 0.2000, 0.2078, ..., 0.8431, 0.8588, 0.8902]],
[[ 0.0902, 0.0902, 0.0980, ..., 0.2157, 0.2235, 0.2471],
[ 0.1059, 0.1137, 0.1137, ..., 0.2157, 0.2235, 0.2471],
[ 0.1294, 0.1294, 0.1373, ..., 0.2157, 0.2235, 0.2471],
...,
[ 0.1451, 0.1529, 0.1608, ..., 0.8667, 0.8667, 0.8745],
[ 0.1451, 0.1529, 0.1608, ..., 0.8510, 0.8510, 0.8745],
[ 0.1373, 0.1451, 0.1451, ..., 0.8353, 0.8510, 0.8824]],
[[-0.0353, -0.0353, -0.0275, ..., 0.0431, 0.0510, 0.0745],
[-0.0196, -0.0118, -0.0118, ..., 0.0431, 0.0510, 0.0745],
[ 0.0118, 0.0118, 0.0196, ..., 0.0431, 0.0510, 0.0745],
...,
[ 0.0353, 0.0431, 0.0510, ..., 0.8353, 0.8353, 0.8431],
[ 0.0510, 0.0588, 0.0667, ..., 0.8196, 0.8196, 0.8431],
[ 0.0431, 0.0510, 0.0588, ..., 0.8039, 0.8196, 0.8510]]]]), 'labels': [0, 1]}
続いて評価用の指標を準備します。
metric = load_metric('accuracy') def compute_metrics(p): return metric.compute(predictions=np.argmax(p.predictions, axis=1), references=p.label_ids)
クラス分類のためのネットワークを準備します。
labels = ['cat', 'dog'] model = ViTForImageClassification.from_pretrained( model_name_or_path, num_labels=len(labels), id2label={str(i): c for i, c in enumerate(labels)}, label2id={c: str(i) for i, c in enumerate(labels)} )
TrainingArgumentsでバッチサイズやエポック数といった学習のパラメータを指定します。また、学習ループは自分では作成せず、transformersのTrainerを利用します。
def collate_fn(batch): return { 'pixel_values': torch.stack([x['pixel_values'] for x in batch]), 'labels': torch.tensor([x['labels'] for x in batch]) } output_dir = '/content/output' !mkdir -p output_dir training_args = TrainingArguments( output_dir=output_dir, per_device_train_batch_size=16, evaluation_strategy='steps', num_train_epochs=4, fp16=torch.cuda.is_available(), save_steps=100, eval_steps=100, logging_steps=10, learning_rate=2e-4, save_total_limit=2, remove_unused_columns=False, push_to_hub=False, report_to='tensorboard', load_best_model_at_end=True, ) trainer = Trainer( model=model, args=training_args, data_collator=collate_fn, compute_metrics=compute_metrics, train_dataset=prepared_ds['train'], eval_dataset=prepared_ds['valid'], tokenizer=feature_extractor, )
以下のコードで学習が実行され、結果が保存されます。
train_results = trainer.train() trainer.save_model() trainer.log_metrics('train', train_results.metrics) trainer.save_metrics('train', train_results.metrics) trainer.save_state()
推論
テストデータに対する精度を確認します。
metrics = trainer.evaluate(prepared_ds['test']) trainer.log_metrics('test', metrics) trainer.save_metrics('test', metrics)
--- 出力 --- ***** Running Evaluation ***** Num examples = 2000 Batch size = 8 [250/250 00:20] ***** test metrics ***** epoch = 4.0 eval_accuracy = 0.987 eval_loss = 0.0446 eval_runtime = 0:00:21.29 eval_samples_per_second = 93.91 eval_steps_per_second = 11.739
完全なアウトサンプルに対しても98.7%の正解率を達成することができています。うまく学習ができたようです。
まとめ
ここまでできれば、あとは実際のタスクに合わせて、学習データ、ネットワーク構造を変更していくことで、様々な領域に応用可能です。ここでは詳解しませんでしたが、学習過程の視覚化等を活用しながら、ご自身の課題にぜひ適用してみてください。