



【入門】Vision Transformerによる画像分類

この記事は、Vision Transformerを用いて画像分類を行うチュートリアルです。Vision Transformerの概要の紹介から始め、実装まで行っていきます。
Vision Transformerとは
Transformerは、もともと自然言語処理分野で提案されたモデルです。機械翻訳での利用を想定されていたことから、入力文章をベクトル化(特徴量化)するEncoderと、特徴量を受け取って文章を生成するDecoderから構成されています。当時多く用いられていたRNNやCNNを超える精度を達成したことから大きな話題となり、その後BERTやGPT-3といった高性能事前学習モデルのベースとして採用されています。
Vision Transformer(ViT)は、TransformerのEncoderを画像の特徴量抽出に利用します。画像処理の特徴量抽出はCNNが主流でしたが、ViTが多くのタスクでより良い精度を達成したため、現在では自然言語処理だけでなく、画像処理分野においても欠かせない存在となっています。
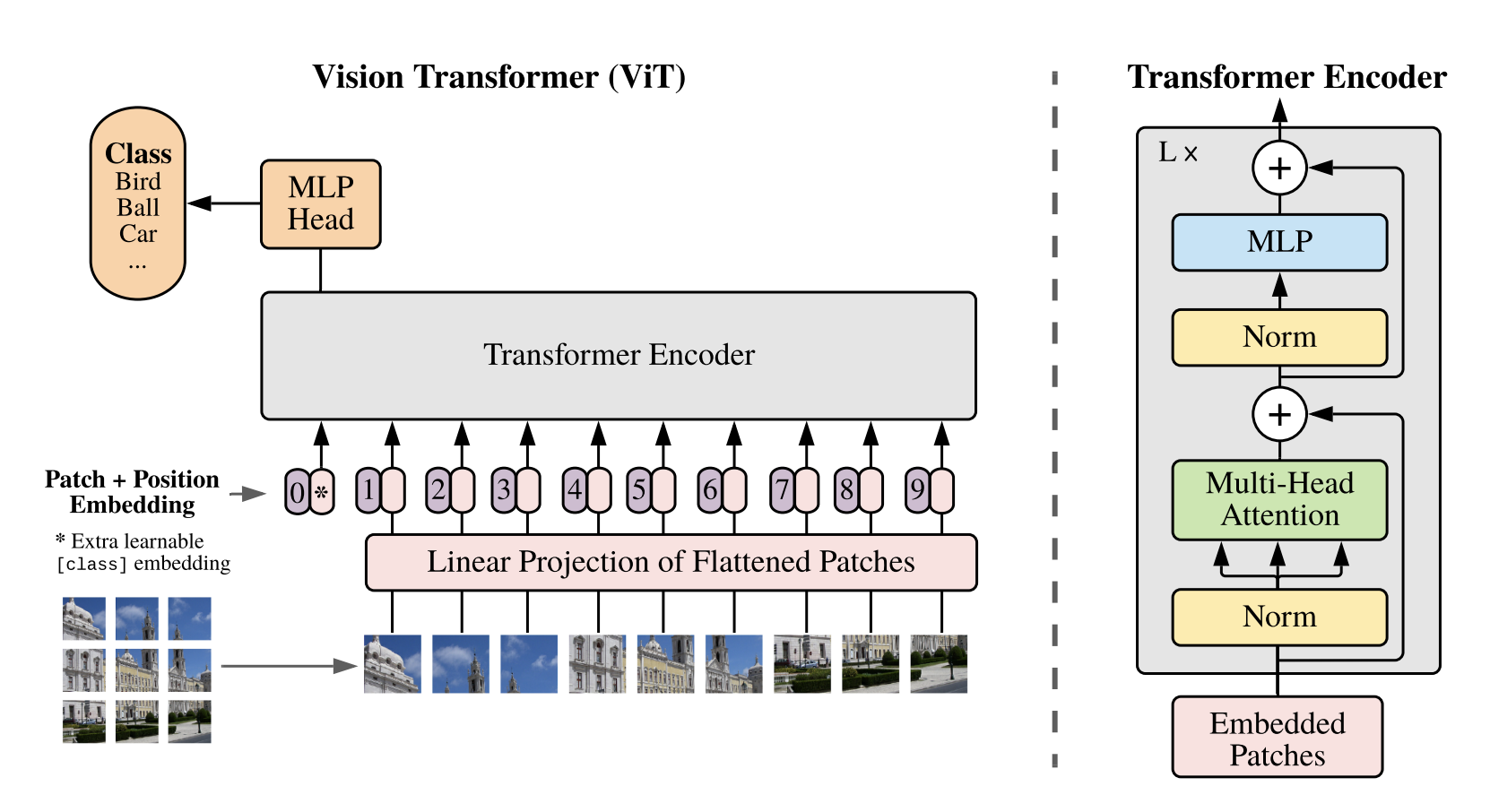
Vision Transformerは、画像をTransformer Encoderに入力できるフォーマットに加工するInput Layer(Linear Projection of Flattened Patches)、特徴量を抽出するTransformer Encoder、そして特徴量を受け取りクラス分類を行うMLP Headからなります。
それぞれの機構の詳細は、以下の参考書籍がとても丁寧で分かりやすいのでオススメです。直感的な説明からスタートし、数式の概要まで段階的に説明されているため、Vision Transformerの全体像をとてもスッキリ理解することができます。

自然言語処理分野での利用例は以下の記事をご覧ください。
画像分類の実装
それでは、Google Colaboratoryを使って分類器を実装していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
事前準備
はじめに、必要となるライブラリのインストール・インポートを行います。
!pip install datasets transformers import random import numpy as np from PIL import ImageDraw, ImageFont, Image from datasets import load_dataset, load_metric from transformers import ViTFeatureExtractor, ViTForImageClassification, TrainingArguments, Trainer import torch
続いて、利用するデータをダウンロードします。今回は、Hugging Faceで公開されている、猫と犬のデータセットを利用します。
ds = load_dataset('Bingsu/Cat_and_Dog')
ダウンロードしたデータはtrainとtestの2つに分割されていますが、さらにtrainからvalidation用のデータを切り分けておきます。
train_val_split = 0.2 split = ds['train'].train_test_split(train_val_split) ds['train'] = split['train'] ds['valid'] = split['test'] # 確認 ds
--- 出力 ---
DatasetDict({
train: Dataset({
features: ['image', 'labels'],
num_rows: 6400
})
test: Dataset({
features: ['image', 'labels'],
num_rows: 2000
})
valid: Dataset({
features: ['image', 'labels'],
num_rows: 1600
})
})
いくつかサンプルを表示してみます。
def show_examples(ds, seed=1234, examples_per_class=2, size=(350, 350)): w, h = size labels = ds['train'].features['labels'].names grid = Image.new('RGB', size=(examples_per_class * w, len(labels) * h)) draw = ImageDraw.Draw(grid) font = ImageFont.truetype("/usr/share/fonts/truetype/liberation/LiberationMono-Bold.ttf", 24) for label_id, label in enumerate(labels): # Filter the dataset by a single label, shuffle it, and grab a few samples ds_slice = ds['train'].filter(lambda ex: ex['labels'] == label_id).shuffle(seed).select(range(examples_per_class)) # Plot this label's examples along a row for i, example in enumerate(ds_slice): image = example['image'] idx = examples_per_class * label_id + i box = (idx % examples_per_class * w, idx // examples_per_class * h) grid.paste(image.resize(size), box=box) draw.text(box, label, (255, 255, 255), font=font) return grid show_examples(ds)

学習
事前学習済みのViTのパラメータをダウンロードします。
model_name_or_path = 'google/vit-base-patch16-224-in21k'
feature_extractor = ViTFeatureExtractor.from_pretrained(model_name_or_path)
上記を用いて画像をベクトル化します。
def transform(example_batch): inputs = feature_extractor([x for x in example_batch['image']], return_tensors='pt') inputs['labels'] = example_batch['labels'] return inputs # ベクトル化 prepared_ds = ds.with_transform(transform) prepared_ds['train'][0:2]
--- 出力 ---
{'pixel_values': tensor([[[[ 0.2157, 0.1765, 0.1608, ..., 0.1373, 0.1451, 0.0980],
[ 0.1216, 0.0745, 0.0667, ..., 0.0667, 0.0588, 0.0039],
[ 0.1373, 0.0980, 0.0824, ..., 0.0824, 0.0353, -0.0353],
...,
[-0.5608, -0.6078, -0.5608, ..., 0.3569, 0.3490, 0.3490],
[-0.5843, -0.6941, -0.7020, ..., 0.3647, 0.3647, 0.3647],
[-0.5608, -0.6627, -0.6706, ..., 0.3647, 0.3725, 0.3725]],
[[ 0.4275, 0.3882, 0.3725, ..., 0.3882, 0.3569, 0.2941],
[ 0.3333, 0.2863, 0.2784, ..., 0.3098, 0.2706, 0.2000],
[ 0.3490, 0.3098, 0.2941, ..., 0.3333, 0.2549, 0.1686],
...,
[-0.4824, -0.5294, -0.4902, ..., 0.6706, 0.6314, 0.6235],
[-0.5373, -0.6549, -0.6627, ..., 0.6784, 0.6471, 0.6392],
[-0.5373, -0.6392, -0.6471, ..., 0.6784, 0.6549, 0.6471]],
[[ 0.2941, 0.2549, 0.2392, ..., 0.3490, 0.3176, 0.2549],
[ 0.2000, 0.1529, 0.1451, ..., 0.2706, 0.2157, 0.1451],
[ 0.2157, 0.1765, 0.1608, ..., 0.2941, 0.1843, 0.0980],
...,
[-0.4431, -0.4980, -0.4510, ..., 0.6078, 0.5922, 0.5922],
[-0.5216, -0.6314, -0.6392, ..., 0.6157, 0.6078, 0.6078],
[-0.5373, -0.6392, -0.6471, ..., 0.6157, 0.6157, 0.6157]]],
[[[ 0.0824, 0.0824, 0.0902, ..., 0.2000, 0.2078, 0.2314],
[ 0.0980, 0.1059, 0.1059, ..., 0.2000, 0.2078, 0.2314],
[ 0.1216, 0.1216, 0.1294, ..., 0.2000, 0.2078, 0.2314],
...,
[ 0.1451, 0.1529, 0.1608, ..., 0.8745, 0.8745, 0.8824],
[ 0.1765, 0.1843, 0.1922, ..., 0.8588, 0.8588, 0.8824],
[ 0.1922, 0.2000, 0.2078, ..., 0.8431, 0.8588, 0.8902]],
[[ 0.0902, 0.0902, 0.0980, ..., 0.2157, 0.2235, 0.2471],
[ 0.1059, 0.1137, 0.1137, ..., 0.2157, 0.2235, 0.2471],
[ 0.1294, 0.1294, 0.1373, ..., 0.2157, 0.2235, 0.2471],
...,
[ 0.1451, 0.1529, 0.1608, ..., 0.8667, 0.8667, 0.8745],
[ 0.1451, 0.1529, 0.1608, ..., 0.8510, 0.8510, 0.8745],
[ 0.1373, 0.1451, 0.1451, ..., 0.8353, 0.8510, 0.8824]],
[[-0.0353, -0.0353, -0.0275, ..., 0.0431, 0.0510, 0.0745],
[-0.0196, -0.0118, -0.0118, ..., 0.0431, 0.0510, 0.0745],
[ 0.0118, 0.0118, 0.0196, ..., 0.0431, 0.0510, 0.0745],
...,
[ 0.0353, 0.0431, 0.0510, ..., 0.8353, 0.8353, 0.8431],
[ 0.0510, 0.0588, 0.0667, ..., 0.8196, 0.8196, 0.8431],
[ 0.0431, 0.0510, 0.0588, ..., 0.8039, 0.8196, 0.8510]]]]), 'labels': [0, 1]}
続いて評価用の指標を準備します。
metric = load_metric('accuracy') def compute_metrics(p): return metric.compute(predictions=np.argmax(p.predictions, axis=1), references=p.label_ids)
クラス分類のためのネットワークを準備します。
labels = ['cat', 'dog'] model = ViTForImageClassification.from_pretrained( model_name_or_path, num_labels=len(labels), id2label={str(i): c for i, c in enumerate(labels)}, label2id={c: str(i) for i, c in enumerate(labels)} )
TrainingArgumentsでバッチサイズやエポック数といった学習のパラメータを指定します。また、学習ループは自分では作成せず、transformersのTrainerを利用します。
def collate_fn(batch): return { 'pixel_values': torch.stack([x['pixel_values'] for x in batch]), 'labels': torch.tensor([x['labels'] for x in batch]) } output_dir = '/content/output' !mkdir -p output_dir training_args = TrainingArguments( output_dir=output_dir, per_device_train_batch_size=16, evaluation_strategy='steps', num_train_epochs=4, fp16=torch.cuda.is_available(), save_steps=100, eval_steps=100, logging_steps=10, learning_rate=2e-4, save_total_limit=2, remove_unused_columns=False, push_to_hub=False, report_to='tensorboard', load_best_model_at_end=True, ) trainer = Trainer( model=model, args=training_args, data_collator=collate_fn, compute_metrics=compute_metrics, train_dataset=prepared_ds['train'], eval_dataset=prepared_ds['valid'], tokenizer=feature_extractor, )
以下のコードで学習が実行され、結果が保存されます。
train_results = trainer.train() trainer.save_model() trainer.log_metrics('train', train_results.metrics) trainer.save_metrics('train', train_results.metrics) trainer.save_state()
推論
テストデータに対する精度を確認します。
metrics = trainer.evaluate(prepared_ds['test']) trainer.log_metrics('test', metrics) trainer.save_metrics('test', metrics)
--- 出力 --- ***** Running Evaluation ***** Num examples = 2000 Batch size = 8 [250/250 00:20] ***** test metrics ***** epoch = 4.0 eval_accuracy = 0.987 eval_loss = 0.0446 eval_runtime = 0:00:21.29 eval_samples_per_second = 93.91 eval_steps_per_second = 11.739
完全なアウトサンプルに対しても98.7%の正解率を達成することができています。うまく学習ができたようです。
まとめ
ここまでできれば、あとは実際のタスクに合わせて、学習データ、ネットワーク構造を変更していくことで、様々な領域に応用可能です。ここでは詳解しませんでしたが、学習過程の視覚化等を活用しながら、ご自身の課題にぜひ適用してみてください。
【入門】BERTによる日本語文書分類

本記事では、ニュース記事をカテゴリに分類するタスクを通して、事前学習済みBERTモデルをファインチューニングする方法を解説していきます。 入力データを変えるだけで任意の日本語文書分類タスクに応用可能です。
英語を対象とした文書分類のチュートリアルは、以下の記事をご覧ください。
環境設定
コードの実行はGoogle Colaboratoryで行います。記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
BERTによる日本語文書分類
公開データであるlivedoorニュースコーパスを用います。 このデータは、各ニュース記事に9種類のジャンルカテゴリのうちのいずれかが振られています。このカテゴリに分類するタスクを対象に、BERTによる文書分類モデルを実装していきます。
データの読込
まずは対象のデータをダウンロードして整形します。
# livedoorニュースコーパスのダウンロード !wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz !tar zxvf ldcc-20140209.tar.gz # 整形結果格納用ファイル作成 !echo -e "filename\tarticle"$(for category in $(basename -a `find ./text -type d` | grep -v text | sort); do echo -n "\t"; echo -n $category; done) > ./text/livedoor.tsv # カテゴリごとに格納 !for filename in `basename -a ./text/dokujo-tsushin/dokujo-tsushin-*`; do echo -n "$filename"; echo -ne "\t"; echo -n `sed -e '1,3d' ./text/dokujo-tsushin/$filename`; echo -e "\t1\t0\t0\t0\t0\t0\t0\t0\t0"; done >> ./text/livedoor.tsv !for filename in `basename -a ./text/it-life-hack/it-life-hack-*`; do echo -n "$filename"; echo -ne "\t"; echo -n `sed -e '1,3d' ./text/it-life-hack/$filename`; echo -e "\t0\t1\t0\t0\t0\t0\t0\t0\t0"; done >> ./text/livedoor.tsv !for filename in `basename -a ./text/kaden-channel/kaden-channel-*`; do echo -n "$filename"; echo -ne "\t"; echo -n `sed -e '1,3d' ./text/kaden-channel/$filename`; echo -e "\t0\t0\t1\t0\t0\t0\t0\t0\t0"; done >> ./text/livedoor.tsv !for filename in `basename -a ./text/livedoor-homme/livedoor-homme-*`; do echo -n "$filename"; echo -ne "\t"; echo -n `sed -e '1,3d' ./text/livedoor-homme/$filename`; echo -e "\t0\t0\t0\t1\t0\t0\t0\t0\t0"; done >> ./text/livedoor.tsv !for filename in `basename -a ./text/movie-enter/movie-enter-*`; do echo -n "$filename"; echo -ne "\t"; echo -n `sed -e '1,3d' ./text/movie-enter/$filename`; echo -e "\t0\t0\t0\t0\t1\t0\t0\t0\t0"; done >> ./text/livedoor.tsv !for filename in `basename -a ./text/peachy/peachy-*`; do echo -n "$filename"; echo -ne "\t"; echo -n `sed -e '1,3d' ./text/peachy/$filename`; echo -e "\t0\t0\t0\t0\t0\t1\t0\t0\t0"; done >> ./text/livedoor.tsv !for filename in `basename -a ./text/smax/smax-*`; do echo -n "$filename"; echo -ne "\t"; echo -n `sed -e '1,3d' ./text/smax/$filename`; echo -e "\t0\t0\t0\t0\t0\t0\t1\t0\t0"; done >> ./text/livedoor.tsv !for filename in `basename -a ./text/sports-watch/sports-watch-*`; do echo -n "$filename"; echo -ne "\t"; echo -n `sed -e '1,3d' ./text/sports-watch/$filename`; echo -e "\t0\t0\t0\t0\t0\t0\t0\t1\t0"; done >> ./text/livedoor.tsv !for filename in `basename -a ./text/topic-news/topic-news-*`; do echo -n "$filename"; echo -ne "\t"; echo -n `sed -e '1,3d' ./text/topic-news/$filename`; echo -e "\t0\t0\t0\t0\t0\t0\t0\t0\t1"; done >> ./text/livedoor.tsv # 確認 !head -10 ./text/livedoor.tsv
--- 出力 --- filename article dokujo-tsushin it-life-hack kaden-channel livedoor-homme movie-enter peachy smax sports-watch topic-news dokujo-tsushin-4778030.txt もうすぐジューン・ブライドと呼ばれる6月。独女の中には自分の式はまだなのに呼ばれてばかり……という「お祝い貧乏」状態の人も多いのではないだろうか? さらに出席回数を重ねていくと、こんなお願いごとをされることも少なくない。 「お願いがあるんだけど……友人代表のスピーチ、やってくれないかな?」 さてそんなとき、独女はどう対応したらいいか? 最近だとインターネット等で検索すれば友人代表スピーチ用の例文サイトがたくさん出てくるので、それらを参考にすれば、無難なものは誰でも作成できる。しかし由利さん(33歳)はネットを参考にして作成したものの「これで本当にいいのか不安でした。一人暮らしなので聞かせて感想をいってくれる人もいないし、かといって他の友人にわざわざ聞かせるのもどうかと思うし……」ということで活用したのが、なんとインターネットの悩み相談サイトに。そこに作成したスピーチ文を掲載し「これで大丈夫か添削してください」とメッセージを送ったというのである。 「一晩で3人位の人が添削してくれましたよ。ちなみに自分以外にもそういう人はたくさんいて、その相談サイトには同じように添削をお願いする投稿がいっぱいありました」(由利さん)。ためしに教えてもらったそのサイトをみてみると、確かに「結婚式のスピーチの添削お願いします」という投稿が1000件を超えるくらいあった。めでたい結婚式の影でこんなネットコミュニティがあったとは知らなかった。 しかし「事前にお願いされるスピーチなら準備ができるしまだいいですよ。一番嫌なのは何といってもサプライズスピーチ!」と語るのは昨年だけで10万以上お祝いにかかったというお祝い貧乏独女の薫さん(35歳) 「私は基本的に人前で話すのが苦手なんですよ。だからいきなり指名されるとしどろもどろになって何もいえなくなる。そうすると自己嫌悪に陥って終わった後でもまったく楽しめなくなりますね」 サプライズスピーチのメリットとしては、準備していない状態なので、フランクな本音をしゃべってもらえるという楽しさがあるようだ。しかしそれも上手に対応できる人ならいいが、苦手な人の場合だと「フランク」ではなく「しどろもどろ」になる危険性大。ちなみにプロの司会者の場合、本当のサプライズではなく式の最中に「のちほどサプライズスピーチとしてご指名させていただきます」という一言があることも多いようだが、薫さん曰く「そんな何分前に言われても無理!」らしい。要は「サプライズを楽しめる」というタイプの人選が大切ということか。 一方「ありきたりじゃつまらないし、ネットで例文を検索している際に『こんな方法もあるのか!』って思って取り入れました」という幸恵さん(30歳)が行ったスピーチは「手紙形式のスピーチ」というもの。 「○○ちゃんへ みたいな感じで新婦の友人にお手紙を書いて読み上げるやり方です。これなら多少フランクな書き方でも大丈夫だし、何より暗記しないで堂々と読み上げることができますよね。読んだものはそのまま友人にあげれば一応記念にもなります」(幸恵さん) なるほど、確かにこれなら読みあげればいいだけなので、人前で話すのが苦手な人でも失敗しないかもしれない。 主役はあくまで新郎新婦ながらも、いざとなると緊張し、内容もあれこれ考えて、こっそりリハーサル……そんな人知れず頑張るスピーチ担当独女たちにも幸あれ(高山惠) 1 0 0 0 0 0 0 0 0 dokujo-tsushin-4778031.txt 携帯電話が普及する以前、恋人への連絡ツールは一般電話が普通だった。恋人と別れたら、手帳に書かれた相手の連絡先を涙ながらに消す。そうすれば、いつしか縁は切れていったものである。しかし現在は、携帯電話がありメールがあり、インターネットを開けば、ブログで相手の晩飯までわかってしまう赤裸々なご時世。切っても切れない元カレとの縁に独女たちは何を思うのであろうか? 「5年前に別れた彼からメールが届いてビックリしました」とは尚美さん(36歳) 「彼の浮気が原因で別れたのですが、現在は独り身らしいことが書いてありました。ただ、私には婚約間近の恋人がいるのでスルー。もし自分に相手がいなかったら、復活愛はあったかも。出会いの機会が少ない独女にとって、いい時代と言えるのでは?」 彼と交際していた当時、尚美さんは実家に住んでいた。もしもメールも携帯電話もない時代だったら、恐らく彼からの連絡はあり得なかっただろう。 一方、美加子さん(38歳)は「一般電話だけの時代のほうが、縁を切りにくかったですよ」という。 「今はメモリ頼りになっている分、電話番号やメールアドレスを消去してしまえばそれまでってところがありますからね。ずるずる引きずろうと思えば引きずれるし、切ろうと思えば切れる。ひと昔前は彼の電話番号を暗記していたものです。受話器を上げたり戻したり……気持ちを断つのが難しかったなぁ」 知恵さん(34歳)も同意見だ。 「情報は自分が情報網を使えば入ってくるが 自分次第でシャットアウトできるもの。だけど私は、“別れた彼と絶縁すべき”とは思っていません。心が癒されるまでの期間は連絡を断ちきり、それ以降はメールを送るなどして、友達関係に戻ることが多いですね」 オール・オア・ナッシングだった以前に比べ、今は縁を切る、友人に戻る、メル友関係を続けるなど、別れた後の関係性を選択できるようになった。未練が残っているうちは辛いが、ツールを上手く使えばメリットを得られることもあるだろう。ただし、落とし穴もある。最後に、律子さん(35歳)のトホホな話を紹介。 「10年前につきあっていた元彼とは、節目節目にメールをしています。“マイミク”で日記にコメントを書き込んだりもするし、年賀状もやりとりする仲。元彼はすでに結婚して子どもが二人いるんですね。最近はすっかり中年太りしてきてマイホームパパって感じ。いい人ではあるけど、すっかり気持ちが冷めた今となっては、なぜ自分があれほど彼に執着していたのか疑問に思えてくる。過去の恋愛の想い出をきれい残したいのなら、知らないほうがいいこともあるかもしれません」 恋の思い出は脳内で美化されるもの。ネットなどで友情関係を続けるのはよいが、同時に淡く切ない恋の思い出は生活感、現実感にまみれてしまうことがあるので、繋ぎすぎには注意したいところ。ま、お互い様ですけどね。(来布十和) 1 0 0 0 0 0 0 0 0 dokujo-tsushin-4782522.txt 「男性はやっぱり、女性の“すっぴん”が大好きなんですかね」と不満そうに話すのは、出版関係で働く香さん(仮名/31歳)。というのも、最近ブログにすっぴん写真を掲載する芸能人が多く、それがニュースになり話題になることがあるからだ。 今年に入ってから、“すっぴん”をブログで披露した芸能人は、小倉優子、安倍なつみ、モーニング娘。の田中れいな、優木まおみ、仲里依紗など、年齢も活躍しているジャンルも様々。私生活をリアルタイムに発信できるブログだからこそ、皆それぞれにリラックスした表情で自分のすっぴんを公開している。ファンにとっては、好きな芸能人の素顔が垣間見れる嬉しいサービスなのだろう。 では、なぜ芸能人のすっぴん顔披露に、彼女は疑問を抱いたのだろうか。「私のひがみだと言う事は重々承知なんですけど、“随分自分に自信があるんだな”って、素直にその美しさを認める事が出来なくて…」と話す香さん。「コメントに“すっぴんでもかわいい!”とか、“メイクしなくても全然OK!”とか賞賛ばかりが並ぶのを見越して、すっぴん写真を公開してるんだなって思うと何か複雑ですね」と付け加えた。 本来ファンサービスである為のすっぴん披露を、「話題を呼ぶ為や、コメントで褒められたいから」行っているのでは? と、独女はつい“ナナメ”に見てしまう様だ。また、メーカーで営業をしている裕美さん(仮名/32歳)は「男性の“すっぴん幻想”には参りますね。そりゃ素顔がキレイならば私だってすっぴんで出社しますよ。でも、毎日少しでもキレイになりたいと一生懸命メイクしている努力も認めて欲しいな」と独女なりの乙女心を明かしてくれた。 「10代や20代前半の若い女の子がすっぴんを載せているのは、“ああ、やっぱり可愛いな”と心から思えるんですけど、私と同年代の人が披露していると自分のすっぴんと比べてゲンナリします」と、美しい芸能人すっぴんを見た後に独女達は人知れず傷ついているのである。 さて、芸能人のすっぴん披露、実際に男性の評判はどうなのだろうか。アパレル企業に勤める雄介さん(仮名/34歳)は「個人的に女性のメイクした顔に魅力を感じないから、すっぴんを見るとすごく可愛いと思う」と賛成派。一方、IT企業で働く徹さん(仮名/28歳)は「人によるけど、何でわざわざブログに載せるんだろうとは思います。本来、女性のすっぴんは大切な相手にだけ見せて欲しいんですよ。“あ、俺だけに見せてくれた”って感じで(笑)」と男性陣の意見もそれぞれの様だ。 今後、ブーム化する予感もあるブログでのすっぴん披露。肯定派と反対派に分かれている様だが、男性が女性の“すっぴん”に特別な想いを持っている事は確か。独女達も、いつかすっぴんを披露するその時の為に、素顔を磨く必要があるのかもしれない。 1 0 0 0 0 0 0 0 0 dokujo-tsushin-4788357.txt ヒップの加齢による変化は「たわむ→下がる→内に流れる」、バストは「そげる→たわむ→外に流れる」という。バストの変化はすでに20代から始まり、20代にして「たわむ」になっている人もいる。そして、元に戻った人は一人もいない。さらに、体の各部位の20代〜50代までの変化をみると、ウエストとお腹の変化が最も大きく、お腹はバストと同じ大きさになっている。 これは、4月に開催されたワコール人間科学研究所の記者発表「からだのエイジング(加齢による体型変化)について一定の法則を発見」での内容の一部。延べ4万人分の経年変化の数値を集計・分析したデータとともに、写真や映像で説明させるので説得力は抜群だ。 現実を直視させられた後に、体型変化の少ない人達の身体的特徴や日常の行動・意識を紹介。その主な内容は、日頃から体を動かし、姿勢をチェック、下着は必ず試着してフィット感を確かめるというもの。そして、パネルディスカッションでは、歩幅の広い歩き方を1年間続ける実験に参加した人が、背筋が伸び、脂肪が落ちたという結果などが紹介されていた。 興味は尽きず、知人たちに内容を伝えるとさまざまな意見や経験が聞けた。 「ずっと計測されているから、体型変化の少ない人はスポーツをしてたのでは?」という疑問もあったが、この回答は、「運動を一生懸命しているというより日常生活を気をつけている印象が強い。そして、ダイエットはあまりしたことがない」とのこと。 「叔母もそんなことを言っていた」と言うのはY子。60歳代の叔母さんが友人たちと温泉旅行に行ったとき、「バストの変化が少ないとほめられた」と喜んでいたので、バストのケア方法を尋ねたそうだ。「叔母はブラジャーを常に着用し、購入時は必ず計測して試着している。一方、友人達は『苦しい』からと家ではブラジャーをしないこともあるらしい」。それを聞いて以来、Y子は下着を買うときには試着はもちろん、計ってもらうようにしている。 「私も歩いてやせた」と話すのは、腰痛に悩まされていたK子。医師に筋力の低下を指摘されて、駅までの自転車を止めて、片道30分の道のりを毎日往復歩くことに。筋力をつけるために始めたことで体全体が引き締まり、結果として減量にも成功した。 「でも、スポーツすればしまるよね」と言うA子は、不摂生がたたって気になり始めたウエスト回りをスポーツクラブに通って改善。ジーンズがワンサイズ小さくなったと喜んでいる。 パネルディスカッションでは、「加齢は一方通行だが、現状維持は可能」「アンチエイジングは医学界でも注目だが、身体的な美しさの維持と健康維持の関係性は表裏一体のはず」とも言われていた。それならば、体型変化という加齢への抵抗はあきらめないほうが得策だ。 杉本彩が言っていたっけ、「若いころに戻りたいとか、若く見られたい、とは思わない。今の自分がどう美しくあるかを追求したい」って。(オフィスエムツー/オオノマキ) 詳細はコチラ 1 0 0 0 0 0 0 0 0 dokujo-tsushin-4788362.txt 6月から支給される子ども手当だが、当初は子ども一人当たり月額2万6000円が支給されるはずだった。ところが、初年度は半額支給となり、さらに2011年度以降も子ども一人当たり月額2万6000円の支給は見送られそうだ。 先日は在日外国人男性がタイで養子縁組をしたと称する554人分の子ども手当を申請しようとして市から却下されたニュースが報じられたが、悪い人間がちょっと考えれば簡単に不正ができるような不備だらけの子ども手当って、一体どうなっているの? と支給されない側の独女からも疑問の声が聞こえる。 現在独身の由梨さんは、「私立の幼稚園にベンツで送り迎えをしているような家にどうして子ども手当が必要なの?」と一律支給にはどうしても納得できないと訴える。 「子ども手当はフランスの真似をしたと聞いていますけど、フランスでは子ども手当は“家族手当”といい所得制限はありません。でも家族手当が貰えるのは第2子からで20歳まで支給され、3人目からは割増の家族手当が貰えるそうです。子ども手当が少子化対策を目的にしたものなら、フランスのように2人目から手当を出すべきではないですか?」 一律支給だけをフランスの真似をするのはおかしいという。 それに少子化対策と言われながら、子ども手当を当てにして出産しようという声は聞かない。 「政権交代をすればなくなるかもしれない手当を期待して、今から結婚してもすぐに妊娠するとは限らないし、無事出産の暁には子ども手当は廃止されているかもしれないですよね」 その可能性もなきにしもあらずだ。 子ども手当の使い道について子どものいる主婦に聞くと、将来の教育費のために貯蓄に回すという人が多かった。それについても、 「子どもが欲しくてもできなかった家庭がその費用を負担するのはとてもお気の毒な気がします。それに本当に子どものために使われるのならいいのですが、親がギャンブルに使ったり、親の遊興費に使われるために私たちの税金を使ってほしくないですね」と由梨さん。 バツイチの綾さんは、「子どものいない夫婦も、独身も、働いて税金を納めることで次世代を担う子どもたちを育てることに貢献する。それが子ども手当だと思っていましたが、子どものいる家庭にいくはずのお金がどんどん減らされ、それがどこへ行くのかわからないし、申請書の偽装で、私たちの税金が外国人の子どものところに行くのは納得ができません」と制度の不備に怒っている。 「所得制限限度額のある児童手当を増額するべきなのに、全世帯平等に子ども手当てをばらまくのは選挙のための人気とりしか思えません。これで政権が変われば子ども手当はどうなるのか?」 もしこのまま子ども手当をばら撒かれれば、将来子ども手当をもらった子どもたちが増税という形でつけを払わされるのではと綾さんは心配もしていたが、財政難を地方に泣きつく地方負担に地方自治体から反発の声が上がっている。 一体どうなってしまうのか? 今後の子ども手当をしっかり見守りたい。 ところで今回、子どものいない独身の人たちに意見を聞いたのだが、「子ども手当」は自分たちには関係ないのでよく分からないという独女が多かった。 介護保険についても、実際自分が親の介護をする立場になって初めて内容かを知ったという人が多いのだが、どんな制度も国会を通過して施行されれば私たちの納めた税金が使われるのだ。知ることも文句を言うことだって私たちの権利だと思う。無関心でいるよりはよほどいいのではないだろうか。(オフィスエムツー/佐枝せつこ) 1 0 0 0 0 0 0 0 0 dokujo-tsushin-4788373.txt 書店で偶然『うさぎのくれたバレエシューズ』(小峰書店 安房直子/著、南塚直子/イラスト)という絵本を見つけたモトコさん(27歳 薬剤師)は、懐かしさと嬉しさで胸がいっぱいになった。 「バレエを習っていた私は、この絵本を読むと励まされる気がして、小学校の図書室で何度も読みました。どうしても欲しくて母と近所の書店を探したんですけど見つけられなくて…」とモトコさん。優しいピンク色が印象的な『うさぎのくれたバレエシューズ』は、表紙が見えるように今モトコさんの部屋に飾られている。 広告代理店に勤務するマサエさん(40歳)のお気に入りは『100万回生きた猫』(講談社 佐野洋子/著)。小学生の頃、図書館で頻繁に借りていた本だ。「6年生になって、周りの子が厚い小説を読んでいるのに、私は相変わらず『100万回生きた猫』を読んでいました。母から『もっとちゃんとした本を読みなさい』って注意されたこともありましたが…。今なら、母に『これは特別な本よ』と言えます。当時も子どもなりに絵やストーリーから、いろいろなことを感じていたんでしょうね」(マサエさん) 絵本の穏やかストーリーや柔らかな絵に癒される女性は多い。周囲の女性たちに聞いてみると、大人になってから購入した絵本は、新しく出版されたものより「子ども時代に読んだ本」や「特別な思い出がある本」が多いようだ。美しい絵が印象的な『ごんぎつね』(偕成社 新美南吉/著、黒井健/イラスト)や『てぶくろを買いに』(偕成社 新美南吉/著、黒井健/イラスト)、ちょっとクセのあるサンタが登場する『さむがりやのサンタ』(福音館書店 レイモンド・ブリッグズ/著、すがはらひろくに/翻訳)なども人気が高い。懐かしい絵本を開くとき、忘れていた子ども時代の「感性」がふと蘇えるのだろう。 大人になってから絵本の魅力を発見した人もいる。子どもの頃、絵本にはほとんど感心がなかったナオミさん(36歳 メーカー勤務)が絵本に惹かれたきっかけは、友人のお子さんにプレゼントした『ぐりとぐら』(福音館書店 なかがわりえこ/著、おおむらゆりこ/イラスト)。 「絵も可愛いし、大きなカステラは美味しそうだし、何より『ぐりぐら ぐりぐら』という言い回しに、はまっちゃいました。『ぐりぐら ぐりぐら』ってつぶやくと、ちょっとくらい嫌なことがあっても、どうでもよくなっちゃいます(笑)」(ナオミさん) 読んで癒される絵本だが、最近は、自分で絵本を描いてみたいと思う女性も増えているらしい。大阪で「大人のための絵本講座」を開いているイラストレーターのおおさわまきさん(星未来工房)に、絵本を描く魅力について伺った。 「絵本は目でイメージしその世界に入り込める奥深いものです。文章と絵で構成されているので、いろいろな見方ができるし、たくさんのことを伝えられるのが魅力です。絵本講座を受講した生徒さんたちは、一度絵本を仕上げると『もっと作りたい、楽しい!』と目を輝かせますよ。絵本作りは、年齢関係なく誰にでもできる癒しの世界だと思っています」 絵本作りのコツについてお聞きすると「私が絵本作りの勉強し始めた頃、先生から『難しく考えたらダメだよ』と繰り返し言われました。難しいと思うとどんどん描けなくなるんですよね。だから、自分も含めて、難しくないことからはじめていこうと強く思いました。そして、何よりも童心に戻ることが大切です。子どもは何でも素直に楽しむでしょう。大人も『恥』とか『かっこよく』とか考えないで、遊び感覚で自然に絵本作りに取組むことが大切です」(おおさわさん)。 子どものように素直に描けるようになると、考え方も自然と柔軟になってくるはず。大人という枠組みや常識という枠組みから離れて、自由に空想し、自由に描くことで、心が癒されていくのだろう。 最後に、おおさわさんにお勧め絵本を紹介していただいた。「『ちきゅうになった少年』(フレーバル館 みやざきひろかず/作・絵)が大好きです。毎日忙しくストレスをかかえる人にとって、人間でないものに生まれ変わってみたいという願望をおもしろく表現していると思います。疲れたとき、辛いことがあったとき、逃避したいとき、心を休める1冊です。また、水彩画は脳や心を緩め、癒してくれる画材なのでとてもお勧めですよ」(おおさわさん) 絵本を読んでみたいが、どんな本が自分に向いているかわからないという人は、まず図書館の絵本コーナーへ行って見るといい。何冊も手に取る間に、自分の好みの絵やストーリーに出合えるはず。読み終えたとき気持ちが前向きになれる本がいい。(オフィスエムツー/神田はるひ) ・取材協力 -星未来工房 おおさわまき 1 0 0 0 0 0 0 0 0 dokujo-tsushin-4788374.txt 昨年の秋、希望の職種に転職したカナコさん(30歳/ 商社勤務)。やりがいのある仕事を得て充実した毎日を送れるだろうと思っていたのだが、思いがけない問題に悩んでいる。 「女性社員は休憩室で一緒にお昼ご飯を食べるのですが、そのときの話題が社内の噂話や悪口ばかりで驚いています。社内不倫の話から男性社員の品定め、他の支店の女性社員の悪口など、毎日毎日よくネタが尽きないものだと感心するくらい。うんざりしています」(カナコさん) もちろん女性でも社外に食べに行く人もいるが、後で先輩女性から嫌味を言われたり、根も葉もない噂を立てられたりということも…。「お昼休みが近づくと憂鬱になります。30代になって、お昼休みのことで悩むとは思ってもいませんでした」(カナコさん) 忙しい一日の中で、唯一休息できるのがお昼休みという人も多いはず。気の合う仲間と美味しいお弁当やランチサービスを食べ、楽しい会話ができたなら、午後の仕事も頑張れるだろう。でも、思い通りにならないことも多い。 ムツミさん(29歳 医療関連)の再就職先は、女性社員はムツミさんを入れて4人だけ。長い間一緒に働いている女性3人の結束が固いのが問題だ。「休憩室が一箇所なので、お昼は一緒に食べるのですが、先輩3人の仲が良すぎて、私は話題に入れません。最初は黙って話を聞いていたのですが、だんだん居づらくなって…。今は食べ終わったらすぐに机に戻って雑誌を読んでいます」(ムツミさん) この会社では、新しく女性社員を入れても短期間で辞めてしまうことが多いという。1人でお昼休みを過ごせるムツミさんを見て「長く勤めてもらえるかもしれない」と上司は期待しているらしいが…。 派遣社員のエリさん(27歳)は、以前は「1人でお昼休みを過ごすのは辛い」と感じていたが、派遣社員になり複数の会社を経験するうちに「1人の気楽さ」に目覚めたという。 「たまに同じ課の人と社外に食べに行くこともありますけど、雑誌を見ながら自分の机で食べることが多いですね。後はメールを書いたりして過ごしています。今の派遣先は、女性同士の束縛がないのでとても気楽です(笑)」(エリさん) エリさんの話によると、お昼休みに皆で『昼ドラ』を見る会社もあるという。ドラマ好きのエリさんはそれなりに楽しかったが、中には、先に席をたって給湯室で時間をつぶしている女性社員もいたそうだ。 「会社によってお昼休みの過ごし方はだいぶ違います。女性社員は必ず一緒に食べるという暗黙のルールがある会社では、それぞれ黙って携帯を見ながら食べていましたよ。7〜8人いるのにシーンとしているんです。これはかなり辛かったです。あとは、一番年上の女性社員の方が話好きで、お昼休みの間中は、ひたすら皆で彼女の話を聞かなくてはいけないという会社もありました」(エリさん) 小学生の頃、遠足の前になると教室のあちこちで「○○ちゃん、一緒にお昼を食べようね」という約束が取り交わされていた。いつも私は、ドキドキしながら友だちのOKを待っていたように思う。先生は内気な子を心配して、リーダー格の生徒に「お昼には○○ちゃんも誘ってあげてね」などと根回しをしたり、「今回は皆で食べましょう」と声をかけたり…。 高校に入学したばかりの姪は「すぐにお昼を食べる友達ができて良かった」と嬉しそうに話してくれた。幾つになっても、お昼休みを誰とどこでどう過ごすかは大きな問題なのだ。 余談になるが、禁煙のオフィスが増えている昨今は、喫煙派のお昼休みの過ごし方も変わってきている。知人の勤め先では、今春からビル内に喫煙できる場所が無くなったため、仕方なく最寄り駅の喫煙所まで煙草を吸いに行くという。 「タバコを吸うためだけに、喫煙できるカフェに毎日行くわけにもいかないですし、室内で吸っていると洋服に煙草の臭いが染み付くので、今は駅の屋外の喫煙場所がありがたいです」と知人。雨の日の昼休みは、駅までの道のりを考えると憂鬱になるらしい。(オフィスエムツー/神田はるひ) 1 0 0 0 0 0 0 0 0 dokujo-tsushin-4788388.txt 「彼の収入が少ないから私も働かなければならないし、それを思うと結婚はもう少し先でもいいかな」と結婚を躊躇する独女がいる。彼女は彼の収入だけで暮らせるのなら、仕事は今すぐにでも辞めたいらしい。つまり専業主婦志望なのだが、彼の年収を聞いて首を傾げた。 この金額で本当に生活ができないのだろうか? かつて専業主婦が多かった時代、主婦の働き先はなく、今月もかつかつだとこぼしながらも、夫の稼ぎだけで暮らしていた家庭が多かった。しかし今は不況で夫の収入が減ったとはいえ、外食、ブランド品購入、安いツアーとはいえ海外旅行にも行っている。食べるだけで精一杯の昔に比べれば、ものすごく贅沢ではないだろうか? 成人した二人の子供がいる専業主婦の紀世子さん(56 歳)は、「今は専業主婦がセレブのように言われますけど、私はブランド品も持ったことがなければ、家族で海外旅行にも行ったことがないんですよ。夫の収入だけで充分とはいいませんけど、贅沢さえしなければ毎月何とかなったものです」という。 子供が小学校に入学すると、塾の費用を捻出するためにパートに行く主婦もいたが、紀世子さんの家庭はご主人の方針で塾には一切通わせず、兄は水泳、妹は習字と、週に一度の習い事に通わせただけだそうだ。 「私立中学受験で塾に通わせているご家庭は大変そうでしたよ。塾の費用が一か月5万円と聞いてびっくりしました。そこまでして私立に行かせて、その後も莫大な教育費がかかるのに大変だとあと思いました」 紀世子さんの長女は私立の女子大学に入学したが、中学・高校から持ち上がりできた友人には小学校の時の同級生もいる。「中高一貫教育の必要性はよく分かりませんが、結局同じ大学に通うなら何も高い教育費を払って中学から行く必要がないのでは?」これは私の考えですがと紀世子さん。 仕事に生きがいを持ち自分のために働いている主婦もいるが、家族で海外旅行に行ったり外食をしたり、生活水準を上げるために働いている主婦もいる。自分の稼ぎでブランド品を買う主婦もいるが、やはり主婦の働く目的の大半は子供の教育費の捻出だろう。 教育費は、子どもが生まれてから大学卒業まで一般に1000万円以上もかかると言われている。幼稚園から大学まで私立なら2000万円は超す。となれば教育費のために働かなければならないわけだが、幼稚園から私立にやるのはどうしてなのだろうか? 「子供に誇れる学歴をつけてやりたいからです」 私立幼稚園入学を目指している幼児の母親、A子さんはいうが、誇れるとはすなわち母親の価値観で、他の子と比べて自分の子供は特別なことをさせているという母親自身の見栄もあるのかもしれない。 子供を私立幼稚園に行かせたり、ブランドの服を着せたりすれば、母親もそれに見合う服装やバックを身につけなければならなくなる。 そういう生活がしたいけれど、夫の収入でできなければ、我慢すればいい。我慢できなければ働けばいい。けれど、働く目的が子供のためであるなら、なにが本当に子供にとって幸せなのかを考えるべきではないだろうか。 彼の収入が少ないとか夫の稼ぎが足りないとこぼす女性たちの胸の内は、なくてもいいものをあえて欲しがる暮らしを求めている気がする。 人と競い合うことで向上することもあるが、家庭における幸せとは決して比べたり競い合うものではないと思う。 前述の紀世子さんだが、学校から帰ってくるといつも「お帰りなさい」と待っていてくれるお母さんがいてくれて嬉しかったと成人した娘さんから言われたそうだ。 「能力も資格もないので家にいて節約しているだけの生活でしたが、子供と過ごせた時間は楽しかったですよ」 養ってくれた夫にも感謝しているという紀世子さんの言葉がものすごく新鮮に聞こえた。 働いて得るものもあるが、節約して作った時間で得るものもある。彼の収入が少ないと思うのなら、やりくりという算段を覚えることをしてみてはどうだろうか? 結婚はいろいろ頭で考えているより、実際生活をしてみればなるようになるものです。(オフィスエムツー/佐枝せつこ) 1 0 0 0 0 0 0 0 0 dokujo-tsushin-4791665.txt これからの季節、お肌の天敵と言えば“紫外線”。マーケティング会社トレンダーズ株式会社が、20、30代女性に「UVケア」に関する意識調査を実施した所、99%の人が「外出するとき、UVケアが必要」と回答。もはや、UVケアは女性にとって常識となっている事が分かります。アンチエイジングを目指す独女にとってもUVケアを見逃す事はできません。 「紫外線が気になるのは、1日のうちどんなシーンですか?」という質問に対しては、最も多く挙がったのが「通勤時」で、半数以上が回答。「紫外線が気になる時間帯」については、最も多かったのが、「12時〜15時」で83%。次いで「9時〜12時」が67%、「〜9時」(43%)と、働く女性がUVケアを意識するのは、朝の時間帯だという事が分かります。 実際、「朝にUVケア」をしているのが87%にのぼり、「朝の通勤時間が一番紫外線を浴びる。(36歳・不動産広告デザイン)」「通勤時に日やけをしてしまうので欠かさずしている。(29歳・商社経理)」と、日焼けやシミを防ぐ為には“朝のUV”ケアがマストの様です。 具体的なUVケアの方法としては、最も多かったのが「日やけ止めを塗る」で、全体の92%が回答。次いで、「日傘」(59%)、「帽子」(39%)と続いています。手軽に塗れてしっかりUV対策ができる「日やけ止め」が女性の支持を集めました。 「日やけ止めは、1日に何回塗り直しますか?」という質問に対しては、平均で「0.94回」と、およそ1日1回塗り直していることが明らかに。汗をたくさんかいた時はもちろん、知らず知らずのうちに効果が低下しているのが不安で、つい何度も塗りなおしてしまいますが、日々忙しい、独女にとってはその時間すら惜しい所。また、肌への負担も気になります。 また、「日やけ止めに求めるものは何ですか?」という質問によると、「日やけ止め効果」(93%)という日やけ止めにとって、マストの効果となる回答に次いで「肌への負担の少なさ」(88%)、「ベタつかないこと」(73%)と意見が多く、ただUVケアが出来る事だけでは無く、“お肌に優しいこと”が重要になってくる様です。 そんな、UVケアと肌への優しさ両方を大切にしたい女性にオススメしたいのが、新しくなった日やけ止め「アネッサ」。地上のあらゆる紫外線をカットしてくれるだけでは無く、今までの日やけ止めにありがちだった、べたつきや白浮きが無く、サラサラの使い心地です。最近、紫外線をジリジリとお肌に感じながらも日やけ止めを使うことで「肌の負担になるのは嫌」と、使い損ねていた独女の皆さんは、ぜひ試してみては?詳しくはこちら ・アネッサ - 資生堂 1 0 0 0 0 0 0 0 0
続いて、データフレームとして読込み、学習データ、検証データ、評価データに分割しておきます。
import pandas as pd from sklearn.model_selection import train_test_split from tabulate import tabulate # データの読込 df = pd.read_csv('./text/livedoor.tsv', sep='\t') # データの分割 categories = ['dokujo-tsushin', 'it-life-hack', 'kaden-channel', 'livedoor-homme', 'movie-enter', 'peachy', 'smax', 'sports-watch', 'topic-news'] train, valid_test = train_test_split(df, test_size=0.2, shuffle=True, random_state=123, stratify=df[categories]) valid, test = train_test_split(valid_test, test_size=0.5, shuffle=True, random_state=123, stratify=valid_test[categories]) train.reset_index(drop=True, inplace=True) valid.reset_index(drop=True, inplace=True) test.reset_index(drop=True, inplace=True) # 事例数の確認 table = [['train'] + [train[category].sum() for category in categories], ['valid'] + [valid[category].sum() for category in categories], ['test'] + [test[category].sum() for category in categories]] headers = ['data'] + categories print(tabulate(table, headers, tablefmt='grid'))
--- 出力 --- +--------+------------------+----------------+-----------------+------------------+---------------+----------+--------+----------------+--------------+ | data | dokujo-tsushin | it-life-hack | kaden-channel | livedoor-homme | movie-enter | peachy | smax | sports-watch | topic-news | +========+==================+================+=================+==================+===============+==========+========+================+==============+ | train | 696 | 696 | 691 | 409 | 696 | 673 | 696 | 720 | 616 | +--------+------------------+----------------+-----------------+------------------+---------------+----------+--------+----------------+--------------+ | valid | 87 | 87 | 87 | 51 | 87 | 84 | 87 | 90 | 77 | +--------+------------------+----------------+-----------------+------------------+---------------+----------+--------+----------------+--------------+ | test | 87 | 87 | 86 | 51 | 87 | 85 | 87 | 90 | 77 | +--------+------------------+----------------+-----------------+------------------+---------------+----------+--------+----------------+--------------+
学習の準備
BERTモデルを利用するためにtransformersライブラリをインストールしておきます。transformersを通じて、BERT以外にも多くの事前学習済みモデルを短いコードで非常に簡単に利用することができます。
!pip install transformers["ja"]
モデルの学習と評価に必要なライブラリをインポートします。
import numpy as np from transformers import AutoModel, AutoTokenizer import torch from torch.utils.data import Dataset, DataLoader from torch import optim, cuda import time from matplotlib import pyplot as plt
続いて、今回利用する日本語事前学習済みBERTモデルを指定します。 transformersで公開されている東北大学の乾・鈴木研究室のモデルのうち、bert-base-japanese-whole-word-maskingを試すことにします。
# 事前学習済みモデルの指定 pretrained = 'cl-tohoku/bert-base-japanese-whole-word-masking'
次に、データをモデルに投入可能な形に整形します。
まずは、PyTorchでよく利用される、特徴ベクトルとラベルベクトルを合わせて保持するDatasetを作成するためのクラスを定義します。
このクラスにtokenizerを渡すことで、入力テキストに形態素解析などの処理を行い、指定した最大系列長までパディングした上で単語IDに変換する処理を実現できるようにしておきます。
とはいえ、BERT用にすべての処理が書かれたtokenizerそのものは、のちほどtranformersを通じて取得するため、クラス内で必要なものはtokenizerに渡す処理と結果を受け取る処理のみです。
# Datasetの定義 class NewsDataset(Dataset): def __init__(self, X, y, tokenizer, max_len): self.X = X self.y = y self.tokenizer = tokenizer self.max_len = max_len def __len__(self): # len(Dataset)で返す値を指定 return len(self.y) def __getitem__(self, index): # Dataset[index]で返す値を指定 text = self.X[index] inputs = self.tokenizer.encode_plus( text, add_special_tokens=True, max_length=self.max_len, truncation=True, padding='max_length' ) ids = inputs['input_ids'] mask = inputs['attention_mask'] return { 'ids': torch.LongTensor(ids), 'mask': torch.LongTensor(mask), 'labels': torch.Tensor(self.y[index]) }
上記を用いてDatasetを作成します。
引数の一つであるMAX_LENは最大系列長を表し、これより長い文は切られ、短い文はパディングされることによりこの長さに揃えられます。本来BERTでは512まで指定可能ですが、今回はメモリの制約から128を指定しています。
# 最大系列長の指定 MAX_LEN = 128 # tokenizerの取得 tokenizer = AutoTokenizer.from_pretrained(pretrained) # Datasetの作成 dataset_train = NewsDataset(train['article'], train[categories].values, tokenizer, MAX_LEN) dataset_valid = NewsDataset(valid['article'], valid[categories].values, tokenizer, MAX_LEN) dataset_test = NewsDataset(test['article'], test[categories].values, tokenizer, MAX_LEN) for var in dataset_train[0]: print(f'{var}: {dataset_train[0][var]}')
--- 出力 ---
ids: tensor([ 2, 5563, 3826, 7, 9, 6, 5233, 2110, 10, 4621,
49, 1197, 64, 14, 10266, 7, 3441, 1876, 26, 62,
8, 70, 825, 6, 9749, 70, 3826, 7, 1876, 15,
16, 7719, 1549, 4621, 11, 1800, 15, 16, 6629, 45,
28, 392, 8, 5880, 7, 1800, 34, 1559, 14, 31,
947, 6, 8806, 16, 6629, 13, 1755, 3002, 4621, 11,
1942, 7, 9626, 392, 124, 7, 139, 8, 25035, 4021,
489, 7446, 143, 16430, 13901, 1993, 49, 8365, 2496, 12084,
40, 5880, 1800, 9749, 1876, 15, 16, 7719, 1549, 4621,
14, 6, 5563, 3826, 5, 4314, 5233, 2110, 10, 120,
4118, 7, 1876, 26, 20, 16, 33, 344, 9, 6,
10843, 329, 11426, 11, 1943, 10, 72, 7, 10485, 7,
1876, 26, 62, 26813, 7004, 11, 20718, 3])
mask: tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1])
labels: tensor([0., 1., 0., 0., 0., 0., 0., 0., 0.])
1文目の文の情報を出力しています。
入力文字列がidsとしてID系列に変換されていることが確認できます。BERTでは、変換の過程で元の文の文頭と文末に特殊区切り文字である[CLS]と[SEP]がそれぞれ挿入されるため、それらも2と3として系列に含まれています。
正解ラベルもlabelsとしてone-hot形式で保持しています。
また、パディングの位置を表すmaskも合わせて保持し、学習時にidsと一緒にモデルに渡せるようにしておきます。
続いて、ネットワークを定義します。
transfomersを用いることで、BERT部分はまるごとAutoModelで表現可能です。その後、分類タスクに対応するため、BERTの出力ベクトルを受け取るドロップアウトと全結合層を定義すれば完成です。
# BERT分類モデルの定義 class BERTClass(torch.nn.Module): def __init__(self, pretrained, drop_rate, otuput_size): super().__init__() self.bert = AutoModel.from_pretrained(pretrained) self.drop = torch.nn.Dropout(drop_rate) self.fc = torch.nn.Linear(768, otuput_size) # BERTの出力に合わせて768次元を指定 def forward(self, ids, mask): _, out = self.bert(ids, attention_mask=mask, return_dict=False) out = self.fc(self.drop(out)) return out
BERT分類モデルの学習
ここまでで、Datasetとネットワークが準備できたため、あとは普段通りの学習ループを作成します。
ここでは一連の流れをtrain_model関数として定義しています。
登場する構成要素の意味については、【言語処理100本ノック 2020】第8章: ニューラルネットの記事の中で、問題の流れに沿って解説していますので、そちらをご参照ください。
def calculate_loss_and_accuracy(model, loader, device, criterion=None): """ 損失・正解率を計算""" model.eval() loss = 0.0 total = 0 correct = 0 with torch.no_grad(): for data in loader: # デバイスの指定 ids = data['ids'].to(device) mask = data['mask'].to(device) labels = data['labels'].to(device) # 順伝播 outputs = model(ids, mask) # 損失計算 if criterion != None: loss += criterion(outputs, labels).item() # 正解率計算 pred = torch.argmax(outputs, dim=-1).cpu().numpy() # バッチサイズの長さの予測ラベル配列 labels = torch.argmax(labels, dim=-1).cpu().numpy() # バッチサイズの長さの正解ラベル配列 total += len(labels) correct += (pred == labels).sum().item() return loss / len(loader), correct / total def train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, num_epochs, device=None): """モデルの学習を実行し、損失・正解率のログを返す""" # デバイスの指定 model.to(device) # dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True) dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False) # 学習 log_train = [] log_valid = [] for epoch in range(num_epochs): # 開始時刻の記録 s_time = time.time() # 訓練モードに設定 model.train() for data in dataloader_train: # デバイスの指定 ids = data['ids'].to(device) mask = data['mask'].to(device) labels = data['labels'].to(device) # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 outputs = model(ids, mask) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, dataloader_train, device, criterion=criterion) loss_valid, acc_valid = calculate_loss_and_accuracy(model, dataloader_valid, device, criterion=criterion) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # 終了時刻の記録 e_time = time.time() # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}, {(e_time - s_time):.4f}sec') return {'train': log_train, 'valid': log_valid}
パラメータを設定して、ファインチューニングを実行します。
# パラメータの設定 DROP_RATE = 0.4 OUTPUT_SIZE = 9 BATCH_SIZE = 16 NUM_EPOCHS = 4 LEARNING_RATE = 2e-5 # モデルの定義 model = BERTClass(pretrained, DROP_RATE, OUTPUT_SIZE) # 損失関数の定義 criterion = torch.nn.BCEWithLogitsLoss() # オプティマイザの定義 optimizer = torch.optim.AdamW(params=model.parameters(), lr=LEARNING_RATE) # デバイスの指定 device = 'cuda' if cuda.is_available() else 'cpu' # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, device=device)
--- 出力 --- epoch: 1, loss_train: 0.0976, accuracy_train: 0.8978, loss_valid: 0.1122, accuracy_valid: 0.8575, 405.6795sec epoch: 2, loss_train: 0.0468, accuracy_train: 0.9622, loss_valid: 0.0802, accuracy_valid: 0.8942, 405.0562sec epoch: 3, loss_train: 0.0264, accuracy_train: 0.9822, loss_valid: 0.0688, accuracy_valid: 0.9077, 407.3759sec epoch: 4, loss_train: 0.0164, accuracy_train: 0.9907, loss_valid: 0.0708, accuracy_valid: 0.9050, 407.4937sec
結果を確認します。
# ログの可視化 x_axis = [x for x in range(1, len(log['train']) + 1)] fig, ax = plt.subplots(1, 2, figsize=(15, 5)) ax[0].plot(x_axis, np.array(log['train']).T[0], label='train') ax[0].plot(x_axis, np.array(log['valid']).T[0], label='valid') ax[0].set_xlabel('epoch') ax[0].set_ylabel('loss') ax[0].legend() ax[1].plot(x_axis, np.array(log['train']).T[1], label='train') ax[1].plot(x_axis, np.array(log['valid']).T[1], label='valid') ax[1].set_xlabel('epoch') ax[1].set_ylabel('accuracy') ax[1].legend() plt.show()

# 正解率の算出 dataloader_train = DataLoader(dataset_train, batch_size=1, shuffle=False) dataloader_valid = DataLoader(dataset_valid, batch_size=1, shuffle=False) dataloader_test = DataLoader(dataset_test, batch_size=1, shuffle=False) print(f'正解率(学習データ):{calculate_loss_and_accuracy(model, dataloader_train, device)[1]:.3f}') print(f'正解率(検証データ):{calculate_loss_and_accuracy(model, dataloader_valid, device)[1]:.3f}') print(f'正解率(評価データ):{calculate_loss_and_accuracy(model, dataloader_test, device)[1]:.3f}')
--- 出力 --- 正解率(学習データ):0.991 正解率(検証データ):0.905 正解率(評価データ):0.904
評価データで90%ほどの正解率でした。
通常はさらに、検証データの精度を確認しながらBERTの層ごとの重み固定有無や学習率等のパラメータを調整することが多いと思います。 今回はパラメータ決め打ちでしたが比較的高精度であり、事前学習の強力さが表れた結果となりました。
理解を深めるためのオススメ教材


新納 浩幸 インプレス 2021年03月18日頃
参考文献
transformers BERT(公式) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)(原論文)
【言語処理100本ノック 2020】第9章: RNNとCNN

自然言語処理の問題集として有名な言語処理100本ノックの2020年版の解答例です。 この記事では、以下の第1章から第10章のうち、「第9章: RNNとCNN」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNNとCNN
- 第10章: 機械翻訳
環境設定
コードの実行はGoogle Colaboratoryで行います。 以降の解答の実行結果をすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
第9章: RNN, CNN
80. ID番号への変換
問題51で構築した学習データ中の単語にユニークなID番号を付与したい.学習データ中で最も頻出する単語に
,2番目に頻出する単語に
,……といった方法で,学習データ中で2回以上出現する単語にID番号を付与せよ.そして,与えられた単語列に対して,ID番号の列を返す関数を実装せよ.ただし,出現頻度が2回未満の単語のID番号はすべて
とせよ.
まずは、指定のデータをダウンロード後、データフレームとして読込みます。そして、学習データ、検証データ、評価データに分割し、保存します。 ここまでは、第6章の問題50とまったく同じ処理のため、そちらで作成したデータを読み込んでも問題ありません。
# データのダウンロード !wget https://archive.ics.uci.edu/ml/machine-learning-databases/00359/NewsAggregatorDataset.zip !unzip NewsAggregatorDataset.zip
# 読込時のエラー回避のためダブルクォーテーションをシングルクォーテーションに置換 !sed -e 's/"/'\''/g' ./newsCorpora.csv > ./newsCorpora_re.csv
import pandas as pd from sklearn.model_selection import train_test_split # データの読込 df = pd.read_csv('./newsCorpora_re.csv', header=None, sep='\t', names=['ID', 'TITLE', 'URL', 'PUBLISHER', 'CATEGORY', 'STORY', 'HOSTNAME', 'TIMESTAMP']) # データの抽出 df = df.loc[df['PUBLISHER'].isin(['Reuters', 'Huffington Post', 'Businessweek', 'Contactmusic.com', 'Daily Mail']), ['TITLE', 'CATEGORY']] # データの分割 train, valid_test = train_test_split(df, test_size=0.2, shuffle=True, random_state=123, stratify=df['CATEGORY']) valid, test = train_test_split(valid_test, test_size=0.5, shuffle=True, random_state=123, stratify=valid_test['CATEGORY']) # 事例数の確認 print('【学習データ】') print(train['CATEGORY'].value_counts()) print('【検証データ】') print(valid['CATEGORY'].value_counts()) print('【評価データ】') print(test['CATEGORY'].value_counts())
--- 出力 --- 【学習データ】 b 4501 e 4235 t 1220 m 728 Name: CATEGORY, dtype: int64 【検証データ】 b 563 e 529 t 153 m 91 Name: CATEGORY, dtype: int64 【評価データ】 b 563 e 530 t 152 m 91 Name: CATEGORY, dtype: int64
続いて、単語の辞書を作成します。 学習データの単語をカウントし、2回以上登場するものをキーとして頻度順位(ID)を登録していきます。
from collections import defaultdict import string # 単語の頻度集計 d = defaultdict(int) table = str.maketrans(string.punctuation, ' '*len(string.punctuation)) # 記号をスペースに置換するテーブル for text in train['TITLE']: for word in text.translate(table).split(): d[word] += 1 d = sorted(d.items(), key=lambda x:x[1], reverse=True) # 単語ID辞書の作成 word2id = {word: i + 1 for i, (word, cnt) in enumerate(d) if cnt > 1} # 出現頻度が2回以上の単語を登録 print(f'ID数: {len(set(word2id.values()))}\n') print('頻度上位20語') for key in list(word2id)[:20]: print(f'{key}: {word2id[key]}')
--- 出力 --- ID数: 9405 頻度上位20語 to: 1 s: 2 in: 3 on: 4 UPDATE: 5 as: 6 US: 7 for: 8 The: 9 of: 10 1: 11 To: 12 2: 13 the: 14 and: 15 In: 16 Of: 17 a: 18 at: 19 A: 20
最後に、辞書を用いて与えられた単語列をID番号の列に変換する関数を定義します。このとき、問題文の指示に従い、辞書にない単語には0を返すようにします。
def tokenizer(text, word2id=word2id, unk=0): """ 入力テキストをスペースで分割しID列に変換(辞書になければunkで指定した数字を設定)""" table = str.maketrans(string.punctuation, ' '*len(string.punctuation)) return [word2id.get(word, unk) for word in text.translate(table).split()]
2つ目の文で確認します。
# 確認 text = train.iloc[1, train.columns.get_loc('TITLE')] print(f'テキスト: {text}') print(f'ID列: {tokenizer(text)}')
--- 出力 --- テキスト: Amazon Plans to Fight FTC Over Mobile-App Purchases ID列: [169, 539, 1, 683, 1237, 82, 279, 1898, 4199]
81. RNNによる予測
ID番号で表現された単語列
がある.ただし,
は単語列の長さ,
は単語のID番号のone-hot表記である(
は単語の総数である).再帰型ニューラルネットワーク(RNN: Recurrent Neural Network)を用い,単語列
からカテゴリ
を予測するモデルとして,次式を実装せよ.
ただし,
は単語埋め込み(単語のone-hot表記から単語ベクトルに変換する関数),
は時刻
の隠れ状態ベクトル,
は入力
と前時刻の隠れ状態
から次状態を計算するRNNユニット,
は隠れ状態ベクトルからカテゴリを予測するための行列,
はバイアス項である(
はそれぞれ,単語埋め込みの次元数,隠れ状態ベクトルの次元数,ラベル数である).RNNユニット
ただし,
はRNNユニットのパラメータ,
は活性化関数(例えば
やReLUなど)である.
なお,この問題ではパラメータの学習を行わず,ランダムに初期化されたパラメータで
など,適当な値に設定せよ(以降の問題でも同様である).
解答に入る前に、ニューラルネットを用いた自然言語処理、特にテキスト分類における処理の流れを整理しておきます。 ニューラルネットを用いたテキスト分類は、主に以下の4つの工程からなります。
- 文をトークン(例えば単語)の列に分割
- それぞれのトークンをベクトルに変換
- トークンベクトルを文ベクトルとして1つに集約
- 文ベクトルを入力としてラベルを分類
それぞれの工程について、いろいろな方法が考えられますが、例えば第8章では、
- 文をトークン(例えば単語)の列に分割 ⇒ スペースで分割
- それぞれのトークンをベクトルに変換 ⇒ 事前学習済みWord2Vecで変換
- トークンベクトルを文ベクトルとして1つに集約 ⇒ トークンベクトルを平均
- 文ベクトルを入力としてラベルを分類 ⇒ 全結合層で分類
の流れを実装し、No.4のパラメータを学習していました(日本語文書を対象とする場合は、No.1で第4章の形態素解析が必要となります)。
それに対し、本章では、
- 文をトークン(例えば単語)の列に分割 ⇒ スペースで分割
- それぞれのトークンをベクトルに変換 ⇒ 埋め込み層で変換
- トークンベクトルを文ベクトルとして1つに集約 ⇒ RNNまたはCNNで集約
- 文ベクトルを入力としてラベルを分類 ⇒ 全結合層で分類
となり、No.2~4を繋げたネットワークのパラメータを学習していきます。 なお、本章の問題のように、便宜的に分割したトークンを対応するIDに変換しておくことも多いですが、工程としてはNo.1に含まれます。
それでは、早速本問のネットワークを実装します。
埋め込み層にはnn.Embeddingを使います。この層は、単語IDを与えるとone-hotベクトルに変換した後、指定したサイズ(emb_size)のベクトルに変換します。
続くRNN部分は、全結合層を再帰的に通す処理で実現できますが、nn.RNNを用いることでシンプルに書くことができます。
最後に全結合層を繋げれば完成です。
import torch from torch import nn class RNN(nn.Module): def __init__(self, vocab_size, emb_size, padding_idx, output_size, hidden_size): super().__init__() self.hidden_size = hidden_size self.emb = nn.Embedding(vocab_size, emb_size, padding_idx=padding_idx) self.rnn = nn.RNN(emb_size, hidden_size, nonlinearity='tanh', batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): self.batch_size = x.size()[0] hidden = self.init_hidden(x.device) # h0のゼロベクトルを作成 emb = self.emb(x) # emb.size() = (batch_size, seq_len, emb_size) out, hidden = self.rnn(emb, hidden) # out.size() = (batch_size, seq_len, hidden_size) out = self.fc(out[:, -1, :]) # out.size() = (batch_size, output_size) return out def init_hidden(self, device): hidden = torch.zeros(1, self.batch_size, self.hidden_size, device=device) return hidden
次に、前章と同様にDatasetを作成するクラスを定義します。
今回は、テキストとラベルを受け取り、テキストを指定したtokenizerでID化した後、それぞれをTensor型で出力する機能を持たせます。
from torch.utils.data import Dataset class CreateDataset(Dataset): def __init__(self, X, y, tokenizer): self.X = X self.y = y self.tokenizer = tokenizer def __len__(self): # len(Dataset)で返す値を指定 return len(self.y) def __getitem__(self, index): # Dataset[index]で返す値を指定 text = self.X[index] inputs = self.tokenizer(text) return { 'inputs': torch.tensor(inputs, dtype=torch.int64), 'labels': torch.tensor(self.y[index], dtype=torch.int64) }
上記を用いてDatasetを作成します。tokenizerには、前問で定義した関数を指定します。
# ラベルベクトルの作成 category_dict = {'b': 0, 't': 1, 'e':2, 'm':3} y_train = train['CATEGORY'].map(lambda x: category_dict[x]).values y_valid = valid['CATEGORY'].map(lambda x: category_dict[x]).values y_test = test['CATEGORY'].map(lambda x: category_dict[x]).values # Datasetの作成 dataset_train = CreateDataset(train['TITLE'], y_train, tokenizer) dataset_valid = CreateDataset(valid['TITLE'], y_valid, tokenizer) dataset_test = CreateDataset(test['TITLE'], y_test, tokenizer) print(f'len(Dataset)の出力: {len(dataset_train)}') print('Dataset[index]の出力:') for var in dataset_train[1]: print(f' {var}: {dataset_train[1][var]}')
--- 出力 --- len(Dataset)の出力: 10684 Dataset[index]の出力: inputs: tensor([ 169, 539, 1, 683, 1237, 82, 279, 1898, 4199]) labels: 1
本問では学習しないため、Datasetからinputsをモデルに与え、Softmax後にそのまま出力を確認します。
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 # 辞書のID数 + パディングID EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, HIDDEN_SIZE) # 先頭10件の予測値取得 for i in range(10): X = dataset_train[i]['inputs'] print(torch.softmax(model(X.unsqueeze(0)), dim=-1))
--- 出力 --- tensor([[0.2667, 0.2074, 0.2974, 0.2285]], grad_fn=<SoftmaxBackward>) tensor([[0.1660, 0.3465, 0.2154, 0.2720]], grad_fn=<SoftmaxBackward>) tensor([[0.2133, 0.2987, 0.3097, 0.1783]], grad_fn=<SoftmaxBackward>) tensor([[0.2512, 0.4107, 0.1825, 0.1556]], grad_fn=<SoftmaxBackward>) tensor([[0.2784, 0.1307, 0.3715, 0.2194]], grad_fn=<SoftmaxBackward>) tensor([[0.2625, 0.1569, 0.2339, 0.3466]], grad_fn=<SoftmaxBackward>) tensor([[0.1331, 0.5129, 0.2220, 0.1319]], grad_fn=<SoftmaxBackward>) tensor([[0.2404, 0.1314, 0.2023, 0.4260]], grad_fn=<SoftmaxBackward>) tensor([[0.1162, 0.4576, 0.2588, 0.1674]], grad_fn=<SoftmaxBackward>) tensor([[0.4685, 0.1414, 0.2633, 0.1268]], grad_fn=<SoftmaxBackward>)
82. 確率的勾配降下法による学習
確率的勾配降下法(SGD: Stochastic Gradient Descent)を用いて,問題81で構築したモデルを学習せよ.訓練データ上の損失と正解率,評価データ上の損失と正解率を表示しながらモデルを学習し,適当な基準(例えば10エポックなど)で終了させよ.
こちらも前章同様に、学習のための一連の処理をtrain_model関数として定義します。
from torch.utils.data import DataLoader import time from torch import optim def calculate_loss_and_accuracy(model, dataset, device=None, criterion=None): """損失・正解率を計算""" dataloader = DataLoader(dataset, batch_size=1, shuffle=False) loss = 0.0 total = 0 correct = 0 with torch.no_grad(): for data in dataloader: # デバイスの指定 inputs = data['inputs'].to(device) labels = data['labels'].to(device) # 順伝播 outputs = model(inputs) # 損失計算 if criterion != None: loss += criterion(outputs, labels).item() # 正解率計算 pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return loss / len(dataset), correct / total def train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, num_epochs, collate_fn=None, device=None): """モデルの学習を実行し、損失・正解率のログを返す""" # デバイスの指定 model.to(device) # dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, collate_fn=collate_fn) dataloader_valid = DataLoader(dataset_valid, batch_size=1, shuffle=False) # スケジューラの設定 scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, num_epochs, eta_min=1e-5, last_epoch=-1) # 学習 log_train = [] log_valid = [] for epoch in range(num_epochs): # 開始時刻の記録 s_time = time.time() # 訓練モードに設定 model.train() for data in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 inputs = data['inputs'].to(device) labels = data['labels'].to(device) outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 評価モードに設定 model.eval() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, dataset_train, device, criterion=criterion) loss_valid, acc_valid = calculate_loss_and_accuracy(model, dataset_valid, device, criterion=criterion) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # 終了時刻の記録 e_time = time.time() # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}, {(e_time - s_time):.4f}sec') # 検証データの損失が3エポック連続で低下しなかった場合は学習終了 if epoch > 2 and log_valid[epoch - 3][0] <= log_valid[epoch - 2][0] <= log_valid[epoch - 1][0] <= log_valid[epoch][0]: break # スケジューラを1ステップ進める scheduler.step() return {'train': log_train, 'valid': log_valid}
さらに、ログを可視化するための関数も定義しておきます。
import numpy as np from matplotlib import pyplot as plt def visualize_logs(log): fig, ax = plt.subplots(1, 2, figsize=(15, 5)) ax[0].plot(np.array(log['train']).T[0], label='train') ax[0].plot(np.array(log['valid']).T[0], label='valid') ax[0].set_xlabel('epoch') ax[0].set_ylabel('loss') ax[0].legend() ax[1].plot(np.array(log['train']).T[1], label='train') ax[1].plot(np.array(log['valid']).T[1], label='valid') ax[1].set_xlabel('epoch') ax[1].set_ylabel('accuracy') ax[1].legend() plt.show()
パラメータを設定し、モデルを学習します。
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 LEARNING_RATE = 1e-3 BATCH_SIZE = 1 NUM_EPOCHS = 10 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, HIDDEN_SIZE) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE) # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS)
--- 出力 --- epoch: 1, loss_train: 1.0954, accuracy_train: 0.5356, loss_valid: 1.1334, accuracy_valid: 0.5015, 86.4033sec epoch: 2, loss_train: 1.0040, accuracy_train: 0.6019, loss_valid: 1.0770, accuracy_valid: 0.5516, 85.2816sec epoch: 3, loss_train: 0.8813, accuracy_train: 0.6689, loss_valid: 0.9793, accuracy_valid: 0.6287, 78.9026sec epoch: 4, loss_train: 0.7384, accuracy_train: 0.7364, loss_valid: 0.8498, accuracy_valid: 0.7058, 78.4496sec epoch: 5, loss_train: 0.6427, accuracy_train: 0.7696, loss_valid: 0.7878, accuracy_valid: 0.7253, 83.4453sec epoch: 6, loss_train: 0.5730, accuracy_train: 0.7942, loss_valid: 0.7378, accuracy_valid: 0.7470, 79.6968sec epoch: 7, loss_train: 0.5221, accuracy_train: 0.8064, loss_valid: 0.7058, accuracy_valid: 0.7530, 79.7377sec epoch: 8, loss_train: 0.4924, accuracy_train: 0.8173, loss_valid: 0.7017, accuracy_valid: 0.7605, 78.2168sec epoch: 9, loss_train: 0.4800, accuracy_train: 0.8234, loss_valid: 0.7014, accuracy_valid: 0.7575, 77.8689sec epoch: 10, loss_train: 0.4706, accuracy_train: 0.8253, loss_valid: 0.6889, accuracy_valid: 0.7650, 79.4202sec
# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train) _, acc_test = calculate_loss_and_accuracy(model, dataset_test) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')

--- 出力 --- 正解率(学習データ):0.825 正解率(評価データ):0.773
83. ミニバッチ化・GPU上での学習
問題82のコードを改変し,
事例ごとに損失・勾配を計算して学習を行えるようにせよ(
現在は文ごとに系列長が異なりますが、ミニバッチとしてまとめるには系列長を揃える必要があります。
そこで、複数の文の最大系列長に合わせてパディングする機能を持つPadsequenceクラスを新たに定義します。これをDataloaderの引数collate_fnに与えることで、ミニバッチを取り出すごとに系列長を揃える処理を実現することができます。
class Padsequence(): """Dataloaderからミニバッチを取り出すごとに最大系列長でパディング""" def __init__(self, padding_idx): self.padding_idx = padding_idx def __call__(self, batch): sorted_batch = sorted(batch, key=lambda x: x['inputs'].shape[0], reverse=True) sequences = [x['inputs'] for x in sorted_batch] sequences_padded = torch.nn.utils.rnn.pad_sequence(sequences, batch_first=True, padding_value=self.padding_idx) labels = torch.LongTensor([x['labels'] for x in sorted_batch]) return {'inputs': sequences_padded, 'labels': labels}
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 LEARNING_RATE = 5e-2 BATCH_SIZE = 32 NUM_EPOCHS = 10 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, HIDDEN_SIZE) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device)
--- 出力 --- epoch: 1, loss_train: 1.2605, accuracy_train: 0.3890, loss_valid: 1.2479, accuracy_valid: 0.4162, 12.1096sec epoch: 2, loss_train: 1.2492, accuracy_train: 0.4246, loss_valid: 1.2541, accuracy_valid: 0.4424, 12.0607sec epoch: 3, loss_train: 1.2034, accuracy_train: 0.4795, loss_valid: 1.2220, accuracy_valid: 0.4686, 11.8881sec epoch: 4, loss_train: 1.1325, accuracy_train: 0.5392, loss_valid: 1.1542, accuracy_valid: 0.5210, 12.2269sec epoch: 5, loss_train: 1.0543, accuracy_train: 0.6214, loss_valid: 1.0623, accuracy_valid: 0.6175, 11.8767sec epoch: 6, loss_train: 1.0381, accuracy_train: 0.6316, loss_valid: 1.0556, accuracy_valid: 0.6145, 11.9757sec epoch: 7, loss_train: 1.0546, accuracy_train: 0.6165, loss_valid: 1.0806, accuracy_valid: 0.5913, 12.0352sec epoch: 8, loss_train: 0.9924, accuracy_train: 0.6689, loss_valid: 1.0150, accuracy_valid: 0.6587, 11.9090sec epoch: 9, loss_train: 1.0123, accuracy_train: 0.6517, loss_valid: 1.0482, accuracy_valid: 0.6310, 12.0953sec epoch: 10, loss_train: 1.0036, accuracy_train: 0.6623, loss_valid: 1.0319, accuracy_valid: 0.6504, 11.9331sec
# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train, device) _, acc_test = calculate_loss_and_accuracy(model, dataset_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')

--- 出力 --- 正解率(学習データ):0.662 正解率(評価データ):0.649
84. 単語ベクトルの導入
事前学習済みの単語ベクトル(例えば,Google Newsデータセット(約1,000億単語)での学習済み単語ベクトル)で単語埋め込み
を初期化し,学習せよ.
前章と同様に事前学習済み単語ベクトルをダウンロードします。
# 学習済み単語ベクトルのダウンロード import gdown url = 'https://drive.google.com/uc?id=0B7XkCwpI5KDYNlNUTTlSS21pQmM' output = 'GoogleNews-vectors-negative300.bin.gz' gdown.download(url, output, quiet=False)
事前学習済み単語ベクトルをモデルに利用する場合、その単語をすべて利用する方法(辞書を置き換える方法)と、手元のデータの辞書はそのまま利用し、それらの単語ベクトルの初期値としてのみ利用する方法があります。 今回は後者の方法を採用し、すでに作成している辞書に対応する単語ベクトルを抽出します。
from gensim.models import KeyedVectors # 学習済みモデルのロード model = KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin.gz', binary=True) # 学習済み単語ベクトルの取得 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 weights = np.zeros((VOCAB_SIZE, EMB_SIZE)) words_in_pretrained = 0 for i, word in enumerate(word2id.keys()): try: weights[i] = model[word] words_in_pretrained += 1 except KeyError: weights[i] = np.random.normal(scale=0.4, size=(EMB_SIZE,)) weights = torch.from_numpy(weights.astype((np.float32))) print(f'学習済みベクトル利用単語数: {words_in_pretrained} / {VOCAB_SIZE}') print(weights.size())
--- 出力 --- 学習済みベクトル利用単語数: 9174 / 9406 torch.Size([9406, 300])
ネットワークの埋め込み層に初期値を設定できるように変更します。 また、次の問題用に双方向化、多層化のための設定も追加しておきます。
class RNN(nn.Module): def __init__(self, vocab_size, emb_size, padding_idx, output_size, hidden_size, num_layers, emb_weights=None, bidirectional=False): super().__init__() self.hidden_size = hidden_size self.num_layers = num_layers self.num_directions = bidirectional + 1 # 単方向:1、双方向:2 if emb_weights != None: # 指定があれば埋め込み層の重みをemb_weightsで初期化 self.emb = nn.Embedding.from_pretrained(emb_weights, padding_idx=padding_idx) else: self.emb = nn.Embedding(vocab_size, emb_size, padding_idx=padding_idx) self.rnn = nn.RNN(emb_size, hidden_size, num_layers, nonlinearity='tanh', bidirectional=bidirectional, batch_first=True) self.fc = nn.Linear(hidden_size * self.num_directions, output_size) def forward(self, x): self.batch_size = x.size()[0] hidden = self.init_hidden(x.device) # h0のゼロベクトルを作成 emb = self.emb(x) # emb.size() = (batch_size, seq_len, emb_size) out, hidden = self.rnn(emb, hidden) # out.size() = (batch_size, seq_len, hidden_size * num_directions) out = self.fc(out[:, -1, :]) # out.size() = (batch_size, output_size) return out def init_hidden(self, device): hidden = torch.zeros(self.num_layers * self.num_directions, self.batch_size, self.hidden_size, device=device) return hidden
埋め込み層の初期値を指定して学習します。
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 NUM_LAYERS = 1 LEARNING_RATE = 5e-2 BATCH_SIZE = 32 NUM_EPOCHS = 10 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, HIDDEN_SIZE, NUM_LAYERS, emb_weights=weights) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device)
--- 出力 --- epoch: 1, loss_train: 1.1655, accuracy_train: 0.4270, loss_valid: 1.1839, accuracy_valid: 0.4244, 9.7483sec epoch: 2, loss_train: 1.1555, accuracy_train: 0.4635, loss_valid: 1.1404, accuracy_valid: 0.4865, 9.7553sec epoch: 3, loss_train: 1.0189, accuracy_train: 0.6263, loss_valid: 1.0551, accuracy_valid: 0.6085, 10.0445sec epoch: 4, loss_train: 1.0377, accuracy_train: 0.6221, loss_valid: 1.0947, accuracy_valid: 0.5951, 10.1138sec epoch: 5, loss_train: 1.0392, accuracy_train: 0.6082, loss_valid: 1.0776, accuracy_valid: 0.5921, 9.8540sec epoch: 6, loss_train: 1.0447, accuracy_train: 0.6087, loss_valid: 1.1020, accuracy_valid: 0.5793, 9.8598sec epoch: 7, loss_train: 0.9999, accuracy_train: 0.6270, loss_valid: 1.0519, accuracy_valid: 0.6108, 9.7565sec epoch: 8, loss_train: 0.9539, accuracy_train: 0.6557, loss_valid: 1.0092, accuracy_valid: 0.6385, 9.7457sec epoch: 9, loss_train: 0.9287, accuracy_train: 0.6674, loss_valid: 0.9806, accuracy_valid: 0.6430, 9.6464sec epoch: 10, loss_train: 0.9456, accuracy_train: 0.6593, loss_valid: 1.0029, accuracy_valid: 0.6377, 9.6835sec
# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train, device) _, acc_test = calculate_loss_and_accuracy(model, dataset_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')

--- 出力 --- 正解率(学習データ):0.659 正解率(評価データ):0.645
85. 双方向RNN・多層化
順方向と逆方向のRNNの両方を用いて入力テキストをエンコードし,モデルを学習せよ.
ただし,
はそれぞれ,順方向および逆方向のRNNで求めた時刻
は入力
は隠れ状態ベクトルからカテゴリを予測するための行列,
]はベクトル
と
の連結を表す。
さらに,双方向RNNを多層化して実験せよ.
双方向を指定する引数であるbidirectionalをTrueとし、またNUM_LAYERSを2に設定して学習を実行します。
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 NUM_LAYERS = 2 LEARNING_RATE = 5e-2 BATCH_SIZE = 32 NUM_EPOCHS = 10 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, HIDDEN_SIZE, NUM_LAYERS, emb_weights=weights, bidirectional=True) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device)
--- 出力 --- epoch: 1, loss_train: 1.1731, accuracy_train: 0.4307, loss_valid: 1.1915, accuracy_valid: 0.4274, 19.3181sec epoch: 2, loss_train: 1.0395, accuracy_train: 0.6116, loss_valid: 1.0555, accuracy_valid: 0.5996, 18.8118sec epoch: 3, loss_train: 1.0529, accuracy_train: 0.5899, loss_valid: 1.0832, accuracy_valid: 0.5696, 18.9088sec epoch: 4, loss_train: 0.9831, accuracy_train: 0.6351, loss_valid: 1.0144, accuracy_valid: 0.6235, 18.8913sec epoch: 5, loss_train: 1.0622, accuracy_train: 0.5797, loss_valid: 1.1142, accuracy_valid: 0.5487, 19.0636sec epoch: 6, loss_train: 1.0463, accuracy_train: 0.5741, loss_valid: 1.0972, accuracy_valid: 0.5367, 19.0612sec epoch: 7, loss_train: 1.0056, accuracy_train: 0.6102, loss_valid: 1.0485, accuracy_valid: 0.5898, 19.0420sec epoch: 8, loss_train: 0.9724, accuracy_train: 0.6294, loss_valid: 1.0278, accuracy_valid: 0.6093, 19.3077sec epoch: 9, loss_train: 0.9469, accuracy_train: 0.6371, loss_valid: 0.9943, accuracy_valid: 0.6160, 19.2803sec epoch: 10, loss_train: 0.9343, accuracy_train: 0.6451, loss_valid: 0.9867, accuracy_valid: 0.6235, 19.0755sec
# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train, device) _, acc_test = calculate_loss_and_accuracy(model, dataset_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')

--- 出力 --- 正解率(学習データ):0.645 正解率(評価データ):0.634
86. 畳み込みニューラルネットワーク (CNN)
ID番号で表現された単語列
がある.ただし,
からカテゴリ
ただし,畳み込みニューラルネットワークの構成は以下の通りとする.
- 単語埋め込みの次元数:
- 畳み込みのフィルターのサイズ: 3 トークン
- 畳み込みのストライド: 1 トークン
- 畳み込みのパディング: あり
- 畳み込み演算後の各時刻のベクトルの次元数:
- 畳み込み演算後に最大値プーリング(max pooling)を適用し,入力文を
次元の隠れベクトルで表現 すなわち,時刻
は次式で表される.
ただし,
はCNNのパラメータ,
]はベクトル
の連結である.なお,行列
の列数が
になるのは,3個のトークンの単語埋め込みを連結したものに対して,線形変換を行うためである. 最大値プーリングでは,特徴ベクトルの次元毎に全時刻における最大値を取り,入力文書の特徴ベクトル
を求める.
]でベクトル
の
番目の次元の値を表すことにすると,最大値プーリングは次式で表される.
最後に,入力文書の特徴ベクトル
とバイアス項
なお,この問題ではモデルの学習を行わず,ランダムに初期化された重み行列で
指定のネットワークを実装します。
埋め込み層に続き、nn.Conv2dで畳み込みを計算します。max_poolで系列長方向に最大値を取得しており、この部分で文単位にベクトルが集約されています。
from torch.nn import functional as F class CNN(nn.Module): def __init__(self, vocab_size, emb_size, padding_idx, output_size, out_channels, kernel_heights, stride, padding, emb_weights=None): super().__init__() if emb_weights != None: # 指定があれば埋め込み層の重みをemb_weightsで初期化 self.emb = nn.Embedding.from_pretrained(emb_weights, padding_idx=padding_idx) else: self.emb = nn.Embedding(vocab_size, emb_size, padding_idx=padding_idx) self.conv = nn.Conv2d(1, out_channels, (kernel_heights, emb_size), stride, (padding, 0)) self.drop = nn.Dropout(0.3) self.fc = nn.Linear(out_channels, output_size) def forward(self, x): # x.size() = (batch_size, seq_len) emb = self.emb(x).unsqueeze(1) # emb.size() = (batch_size, 1, seq_len, emb_size) conv = self.conv(emb) # conv.size() = (batch_size, out_channels, seq_len, 1) act = F.relu(conv.squeeze(3)) # act.size() = (batch_size, out_channels, seq_len) max_pool = F.max_pool1d(act, act.size()[2]) # max_pool.size() = (batch_size, out_channels, 1) -> seq_len方向に最大値を取得 out = self.fc(self.drop(max_pool.squeeze(2))) # out.size() = (batch_size, output_size) return out
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 OUT_CHANNELS = 100 KERNEL_HEIGHTS = 3 STRIDE = 1 PADDING = 1 # モデルの定義 model = CNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, OUT_CHANNELS, KERNEL_HEIGHTS, STRIDE, PADDING, emb_weights=weights) # 先頭10件の予測値取得 for i in range(10): X = dataset_train[i]['inputs'] print(torch.softmax(model(X.unsqueeze(0)), dim=-1))
--- 出力 --- tensor([[0.2607, 0.2267, 0.2121, 0.3006]], grad_fn=<SoftmaxBackward>) tensor([[0.2349, 0.2660, 0.2462, 0.2529]], grad_fn=<SoftmaxBackward>) tensor([[0.2305, 0.2649, 0.2099, 0.2948]], grad_fn=<SoftmaxBackward>) tensor([[0.2569, 0.2409, 0.2418, 0.2604]], grad_fn=<SoftmaxBackward>) tensor([[0.2610, 0.2149, 0.2355, 0.2886]], grad_fn=<SoftmaxBackward>) tensor([[0.2627, 0.2363, 0.2388, 0.2622]], grad_fn=<SoftmaxBackward>) tensor([[0.2694, 0.2434, 0.2224, 0.2648]], grad_fn=<SoftmaxBackward>) tensor([[0.2423, 0.2465, 0.2365, 0.2747]], grad_fn=<SoftmaxBackward>) tensor([[0.2591, 0.2695, 0.2468, 0.2246]], grad_fn=<SoftmaxBackward>) tensor([[0.2794, 0.2465, 0.2234, 0.2507]], grad_fn=<SoftmaxBackward>)
87. 確率的勾配降下法によるCNNの学習
確率的勾配降下法(SGD: Stochastic Gradient Descent)を用いて,問題86で構築したモデルを学習せよ.訓練データ上の損失と正解率,評価データ上の損失と正解率を表示しながらモデルを学習し,適当な基準(例えば10エポックなど)で終了させよ.
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 OUT_CHANNELS = 100 KERNEL_HEIGHTS = 3 STRIDE = 1 PADDING = 1 LEARNING_RATE = 5e-2 BATCH_SIZE = 64 NUM_EPOCHS = 10 # モデルの定義 model = CNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, OUT_CHANNELS, KERNEL_HEIGHTS, STRIDE, PADDING, emb_weights=weights) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device)
--- 出力 --- epoch: 1, loss_train: 1.0671, accuracy_train: 0.5543, loss_valid: 1.0744, accuracy_valid: 0.5726, 12.9214sec epoch: 2, loss_train: 0.9891, accuracy_train: 0.6594, loss_valid: 1.0148, accuracy_valid: 0.6452, 12.6483sec epoch: 3, loss_train: 0.9098, accuracy_train: 0.6928, loss_valid: 0.9470, accuracy_valid: 0.6729, 12.7305sec epoch: 4, loss_train: 0.8481, accuracy_train: 0.7139, loss_valid: 0.8956, accuracy_valid: 0.7028, 12.7967sec epoch: 5, loss_train: 0.8055, accuracy_train: 0.7250, loss_valid: 0.8634, accuracy_valid: 0.7096, 12.6543sec epoch: 6, loss_train: 0.7728, accuracy_train: 0.7361, loss_valid: 0.8425, accuracy_valid: 0.7141, 12.7423sec epoch: 7, loss_train: 0.7527, accuracy_train: 0.7396, loss_valid: 0.8307, accuracy_valid: 0.7216, 12.6718sec epoch: 8, loss_train: 0.7403, accuracy_train: 0.7432, loss_valid: 0.8227, accuracy_valid: 0.7246, 12.5854sec epoch: 9, loss_train: 0.7346, accuracy_train: 0.7447, loss_valid: 0.8177, accuracy_valid: 0.7216, 12.4846sec epoch: 10, loss_train: 0.7331, accuracy_train: 0.7448, loss_valid: 0.8167, accuracy_valid: 0.7231, 12.7443sec
# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train, device) _, acc_test = calculate_loss_and_accuracy(model, dataset_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')

--- 出力 --- 正解率(学習データ):0.745 正解率(評価データ):0.719
88. パラメータチューニング
問題85や問題87のコードを改変し,ニューラルネットワークの形状やハイパーパラメータを調整しながら,高性能なカテゴリ分類器を構築せよ.
今回はConvolutional Neural Networks for Sentence Classificationで提案されたTextCNNをシンプルにしたネットワークを試してみます。 前問までのCNNでは幅が3のフィルターのみを学習していましたが、このネットワークでは2、3、4の3種類の幅のフィルターを利用します。
from torch.nn import functional as F class textCNN(nn.Module): def __init__(self, vocab_size, emb_size, padding_idx, output_size, out_channels, conv_params, drop_rate, emb_weights=None): super().__init__() if emb_weights != None: # 指定があれば埋め込み層の重みをemb_weightsで初期化 self.emb = nn.Embedding.from_pretrained(emb_weights, padding_idx=padding_idx) else: self.emb = nn.Embedding(vocab_size, emb_size, padding_idx=padding_idx) self.convs = nn.ModuleList([nn.Conv2d(1, out_channels, (kernel_height, emb_size), padding=(padding, 0)) for kernel_height, padding in conv_params]) self.drop = nn.Dropout(drop_rate) self.fc = nn.Linear(len(conv_params) * out_channels, output_size) def forward(self, x): # x.size() = (batch_size, seq_len) emb = self.emb(x).unsqueeze(1) # emb.size() = (batch_size, 1, seq_len, emb_size) conv = [F.relu(conv(emb)).squeeze(3) for i, conv in enumerate(self.convs)] # conv[i].size() = (batch_size, out_channels, seq_len + padding * 2 - kernel_height + 1) max_pool = [F.max_pool1d(i, i.size(2)) for i in conv] # max_pool[i].size() = (batch_size, out_channels, 1) -> seq_len方向に最大値を取得 max_pool_cat = torch.cat(max_pool, 1) # max_pool_cat.size() = (batch_size, len(conv_params) * out_channels, 1) -> フィルター別の結果を結合 out = self.fc(self.drop(max_pool_cat.squeeze(2))) # out.size() = (batch_size, output_size) return out
また、パラメータのチューニングには第6章と同様にoptunaを使います。
!pip install optuna
import optuna def objective(trial): # チューニング対象パラメータのセット emb_size = int(trial.suggest_discrete_uniform('emb_size', 100, 400, 100)) out_channels = int(trial.suggest_discrete_uniform('out_channels', 50, 200, 50)) drop_rate = trial.suggest_discrete_uniform('drop_rate', 0.0, 0.5, 0.1) learning_rate = trial.suggest_loguniform('learning_rate', 5e-4, 5e-2) momentum = trial.suggest_discrete_uniform('momentum', 0.5, 0.9, 0.1) batch_size = int(trial.suggest_discrete_uniform('batch_size', 16, 128, 16)) # 固定パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 CONV_PARAMS = [[2, 0], [3, 1], [4, 2]] NUM_EPOCHS = 30 # モデルの定義 model = textCNN(VOCAB_SIZE, emb_size, PADDING_IDX, OUTPUT_SIZE, out_channels, CONV_PARAMS, drop_rate, emb_weights=weights) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # デバイスの指定 device = torch.cuda.set_device(0) # モデルの学習 log = train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device) # 損失の算出 loss_valid, _ = calculate_loss_and_accuracy(model, dataset_valid, device, criterion=criterion) return loss_valid
パラメータ探索を実行します。
# 最適化 study = optuna.create_study() study.optimize(objective, timeout=7200) # 結果の表示 print('Best trial:') trial = study.best_trial print(' Value: {:.3f}'.format(trial.value)) print(' Params: ') for key, value in trial.params.items(): print(' {}: {}'.format(key, value))
--- 出力 ---
Best trial:
Value: 0.469
Params:
emb_size: 300.0
out_channels: 100.0
drop_rate: 0.4
learning_rate: 0.013345934577557608
momentum: 0.8
batch_size: 32.0
探索したパラメータでモデルを学習します。
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = int(trial.params['emb_size']) PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 OUT_CHANNELS = int(trial.params['out_channels']) CONV_PARAMS = [[2, 0], [3, 1], [4, 2]] DROP_RATE = trial.params['drop_rate'] LEARNING_RATE = trial.params['learning_rate'] BATCH_SIZE = int(trial.params['batch_size']) NUM_EPOCHS = 30 # モデルの定義 model = textCNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, OUT_CHANNELS, CONV_PARAMS, DROP_RATE, emb_weights=weights) print(model) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE, momentum=0.9) # デバイスの指定 device = torch.cuda.set_device(0) # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device)
--- 出力 ---
textCNN(
(emb): Embedding(9406, 300, padding_idx=9405)
(convs): ModuleList(
(0): Conv2d(1, 100, kernel_size=(2, 300), stride=(1, 1))
(1): Conv2d(1, 100, kernel_size=(3, 300), stride=(1, 1), padding=(1, 0))
(2): Conv2d(1, 100, kernel_size=(4, 300), stride=(1, 1), padding=(2, 0))
)
(drop): Dropout(p=0.4, inplace=False)
(fc): Linear(in_features=300, out_features=4, bias=True)
)
epoch: 1, loss_train: 0.7908, accuracy_train: 0.7239, loss_valid: 0.8660, accuracy_valid: 0.6901, 12.2279sec
epoch: 2, loss_train: 0.5800, accuracy_train: 0.7944, loss_valid: 0.7384, accuracy_valid: 0.7485, 12.1637sec
epoch: 3, loss_train: 0.3951, accuracy_train: 0.8738, loss_valid: 0.6189, accuracy_valid: 0.7919, 12.1612sec
epoch: 4, loss_train: 0.2713, accuracy_train: 0.9217, loss_valid: 0.5499, accuracy_valid: 0.8136, 12.1877sec
epoch: 5, loss_train: 0.1913, accuracy_train: 0.9593, loss_valid: 0.5176, accuracy_valid: 0.8293, 12.1722sec
epoch: 6, loss_train: 0.1322, accuracy_train: 0.9749, loss_valid: 0.5042, accuracy_valid: 0.8234, 12.4483sec
epoch: 7, loss_train: 0.1033, accuracy_train: 0.9807, loss_valid: 0.4922, accuracy_valid: 0.8323, 12.1556sec
epoch: 8, loss_train: 0.0723, accuracy_train: 0.9943, loss_valid: 0.4900, accuracy_valid: 0.8308, 12.0309sec
epoch: 9, loss_train: 0.0537, accuracy_train: 0.9966, loss_valid: 0.4903, accuracy_valid: 0.8346, 11.9471sec
epoch: 10, loss_train: 0.0414, accuracy_train: 0.9966, loss_valid: 0.4801, accuracy_valid: 0.8421, 11.9275sec
epoch: 11, loss_train: 0.0366, accuracy_train: 0.9978, loss_valid: 0.4943, accuracy_valid: 0.8406, 11.9691sec
epoch: 12, loss_train: 0.0292, accuracy_train: 0.9983, loss_valid: 0.4839, accuracy_valid: 0.8436, 11.9665sec
epoch: 13, loss_train: 0.0271, accuracy_train: 0.9982, loss_valid: 0.5042, accuracy_valid: 0.8421, 11.9634sec
epoch: 14, loss_train: 0.0222, accuracy_train: 0.9986, loss_valid: 0.4912, accuracy_valid: 0.8458, 11.9298sec
epoch: 15, loss_train: 0.0194, accuracy_train: 0.9988, loss_valid: 0.4925, accuracy_valid: 0.8436, 11.9375sec
epoch: 16, loss_train: 0.0176, accuracy_train: 0.9988, loss_valid: 0.5074, accuracy_valid: 0.8451, 11.9333sec
epoch: 17, loss_train: 0.0163, accuracy_train: 0.9991, loss_valid: 0.5124, accuracy_valid: 0.8436, 11.9137sec
# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train, device) _, acc_test = calculate_loss_and_accuracy(model, dataset_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')

--- 出力 --- 正解率(学習データ):0.999 正解率(評価データ):0.851
89. 事前学習済み言語モデルからの転移学習
事前学習済み言語モデル(例えばBERTなど)を出発点として,ニュース記事見出しをカテゴリに分類するモデルを構築せよ.
【PyTorch】BERTを用いた文書分類入門として別の記事に切り出しています。 ここでは、正解率の結果のみ転記します。
正解率(学習データ):0.993 正解率(評価データ):0.948
理解を深めるためのオススメ教材


全100問の解答はこちら
【言語処理100本ノック 2020】Pythonによる解答例まとめ

この記事では、自然言語処理の問題集として有名な言語処理100本ノックの2020年版全100問のPythonによる解答例を紹介します。間違いやより良い方法など、お気づきの点があればぜひお気軽にコメントください。
なお、解答にはGoogle Colaboratoryを利用しており、各記事内のリンクより直接参照することができます。
目的別のオススメ解答順
言語処理100本ノックは、実務や研究で必要となる基礎力が幅広く習得できるようにとても練られて設計されているため、当然すべて解くというのが理想的なのですが、機械学習を勉強する目的によっては利用頻度の低い知識が含まれていることも事実です。
そこで、ここでは目的に応じて取り組むべき問題の例を参考として示します。
最速で機械学習コンペティションに参加したい
kaggleやSIGNATEといった機械学習コンペに参加したいと思った場合にも、言語処理100本ノックは強力な演習ツールとなります。一方で、コンペは実際に参加しないと得られないものも非常に多いため、ある程度の基礎を習得したあとは、実践にシフトすることが重要です。
そこで、オススメの取り組み順は以下のようになります。Pythonをある程度触ったことがある場合は、最初の導入本は省略してもOKです。
① Python導入本
② 第1章: 準備運動
③ 第6章: 機械学習
④ 第8章: ニューラルネット
⑤ 機械学習手法本
② 第1章: 準備運動
③ 第6章: 機械学習
④ 第8章: ニューラルネット
⑤ 機械学習手法本
以下、それぞれ解説します。
Python導入本
本当に初めてPythonを触る、という方は、演習の前にPythonの導入本を一冊軽く読みながら、実際にいくつかの例を実行してみることをオススメします。100本ノックに入ったあとの理解度が大きく変わるはずです。以下の2冊はどちらも分かりやすいので、好きな方を選んでみてください。


第1章: 準備運動
自然言語処理に限らないPythonによるデータの取扱いの基礎を習得することができます。この段階で、以下の書籍等を参照しながら、numpyやpandasといった基本的なデータ解析ライブラリにも触れておけるとなお良いです。

第6章: 機械学習
2~5章は大胆に省略します。6章では、実際のデータを使ってモデルを学習する意味やモデルの精度とは何か、といった核心的な知識を実際に実行しながら体験することができるため、コンペを目指す方には必須の章となります。
第8章: ニューラルネット
ご存じのとおり、現在多くのアプリケーションのベースやコンペの上位アルゴリズムはディープラーニング、つまりニューラルネットをベースとしています。この章では、とてもシンプルなニューラルネットの実装、および学習ループを自身で設計することを通して、将来避けては通れない発展的な技術を学ぶ上で必須となる基礎知識を習得することができます。
機械学習手法本
ここまでで、実際のデータからモデルを学習し、その精度を確認するといった一連の流れは実現できるはずです。あとは、実際のコンペに参加して実践の中で学んでいくことが一番ですが、最後に機械学習手法の理論・実装を横断的に解説している本を読んでおくことをオススメします。コンペでは、一つの手法がうまくいかない場合に、別の手法を次々に試すことが求められますが、その引出しを作っておくイメージです。
具体的には、以下の2冊が読みやすく、実践的です。


実務で使える機械学習の基礎力を習得したい
実務で機械学習を使いたいと思った場合、コンペと大きく異なるところは、データの取得や加工といった「分析以前」の作業が多くなることです。そこで、以下の取り組み順をオススメします。
① Python導入本
② 第1章: 準備運動
③ 第2章: UNIXコマンド
④ 第3章: 正規表現
⑤ 第6章: 機械学習
⑥ 第8章: ニューラルネット
⑦ 機械学習手法本
② 第1章: 準備運動
③ 第2章: UNIXコマンド
④ 第3章: 正規表現
⑤ 第6章: 機械学習
⑥ 第8章: ニューラルネット
⑦ 機械学習手法本
第2章: UNIXコマンド
データの取得や加工にはコマンドを活用することが多いかと思います。この章では頻出のコマンドを実際に試しながら習得することができるため、「どのコマンドを知っておくべきか」という観点から、取り組んでおくべき章であるといえます。
第3章: 正規表現
コマンドの実際の利用シーンにおいては正規表現を組み合わせることが多々あります。2章で習得した内容を実践的なものとするために、併せて本章にも取り組んでおくと良いでしょう。
もっとも、本当に正規表現を活用しようと思うと、本章の内容だけではやや網羅性に欠けるため、余裕があれば以下の書籍のような読みやすく、かつ網羅性の高いものにもチャレンジできると良いかと思います。

自然言語処理の基礎をしっかり習得したい
言語処理100本ノックを全力で活用しましょう。もっとも、日本語の解析を予定していない場合は、4、5章は飛ばしてもよいかと思います。
① Python導入本
② 第1章: 準備運動
③ 第2章: UNIXコマンド
④ 第3章: 正規表現
⑤ 自然言語処理概観本
⑥ 第4章: 形態素解析
⑦ 第5章: 係り受け解析
⑧ 第6章: 機械学習
⑨ 第7章: 単語ベクトル
⑩ 第8章: ニューラルネット
② 第1章: 準備運動
③ 第2章: UNIXコマンド
④ 第3章: 正規表現
⑤ 自然言語処理概観本
⑥ 第4章: 形態素解析
⑦ 第5章: 係り受け解析
⑧ 第6章: 機械学習
⑨ 第7章: 単語ベクトル
⑩ 第8章: ニューラルネット
自然言語処理概観本
自然言語処理領域において、どのような目的でどのような手法が用いられているのか、といった内容を理解するために領域全体を概観できるような本を読んでおくと良いかと思います。今できること、できないこと、を踏まえて以降の章に取り組むことで、今後の自身の方向性を考えながらより密度の濃い演習ができるはずです。
オススメは超有名どころですが以下の1冊です。

第7章: 単語ベクトル
単語のベクトル化とは何か、実際にどのような計算ができるのか、といった内容を習得することができます。単語同士の距離感を定量化することで何ができるのかを理解するために必須の章です。
9、10章について、いずれも知っておいて損はないものの、各自が目的に応じて勉強を進める中で、必要な部分は必要なタイミングで出会うはず、と思われるためオススメ順には入れておりません。取り組む意義がない、という意味では決してありませんので、問題をご覧になって興味のあるものにはぜひ挑戦してみてください。
全100問の解答例
第1章: 準備運動
テキストや文字列を扱う題材に取り組みながら,プログラミング言語のやや高度なトピックを復習します.
第2章: UNIXコマンド
研究やデータ分析において便利なUNIXツールを体験します.これらの再実装を通じて,プログラミング能力を高めつつ,既存のツールのエコシステムを体感します.
第3章: 正規表現
Wikipediaのページのマークアップ記述に正規表現を適用することで,様々な情報・知識を取り出します.
第4章: 形態素解析
夏目漱石の小説『吾輩は猫である』に形態素解析器を適用し,小説中の単語の統計を求めます.
第5章: 係り受け解析
『吾輩は猫である』に係り受け解析器を適用し,係り受け木の操作と統語的な分析を体験します.
第6章: 機械学習
文書分類器を機械学習で構築します.さらに,機械学習手法の評価方法を学びます.
第7章: 単語ベクトル
単語の類似度計算や単語アナロジーなどを通して,単語ベクトルの取り扱いを修得します.さらに,クラスタリングやベクトルの可視化を体験します.
第8章: ニューラルネット
深層学習フレームワークの使い方を学び,ニューラルネットワークに基づくカテゴリ分類を実装します.
第9章: RNN, CNN
深層学習フレームワークを用い,再帰型ニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)を実装します.
第10章: 機械翻訳
既存のツールを活用し,ニューラル機械翻訳モデルを構築します.
解答準備中
おわりに
言語処理100本ノックは自然言語処理そのものだけでなく、基本的なデータ処理や汎用的な機械学習についてもしっかり学ぶことができるように作られています。 オンラインコースなどで機械学習を勉強中の方も、とても良いアウトプットの練習になると思いますので、ぜひ挑戦してみてください。
【入門】BERTによる文書分類

本記事では、英語のニュース記事見出しをカテゴリに分類するタスクを通して、事前学習済みBERTモデルをファインチューニングする方法を解説していきます。
なお、この実装は言語処理100本ノック2020年版の問題89の解答にもなっています。 その他の問題の解答例は【言語処理100本ノック 2020】Pythonによる解答例まとめをご覧ください。
また、日本語を対象とした文書分類のチュートリアルは、以下の記事をご覧ください。
環境設定
コードの実行はGoogle Colaboratoryで行います。記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
BERTによる文書分類
公開データであるNews Aggregator Data Setを用います。 このデータによる、ニュース記事の見出しを「ビジネス」「科学技術」「エンターテイメント」「健康」のカテゴリに分類するタスクを対象に、BERTによる文書分類モデルを実装していきます。
データの読込
まずは対象のデータをダウンロードします。
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00359/NewsAggregatorDataset.zip !unzip NewsAggregatorDataset.zip
# 行数の確認 !wc -l ./newsCorpora.csv
--- 出力 --- 422937 ./newsCorpora.csv
# 先頭10行の確認 !head -10 ./newsCorpora.csv
--- 出力 --- 1 Fed official says weak data caused by weather, should not slow taper http://www.latimes.com/business/money/la-fi-mo-federal-reserve-plosser-stimulus-economy-20140310,0,1312750.story\?track=rss Los Angeles Times b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.latimes.com 1394470370698 2 Fed's Charles Plosser sees high bar for change in pace of tapering http://www.livemint.com/Politics/H2EvwJSK2VE6OF7iK1g3PP/Feds-Charles-Plosser-sees-high-bar-for-change-in-pace-of-ta.html Livemint b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.livemint.com 1394470371207 3 US open: Stocks fall after Fed official hints at accelerated tapering http://www.ifamagazine.com/news/us-open-stocks-fall-after-fed-official-hints-at-accelerated-tapering-294436 IFA Magazine b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.ifamagazine.com 1394470371550 4 Fed risks falling 'behind the curve', Charles Plosser says http://www.ifamagazine.com/news/fed-risks-falling-behind-the-curve-charles-plosser-says-294430 IFA Magazine b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.ifamagazine.com 1394470371793 5 Fed's Plosser: Nasty Weather Has Curbed Job Growth http://www.moneynews.com/Economy/federal-reserve-charles-plosser-weather-job-growth/2014/03/10/id/557011 Moneynews b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.moneynews.com 1394470372027 6 Plosser: Fed May Have to Accelerate Tapering Pace http://www.nasdaq.com/article/plosser-fed-may-have-to-accelerate-tapering-pace-20140310-00371 NASDAQ b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.nasdaq.com 1394470372212 7 Fed's Plosser: Taper pace may be too slow http://www.marketwatch.com/story/feds-plosser-taper-pace-may-be-too-slow-2014-03-10\?reflink=MW_news_stmp MarketWatch b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.marketwatch.com 1394470372405 8 Fed's Plosser expects US unemployment to fall to 6.2% by the end of 2014 http://www.fxstreet.com/news/forex-news/article.aspx\?storyid=23285020-b1b5-47ed-a8c4-96124bb91a39 FXstreet.com b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.fxstreet.com 1394470372615 9 US jobs growth last month hit by weather:Fed President Charles Plosser http://economictimes.indiatimes.com/news/international/business/us-jobs-growth-last-month-hit-by-weatherfed-president-charles-plosser/articleshow/31788000.cms Economic Times b ddUyU0VZz0BRneMioxUPQVP6sIxvM economictimes.indiatimes.com 1394470372792 10 ECB unlikely to end sterilisation of SMP purchases - traders http://www.iii.co.uk/news-opinion/reuters/news/152615 Interactive Investor b dPhGU51DcrolUIMxbRm0InaHGA2XM www.iii.co.uk 1394470501265
# 読込時のエラー回避のためダブルクォーテーションをシングルクォーテーションに置換 !sed -e 's/"/'\''/g' ./newsCorpora.csv > ./newsCorpora_re.csv
続いて、データフレームとして読込み、情報源(PUBLISHER)がReuters, Huffington Post, Businessweek, Contactmusic.com, Daily Mailの事例のみを抽出した後、学習データ、検証データ、評価データに分割しておきます。
import pandas as pd from sklearn.model_selection import train_test_split # データの読込 df = pd.read_csv('./newsCorpora_re.csv', header=None, sep='\t', names=['ID', 'TITLE', 'URL', 'PUBLISHER', 'CATEGORY', 'STORY', 'HOSTNAME', 'TIMESTAMP']) # データの抽出 df = df.loc[df['PUBLISHER'].isin(['Reuters', 'Huffington Post', 'Businessweek', 'Contactmusic.com', 'Daily Mail']), ['TITLE', 'CATEGORY']] # データの分割 train, valid_test = train_test_split(df, test_size=0.2, shuffle=True, random_state=123, stratify=df['CATEGORY']) valid, test = train_test_split(valid_test, test_size=0.5, shuffle=True, random_state=123, stratify=valid_test['CATEGORY']) train.reset_index(drop=True, inplace=True) valid.reset_index(drop=True, inplace=True) test.reset_index(drop=True, inplace=True) print(train.head())
--- 出力 ---
TITLE CATEGORY
0 REFILE-UPDATE 1-European car sales up for sixt... b
1 Amazon Plans to Fight FTC Over Mobile-App Purc... t
2 Kids Still Get Codeine In Emergency Rooms Desp... m
3 What On Earth Happened Between Solange And Jay... e
4 NATO Missile Defense Is Flight Tested Over Hawaii b
# 事例数の確認 print('【学習データ】') print(train['CATEGORY'].value_counts()) print('【検証データ】') print(valid['CATEGORY'].value_counts()) print('【評価データ】') print(test['CATEGORY'].value_counts())
--- 出力 --- 【学習データ】 b 4501 e 4235 t 1220 m 728 Name: CATEGORY, dtype: int64 【検証データ】 b 563 e 529 t 153 m 91 Name: CATEGORY, dtype: int64 【評価データ】 b 563 e 530 t 152 m 91 Name: CATEGORY, dtype: int64
(b: ビジネス、e: エンターテインメント、t: 科学技術、m: 健康)
学習の準備
BERTモデルを利用するためにtransformersライブラリをインストールしておきます。transformersを通じて、BERT以外にも多くの事前学習済みモデルを短いコードで非常に簡単に利用することができます。
!pip install transformers
モデルの学習と評価に必要なライブラリをインポートします。
import numpy as np import transformers import torch from torch.utils.data import Dataset, DataLoader from transformers import BertTokenizer, BertModel from torch import optim from torch import cuda import time from matplotlib import pyplot as plt
次に、データをモデルに投入可能な形に整形します。
まずは、PyTorchでよく利用される、特徴ベクトルとラベルベクトルを合わせて保持するDatasetを作成するためのクラスを定義します。
このクラスにtokenizerを渡すことで、入力テキストの前処理を行い、指定した最長系列長までパディングした上で単語IDに変換する処理を実現できるようにしておきます。
とはいえ、BERT用にすべての処理が書かれたtokenizerそのものは、のちほどtranformersを通じて取得するため、クラス内で必要なものはtokenizerに渡す処理と結果を受け取る処理のみです。
# Datasetの定義 class NewsDataset(Dataset): def __init__(self, X, y, tokenizer, max_len): self.X = X self.y = y self.tokenizer = tokenizer self.max_len = max_len def __len__(self): # len(Dataset)で返す値を指定 return len(self.y) def __getitem__(self, index): # Dataset[index]で返す値を指定 text = self.X[index] inputs = self.tokenizer.encode_plus( text, add_special_tokens=True, max_length=self.max_len, pad_to_max_length=True ) ids = inputs['input_ids'] mask = inputs['attention_mask'] return { 'ids': torch.LongTensor(ids), 'mask': torch.LongTensor(mask), 'labels': torch.Tensor(self.y[index]) }
上記を用いてDatasetを作成します。
なお、英語版事前学習済みモデルとして利用できるBERTは、最高精度を目指した構成であるLARGEと、それよりパラメータの少ないBASE、それらのそれぞれについて小文字のみ(Uncased)と大文字小文字混在(Cased)の4パターンがあります。 今回は、手軽に試すことができるBASEのUncasedを使っていきます。
# 正解ラベルのone-hot化 y_train = pd.get_dummies(train, columns=['CATEGORY'])[['CATEGORY_b', 'CATEGORY_e', 'CATEGORY_t', 'CATEGORY_m']].values y_valid = pd.get_dummies(valid, columns=['CATEGORY'])[['CATEGORY_b', 'CATEGORY_e', 'CATEGORY_t', 'CATEGORY_m']].values y_test = pd.get_dummies(test, columns=['CATEGORY'])[['CATEGORY_b', 'CATEGORY_e', 'CATEGORY_t', 'CATEGORY_m']].values # Datasetの作成 max_len = 20 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') dataset_train = NewsDataset(train['TITLE'], y_train, tokenizer, max_len) dataset_valid = NewsDataset(valid['TITLE'], y_valid, tokenizer, max_len) dataset_test = NewsDataset(test['TITLE'], y_test, tokenizer, max_len) for var in dataset_train[0]: print(f'{var}: {dataset_train[0][var]}')
--- 出力 ---
ids: tensor([ 101, 25416, 9463, 1011, 10651, 1015, 1011, 2647, 2482, 4341,
2039, 2005, 4369, 3204, 2004, 18730, 8980, 102, 0, 0])
mask: tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0])
labels: tensor([1., 0., 0., 0.])
1文目の文の情報を出力しています。
入力文字列がidsとしてID系列に変換されていることが確認できます。BERTでは、変換の過程で元の文の文頭と文末に特殊区切り文字である[CLS]と[SEP]がそれぞれ挿入されるため、それらも101と102として系列に含まれています。0はパディングを表します。
正解ラベルもlabelsとしてone-hot形式で保持しています。
また、パディングの位置を表すmaskも合わせて保持し、学習時にidsと一緒にモデルに渡せるようにしておきます。
続いて、ネットワークを定義します。
transfomersを用いることで、BERT部分はまるごとBertModelで表現可能です。その後、分類タスクに対応するため、BERTの出力ベクトルを受け取るドロップアウトと全結合層を定義すれば完成です。
# BERT分類モデルの定義 class BERTClass(torch.nn.Module): def __init__(self, drop_rate, otuput_size): super().__init__() self.bert = BertModel.from_pretrained('bert-base-uncased') self.drop = torch.nn.Dropout(drop_rate) self.fc = torch.nn.Linear(768, otuput_size) # BERTの出力に合わせて768次元を指定 def forward(self, ids, mask): _, out = self.bert(ids, attention_mask=mask, return_dict=False) out = self.fc(self.drop(out)) return out
BERT分類モデルの学習
ここまでで、Datasetとネットワークが準備できたため、あとは普段通りの学習ループを作成します。
ここでは一連の流れをtrain_model関数として定義しています。
登場する構成要素の意味については、【言語処理100本ノック 2020】第8章: ニューラルネットの記事の中で、問題の流れに沿って解説していますので、そちらをご参照ください。
def calculate_loss_and_accuracy(model, criterion, loader, device): """ 損失・正解率を計算""" model.eval() loss = 0.0 total = 0 correct = 0 with torch.no_grad(): for data in loader: # デバイスの指定 ids = data['ids'].to(device) mask = data['mask'].to(device) labels = data['labels'].to(device) # 順伝播 outputs = model(ids, mask) # 損失計算 loss += criterion(outputs, labels).item() # 正解率計算 pred = torch.argmax(outputs, dim=-1).cpu().numpy() # バッチサイズの長さの予測ラベル配列 labels = torch.argmax(labels, dim=-1).cpu().numpy() # バッチサイズの長さの正解ラベル配列 total += len(labels) correct += (pred == labels).sum().item() return loss / len(loader), correct / total def train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, num_epochs, device=None): """モデルの学習を実行し、損失・正解率のログを返す""" # デバイスの指定 model.to(device) # dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True) dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False) # 学習 log_train = [] log_valid = [] for epoch in range(num_epochs): # 開始時刻の記録 s_time = time.time() # 訓練モードに設定 model.train() for data in dataloader_train: # デバイスの指定 ids = data['ids'].to(device) mask = data['mask'].to(device) labels = data['labels'].to(device) # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 outputs = model(ids, mask) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train, device) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid, device) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # 終了時刻の記録 e_time = time.time() # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}, {(e_time - s_time):.4f}sec') return {'train': log_train, 'valid': log_valid}
パラメータを設定して、ファインチューニングを実行します。
# パラメータの設定 DROP_RATE = 0.4 OUTPUT_SIZE = 4 BATCH_SIZE = 32 NUM_EPOCHS = 4 LEARNING_RATE = 2e-5 # モデルの定義 model = BERTClass(DROP_RATE, OUTPUT_SIZE) # 損失関数の定義 criterion = torch.nn.BCEWithLogitsLoss() # オプティマイザの定義 optimizer = torch.optim.AdamW(params=model.parameters(), lr=LEARNING_RATE) # デバイスの指定 device = 'cuda' if cuda.is_available() else 'cpu' # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, device=device)
--- 出力 --- epoch: 1, loss_train: 0.0859, accuracy_train: 0.9516, loss_valid: 0.1142, accuracy_valid: 0.9229, 49.9137sec epoch: 2, loss_train: 0.0448, accuracy_train: 0.9766, loss_valid: 0.1046, accuracy_valid: 0.9259, 49.7376sec epoch: 3, loss_train: 0.0316, accuracy_train: 0.9831, loss_valid: 0.1082, accuracy_valid: 0.9266, 49.5454sec epoch: 4, loss_train: 0.0170, accuracy_train: 0.9932, loss_valid: 0.1179, accuracy_valid: 0.9289, 49.4525sec
結果を確認します。
# ログの可視化 x_axis = [x for x in range(1, len(log['train']) + 1)] fig, ax = plt.subplots(1, 2, figsize=(15, 5)) ax[0].plot(x_axis, np.array(log['train']).T[0], label='train') ax[0].plot(x_axis, np.array(log['valid']).T[0], label='valid') ax[0].set_xlabel('epoch') ax[0].set_ylabel('loss') ax[0].legend() ax[1].plot(x_axis, np.array(log['train']).T[1], label='train') ax[1].plot(x_axis, np.array(log['valid']).T[1], label='valid') ax[1].set_xlabel('epoch') ax[1].set_ylabel('accuracy') ax[1].legend() plt.show()

# 正解率の算出 def calculate_accuracy(model, dataset, device): # Dataloaderの作成 loader = DataLoader(dataset, batch_size=len(dataset), shuffle=False) model.eval() total = 0 correct = 0 with torch.no_grad(): for data in loader: # デバイスの指定 ids = data['ids'].to(device) mask = data['mask'].to(device) labels = data['labels'].to(device) # 順伝播 + 予測値の取得 + 正解数のカウント outputs = model.forward(ids, mask) pred = torch.argmax(outputs, dim=-1).cpu().numpy() labels = torch.argmax(labels, dim=-1).cpu().numpy() total += len(labels) correct += (pred == labels).sum().item() return correct / total print(f'正解率(学習データ):{calculate_accuracy(model, dataset_train, device):.3f}') print(f'正解率(検証データ):{calculate_accuracy(model, dataset_valid, device):.3f}') print(f'正解率(評価データ):{calculate_accuracy(model, dataset_test, device):.3f}')
--- 出力 --- 正解率(学習データ):0.993 正解率(検証データ):0.929 正解率(評価データ):0.948
評価データで95%ほどの正解率でした。
通常はさらに、検証データの精度を確認しながらBERTの層ごとの重み固定有無や学習率等のパラメータを調整することが多いと思います。 今回はパラメータ決め打ちでしたが比較的高精度であり、事前学習の強力さが表れた結果となりました。
理解を深めるためのオススメ教材
新納 浩幸 インプレス 2021年03月18日頃
参考文献
transformers BERT(公式) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018)(原論文)
【言語処理100本ノック 2020】第8章: ニューラルネット【Python】

自然言語処理の問題集として有名な言語処理100本ノックの2020年版の解答例です。 この記事では、以下の第1章から第10章のうち、「第8章: ニューラルネット」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNNとCNN
- 第10章: 機械翻訳
環境設定
コードの実行はGoogle Colaboratoryで行います。 以降の解答の実行結果をすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
第8章: ニューラルネット
第6章で取り組んだニュース記事のカテゴリ分類を題材として,ニューラルネットワークでカテゴリ分類モデルを実装する.なお,この章ではPyTorch, TensorFlow, Chainerなどの機械学習プラットフォームを活用せよ.
70. 単語ベクトルの和による特徴量
問題50で構築した学習データ,検証データ,評価データを行列・ベクトルに変換したい.例えば,学習データについて,すべての事例
の特徴ベクトル
を並べた行列
と正解ラベルを並べた行列(ベクトル)
を作成したい.
ここで,
は学習データの事例数であり,
と
はそれぞれ,
番目の事例の特徴量ベクトルと正解ラベルを表す. なお,今回は「ビジネス」「科学技術」「エンターテイメント」「健康」の4カテゴリ分類である.で
未満の自然数(
はで表現できる. 以降では,ラベルの種類数を
で表す(今回の分類タスクでは
である).
は,次式で求める.
ここで,
個の(記事見出しの)単語列から構成され,
は単語
に対応する単語ベクトル(次元数は
)である.すなわち,
次元の単語ベクトルを用いたので,
である.
なお,カテゴリ名とラベルの番号が一対一で対応付いていれば,上式の通りの対応付けでなくてもよい.
以上の仕様に基づき,以下の行列・ベクトルを作成し,ファイルに保存せよ.
- 学習データの特徴量行列:
- 学習データのラベルベクトル:
- 検証データの特徴量行列:
- 検証データのラベルベクトル:
- 評価データの特徴量行列:
- 評価データのラベルベクトル:
なお,
はそれぞれ,学習データの事例数,検証データの事例数,評価データの事例数である.
まずは、指定のデータをダウンロード後、データフレームとして読込みます。そして、学習データ、検証データ、評価データに分割し、保存します。
ここまでは、第6章の問題50とまったく同じ処理のため、そちらで作成したデータを読み込んでも問題ありません。
# データのダウンロード !wget https://archive.ics.uci.edu/ml/machine-learning-databases/00359/NewsAggregatorDataset.zip !unzip NewsAggregatorDataset.zip
# 読込時のエラー回避のためダブルクォーテーションをシングルクォーテーションに置換 !sed -e 's/"/'\''/g' ./newsCorpora.csv > ./newsCorpora_re.csv
import pandas as pd from sklearn.model_selection import train_test_split # データの読込 df = pd.read_csv('./newsCorpora_re.csv', header=None, sep='\t', names=['ID', 'TITLE', 'URL', 'PUBLISHER', 'CATEGORY', 'STORY', 'HOSTNAME', 'TIMESTAMP']) # データの抽出 df = df.loc[df['PUBLISHER'].isin(['Reuters', 'Huffington Post', 'Businessweek', 'Contactmusic.com', 'Daily Mail']), ['TITLE', 'CATEGORY']] # データの分割 train, valid_test = train_test_split(df, test_size=0.2, shuffle=True, random_state=123, stratify=df['CATEGORY']) valid, test = train_test_split(valid_test, test_size=0.5, shuffle=True, random_state=123, stratify=valid_test['CATEGORY']) # 事例数の確認 print('【学習データ】') print(train['CATEGORY'].value_counts()) print('【検証データ】') print(valid['CATEGORY'].value_counts()) print('【評価データ】') print(test['CATEGORY'].value_counts())
--- 出力 --- 【学習データ】 b 4501 e 4235 t 1220 m 728 Name: CATEGORY, dtype: int64 【検証データ】 b 563 e 529 t 153 m 91 Name: CATEGORY, dtype: int64 【評価データ】 b 563 e 530 t 152 m 91 Name: CATEGORY, dtype: int64
続いて、第7章の問題60でも利用した学習済み単語ベクトルをダウンロードし、ロードします。
import gdown from gensim.models import KeyedVectors # 学習済み単語ベクトルのダウンロード url = "https://drive.google.com/uc?id=0B7XkCwpI5KDYNlNUTTlSS21pQmM" output = 'GoogleNews-vectors-negative300.bin.gz' gdown.download(url, output, quiet=True) # ダウンロードファイルのロード model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin.gz', binary=True)
最後に、特徴ベクトルとラベルベクトルを作成し、保存します。 なお、このあとPyTorchによるニューラルネットのインプットとして利用するため、Tensor型に変換しています。
import string import torch def transform_w2v(text): table = str.maketrans(string.punctuation, ' '*len(string.punctuation)) words = text.translate(table).split() # 記号をスペースに置換後、スペースで分割してリスト化 vec = [model[word] for word in words if word in model] # 1語ずつベクトル化 return torch.tensor(sum(vec) / len(vec)) # 平均ベクトルをTensor型に変換して出力
# 特徴ベクトルの作成 X_train = torch.stack([transform_w2v(text) for text in train['TITLE']]) X_valid = torch.stack([transform_w2v(text) for text in valid['TITLE']]) X_test = torch.stack([transform_w2v(text) for text in test['TITLE']]) print(X_train.size()) print(X_train)
--- 出力 ---
torch.Size([10684, 300])
tensor([[ 0.0837, 0.0056, 0.0068, ..., 0.0751, 0.0433, -0.0868],
[ 0.0272, 0.0266, -0.0947, ..., -0.1046, -0.0489, -0.0092],
[ 0.0577, -0.0159, -0.0780, ..., -0.0421, 0.1229, 0.0876],
...,
[ 0.0392, -0.0052, 0.0686, ..., -0.0175, 0.0061, -0.0224],
[ 0.0798, 0.1017, 0.1066, ..., -0.0752, 0.0623, 0.1138],
[ 0.1664, 0.0451, 0.0508, ..., -0.0531, -0.0183, -0.0039]])
# ラベルベクトルの作成 category_dict = {'b': 0, 't': 1, 'e':2, 'm':3} y_train = torch.tensor(train['CATEGORY'].map(lambda x: category_dict[x]).values) y_valid = torch.tensor(valid['CATEGORY'].map(lambda x: category_dict[x]).values) y_test = torch.tensor(test['CATEGORY'].map(lambda x: category_dict[x]).values) print(y_train.size()) print(y_train)
--- 出力 --- torch.Size([10684]) tensor([0, 1, 3, ..., 0, 3, 2])
# 保存 torch.save(X_train, 'X_train.pt') torch.save(X_valid, 'X_valid.pt') torch.save(X_test, 'X_test.pt') torch.save(y_train, 'y_train.pt') torch.save(y_valid, 'y_valid.pt') torch.save(y_test, 'y_test.pt')
71. 単層ニューラルネットワークによる予測
問題70で保存した行列を読み込み,学習データについて以下の計算を実行せよ.
ただし,
はソフトマックス関数,は特徴ベクトル
を縦に並べた行列である.
行列
は単層ニューラルネットワークの重み行列で,ここではランダムな値で初期化すればよい(問題73以降で学習して求める).なお,
は未学習の行列
で事例
を分類したときに,各カテゴリに属する確率を表すベクトルである. 同様に,
は,学習データの事例
について,各カテゴリに属する確率を行列として表現している.
はじめに、SLPNetという単層ニューラルネットワークを定義します。__init__でネットワークを構成するレイヤーを定義し、forwardメソッドでインプットデータが順伝播時に通るレイヤーを順に配置していきます。
from torch import nn class SLPNet(nn.Module): def __init__(self, input_size, output_size): super().__init__() self.fc = nn.Linear(input_size, output_size, bias=False) nn.init.normal_(self.fc.weight, 0.0, 1.0) # 正規乱数で重みを初期化 def forward(self, x): x = self.fc(x) return x
続いて、定義したモデルを初期化し、指示された計算を実行します。
model = SLPNet(300, 4) # 単層ニューラルネットワークの初期化 y_hat_1 = torch.softmax(model(X_train[:1]), dim=-1) print(y_hat_1)
--- 出力 --- tensor([[0.4273, 0.0958, 0.2492, 0.2277]], grad_fn=<SoftmaxBackward>)
Y_hat = torch.softmax(model.forward(X_train[:4]), dim=-1) print(Y_hat)
--- 出力 ---
tensor([[0.4273, 0.0958, 0.2492, 0.2277],
[0.2445, 0.2431, 0.0197, 0.4927],
[0.7853, 0.1132, 0.0291, 0.0724],
[0.5279, 0.2319, 0.0873, 0.1529]], grad_fn=<SoftmaxBackward>)
72. 損失と勾配の計算
学習データの事例
ただし,事例集合に対するクロスエントロピー損失は,その集合に含まれる各事例の損失の平均とする.
ここでは、nnパッケージのCrossEntropyLossを利用します。
モデルの出力ベクトルとラベルベクトルを入力することで、上式の平均損失を計算することができます。
criterion = nn.CrossEntropyLoss()
l_1 = criterion(model(X_train[:1]), y_train[:1]) # 入力ベクトルはsoftmax前の値 model.zero_grad() # 勾配をゼロで初期化 l_1.backward() # 勾配を計算 print(f'損失: {l_1:.4f}') print(f'勾配:\n{model.fc.weight.grad}')
--- 出力 ---
損失: 2.9706
勾配:
tensor([[-0.0794, -0.0053, -0.0065, ..., -0.0713, -0.0411, 0.0823],
[ 0.0022, 0.0001, 0.0002, ..., 0.0020, 0.0011, -0.0023],
[ 0.0611, 0.0041, 0.0050, ..., 0.0549, 0.0316, -0.0634],
[ 0.0161, 0.0011, 0.0013, ..., 0.0144, 0.0083, -0.0167]])
l = criterion(model(X_train[:4]), y_train[:4]) model.zero_grad() l.backward() print(f'損失: {l:.4f}') print(f'勾配:\n{model.fc.weight.grad}')
損失: 3.0799
勾配:
tensor([[-0.0207, 0.0079, -0.0090, ..., -0.0350, -0.0003, 0.0232],
[-0.0055, -0.0063, 0.0225, ..., 0.0252, 0.0166, 0.0039],
[ 0.0325, -0.0089, -0.0215, ..., 0.0084, 0.0122, -0.0030],
[-0.0063, 0.0072, 0.0081, ..., 0.0014, -0.0285, -0.0241]])
73. 確率的勾配降下法による学習
確率的勾配降下法(SGD: Stochastic Gradient Descent)を用いて,行列
学習に当たり、DatasetとDataloaderを準備します。
Datasetは特徴ベクトルとラベルベクトルを合わせて保持することができる型で、以下のクラスを用いてもとのTensorを変換します。
from torch.utils.data import Dataset class NewsDataset(Dataset): def __init__(self, X, y): # datasetの構成要素を指定 self.X = X self.y = y def __len__(self): # len(dataset)で返す値を指定 return len(self.y) def __getitem__(self, idx): # dataset[idx]で返す値を指定 return [self.X[idx], self.y[idx]]
変換後、DataLoaderを作成します。DataloaderはDatasetを入力とし、指定したサイズ(batch_size)にまとめたデータを順に取り出すことができます。ここではbatch_size=1としているので、1つずつデータを取り出すDataloaderを作成することを意味します。
なお、Dataloaderはfor文で順に取り出すか、またはnext(iter(Dataloader))で次のかたまりを呼び出すことが可能です。
from torch.utils.data import DataLoader # Datasetの作成 Dataset_train = NewsDataset(X_train, y_train) dataset_valid = NewsDataset(X_valid, y_valid) dataset_test = NewsDataset(X_test, y_test) # Dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=1, shuffle=True) dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False) dataloader_test = DataLoader(dataset_test, batch_size=len(dataset_test), shuffle=False)
データの準備ができたので、行列を学習します。
モデルの定義、損失関数の定義は前問と同様です。今回は計算した勾配から重みも更新するため、オプティマイザも定義します。ここでは指示に従いSGDをセットしています。
部品が揃ったところで、エポック数を10として学習を実行します。
# モデルの定義 model = SLPNet(300, 4) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) # 学習 num_epochs = 10 for epoch in range(num_epochs): # 訓練モードに設定 model.train() loss_train = 0.0 for i, (inputs, labels) in enumerate(dataloader_train): # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失を記録 loss_train += loss.item() # バッチ単位の平均損失計算 loss_train = loss_train / i # 検証データの損失計算 model.eval() with torch.no_grad(): inputs, labels = next(iter(dataloader_valid)) outputs = model(inputs) loss_valid = criterion(outputs, labels) # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, loss_valid: {loss_valid:.4f}')
--- 出力 --- epoch: 1, loss_train: 0.4745, loss_valid: 0.3637 epoch: 2, loss_train: 0.3173, loss_valid: 0.3306 epoch: 3, loss_train: 0.2884, loss_valid: 0.3208 epoch: 4, loss_train: 0.2716, loss_valid: 0.3150 epoch: 5, loss_train: 0.2615, loss_valid: 0.3141 epoch: 6, loss_train: 0.2519, loss_valid: 0.3092 epoch: 7, loss_train: 0.2474, loss_valid: 0.3114 epoch: 8, loss_train: 0.2431, loss_valid: 0.3072 epoch: 9, loss_train: 0.2393, loss_valid: 0.3096 epoch: 10, loss_train: 0.2359, loss_valid: 0.3219
エポックが進むについて、徐々に学習データの損失が下がっていることが分かります。
74. 正解率の計測
問題73で求めた行列を用いて学習データおよび評価データの事例を分類したとき,その正解率をそれぞれ求めよ.
学習したモデルとDataloaderを入力として、正解率を算出する関数を定義します。
def calculate_accuracy(model, loader): model.eval() total = 0 correct = 0 with torch.no_grad(): for inputs, labels in loader: outputs = model(inputs) pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return correct / total
acc_train = calculate_accuracy(model, dataloader_train) acc_test = calculate_accuracy(model, dataloader_test) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')
--- 出力 --- 正解率(学習データ):0.920 正解率(評価データ):0.891
75. 損失と正解率のプロット
問題73のコードを改変し,各エポックのパラメータ更新が完了するたびに,訓練データでの損失,正解率,検証データでの損失,正解率をグラフにプロットし,学習の進捗状況を確認できるようにせよ.
前問の関数を損失も計算できるように改変し、エポック毎に適用することで損失と正解率を記録します。
def calculate_loss_and_accuracy(model, criterion, loader): model.eval() loss = 0.0 total = 0 correct = 0 with torch.no_grad(): for inputs, labels in loader: outputs = model(inputs) loss += criterion(outputs, labels).item() pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return loss / len(loader), correct / total
# モデルの定義 model = SLPNet(300, 4) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) # 学習 num_epochs = 30 log_train = [] log_valid = [] for epoch in range(num_epochs): # 訓練モードに設定 model.train() for inputs, labels in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}')
--- 出力 --- epoch: 1, loss_train: 0.3476, accuracy_train: 0.8796, loss_valid: 0.3656, accuracy_valid: 0.8840 epoch: 2, loss_train: 0.2912, accuracy_train: 0.8988, loss_valid: 0.3219, accuracy_valid: 0.8967 ・・・ epoch: 29, loss_train: 0.2102, accuracy_train: 0.9287, loss_valid: 0.3259, accuracy_valid: 0.8930 epoch: 30, loss_train: 0.2119, accuracy_train: 0.9289, loss_valid: 0.3262, accuracy_valid: 0.8945
from matplotlib import pyplot as plt # 視覚化 fig, ax = plt.subplots(1, 2, figsize=(15, 5)) ax[0].plot(np.array(log_train).T[0], label='train') ax[0].plot(np.array(log_valid).T[0], label='valid') ax[0].set_xlabel('epoch') ax[0].set_ylabel('loss') ax[0].legend() ax[1].plot(np.array(log_train).T[1], label='train') ax[1].plot(np.array(log_valid).T[1], label='valid') ax[1].set_xlabel('epoch') ax[1].set_ylabel('accuracy') ax[1].legend() plt.show()

76. チェックポイント
問題75のコードを改変し,各エポックのパラメータ更新が完了するたびに,チェックポイント(学習途中のパラメータ(重み行列など)の値や最適化アルゴリズムの内部状態)をファイルに書き出せ.
学習途中のパラメータはmodel.state_dict()、最適化アルゴリズムの内部状態はoptimizer.state_dict()でアクセス可能なので、各エポックでエポック数と合わせて保存する処理を追加します。
なお、出力は前問と同様のため省略します。
# モデルの定義 model = SLPNet(300, 4) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) # 学習 num_epochs = 10 log_train = [] log_valid = [] for epoch in range(num_epochs): # 訓練モードに設定 model.train() for inputs, labels in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}')
77. ミニバッチ化
問題76のコードを改変し,
と変化させながら,1エポックの学習に要する時間を比較せよ.
バッチサイズを変えるごとにすべての処理を書くのは大変なので、Dataloaderの作成以降の処理をtrain_modelとして関数化し、バッチサイズを含むいくつかのパラメータを引数として設定します。
import time def train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, num_epochs): # dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True) dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False) # 学習 log_train = [] log_valid = [] for epoch in range(num_epochs): # 開始時刻の記録 s_time = time.time() # 訓練モードに設定 model.train() for inputs, labels in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # 終了時刻の記録 e_time = time.time() # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}, {(e_time - s_time):.4f}sec') return {'train': log_train, 'valid': log_valid}
バッチサイズを変えながら、処理時間を計測します。
# datasetの作成 dataset_train = CreateDataset(X_train, y_train) dataset_valid = CreateDataset(X_valid, y_valid) # モデルの定義 model = SLPNet(300, 4) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) # モデルの学習 for batch_size in [2 ** i for i in range(11)]: print(f'バッチサイズ: {batch_size}') log = train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, 1)
--- 出力 --- バッチサイズ: 1 epoch: 1, loss_train: 0.3237, accuracy_train: 0.8888, loss_valid: 0.3476, accuracy_valid: 0.8817, 5.4416sec バッチサイズ: 2 epoch: 1, loss_train: 0.2966, accuracy_train: 0.8999, loss_valid: 0.3258, accuracy_valid: 0.8847, 3.0029sec バッチサイズ: 4 epoch: 1, loss_train: 0.2883, accuracy_train: 0.8999, loss_valid: 0.3222, accuracy_valid: 0.8862, 1.5988sec バッチサイズ: 8 epoch: 1, loss_train: 0.2835, accuracy_train: 0.9023, loss_valid: 0.3179, accuracy_valid: 0.8907, 0.8732sec バッチサイズ: 16 epoch: 1, loss_train: 0.2817, accuracy_train: 0.9038, loss_valid: 0.3164, accuracy_valid: 0.8907, 0.5445sec バッチサイズ: 32 epoch: 1, loss_train: 0.2810, accuracy_train: 0.9038, loss_valid: 0.3159, accuracy_valid: 0.8900, 0.3482sec バッチサイズ: 64 epoch: 1, loss_train: 0.2806, accuracy_train: 0.9040, loss_valid: 0.3157, accuracy_valid: 0.8900, 0.2580sec バッチサイズ: 128 epoch: 1, loss_train: 0.2806, accuracy_train: 0.9041, loss_valid: 0.3156, accuracy_valid: 0.8900, 0.1984sec バッチサイズ: 256 epoch: 1, loss_train: 0.2801, accuracy_train: 0.9039, loss_valid: 0.3155, accuracy_valid: 0.8900, 0.1715sec バッチサイズ: 512 epoch: 1, loss_train: 0.2802, accuracy_train: 0.9038, loss_valid: 0.3155, accuracy_valid: 0.8900, 0.2177sec バッチサイズ: 1024 epoch: 1, loss_train: 0.2792, accuracy_train: 0.9038, loss_valid: 0.3155, accuracy_valid: 0.8900, 0.1603sec
概ね、バッチサイズが大きいほど計算時間が短くなってることが分かります。
78. GPU上での学習
問題77のコードを改変し,GPU上で学習を実行せよ.
GPUを指定する引数deviceをcalculate_loss_and_accuracy、train_modelに追加します。
それぞれの関数内で、モデルおよび入力TensorをGPUに送る処理を追加し、deviceにcudaを指定すればGPUを使用することができます。
なお、Google Colaboratoryでは、あらかじめ画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておく必要があります(※ 利用しているプランによっては料金がかかります。事前にご確認ください)。
def calculate_loss_and_accuracy(model, criterion, loader, device): model.eval() loss = 0.0 total = 0 correct = 0 with torch.no_grad(): for inputs, labels in loader: inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) loss += criterion(outputs, labels).item() pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return loss / len(loader), correct / total def train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, num_epochs, device=None): # GPUに送る model.to(device) # dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True) dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False) # 学習 log_train = [] log_valid = [] for epoch in range(num_epochs): # 開始時刻の記録 s_time = time.time() # 訓練モードに設定 model.train() for inputs, labels in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 inputs = inputs.to(device) labels = labels.to(device) outputs = model.forward(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train, device) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid, device) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # 終了時刻の記録 e_time = time.time() # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}, {(e_time - s_time):.4f}sec') return {'train': log_train, 'valid': log_valid}
# datasetの作成 dataset_train = CreateDataset(X_train, y_train) dataset_valid = CreateDataset(X_valid, y_valid) # モデルの定義 model = SLPNet(300, 4) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) # デバイスの指定 device = torch.device('cuda') # モデルの学習 for batch_size in [2 ** i for i in range(11)]: print(f'バッチサイズ: {batch_size}') log = train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, 1, device=device)
--- 出力 --- バッチサイズ: 1 epoch: 1, loss_train: 0.3300, accuracy_train: 0.8874, loss_valid: 0.3584, accuracy_valid: 0.8772, 9.0342sec バッチサイズ: 2 epoch: 1, loss_train: 0.3025, accuracy_train: 0.8994, loss_valid: 0.3374, accuracy_valid: 0.8870, 4.6391sec バッチサイズ: 4 epoch: 1, loss_train: 0.2938, accuracy_train: 0.9005, loss_valid: 0.3321, accuracy_valid: 0.8855, 2.4228sec バッチサイズ: 8 epoch: 1, loss_train: 0.2894, accuracy_train: 0.9039, loss_valid: 0.3299, accuracy_valid: 0.8855, 1.2517sec バッチサイズ: 16 epoch: 1, loss_train: 0.2876, accuracy_train: 0.9038, loss_valid: 0.3285, accuracy_valid: 0.8855, 0.7149sec バッチサイズ: 32 epoch: 1, loss_train: 0.2867, accuracy_train: 0.9050, loss_valid: 0.3280, accuracy_valid: 0.8862, 0.4323sec バッチサイズ: 64 epoch: 1, loss_train: 0.2863, accuracy_train: 0.9050, loss_valid: 0.3277, accuracy_valid: 0.8862, 0.2834sec バッチサイズ: 128 epoch: 1, loss_train: 0.2869, accuracy_train: 0.9051, loss_valid: 0.3276, accuracy_valid: 0.8862, 0.2070sec バッチサイズ: 256 epoch: 1, loss_train: 0.2864, accuracy_train: 0.9054, loss_valid: 0.3275, accuracy_valid: 0.8862, 0.1587sec バッチサイズ: 512 epoch: 1, loss_train: 0.2859, accuracy_train: 0.9056, loss_valid: 0.3275, accuracy_valid: 0.8862, 0.2016sec バッチサイズ: 1024 epoch: 1, loss_train: 0.2858, accuracy_train: 0.9056, loss_valid: 0.3275, accuracy_valid: 0.8862, 0.1303sec
79. 多層ニューラルネットワーク
問題78のコードを改変し,バイアス項の導入や多層化など,ニューラルネットワークの形状を変更しながら,高性能なカテゴリ分類器を構築せよ.
多層ニューラルネットワークMLPNetを新たに定義します。このネットワークは入力層 -> 中間層 -> 出力層の構成とし、中間層のあとにバッチノーマライゼーションを行うことにします。
また、train_modelでは新たに学習の打ち切り基準を導入します。今回はシンプルに、検証データの損失が3エポック連続で低下しなかった場合に打ち切るルールとします。
さらに、学習率を徐々に下げるスケジューラも追加し、汎化性能の向上を狙います。
from torch.nn import functional as F class MLPNet(nn.Module): def __init__(self, input_size, mid_size, output_size, mid_layers): super().__init__() self.mid_layers = mid_layers self.fc = nn.Linear(input_size, mid_size) self.fc_mid = nn.Linear(mid_size, mid_size) self.fc_out = nn.Linear(mid_size, output_size) self.bn = nn.BatchNorm1d(mid_size) def forward(self, x): x = F.relu(self.fc(x)) for _ in range(self.mid_layers): x = F.relu(self.bn(self.fc_mid(x))) x = F.relu(self.fc_out(x)) return x
from torch import optim def calculate_loss_and_accuracy(model, criterion, loader, device): model.eval() loss = 0.0 total = 0 correct = 0 with torch.no_grad(): for inputs, labels in loader: inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) loss += criterion(outputs, labels).item() pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return loss / len(loader), correct / total def train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, num_epochs, device=None): # GPUに送る model.to(device) # dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True) dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False) # スケジューラの設定 scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, num_epochs, eta_min=1e-5, last_epoch=-1) # 学習 log_train = [] log_valid = [] for epoch in range(num_epochs): # 開始時刻の記録 s_time = time.time() # 訓練モードに設定 model.train() for inputs, labels in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 inputs = inputs.to(device) labels = labels.to(device) outputs = model.forward(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train, device) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid, device) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # 終了時刻の記録 e_time = time.time() # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}, {(e_time - s_time):.4f}sec') # 検証データの損失が3エポック連続で低下しなかった場合は学習終了 if epoch > 2 and log_valid[epoch - 3][0] <= log_valid[epoch - 2][0] <= log_valid[epoch - 1][0] <= log_valid[epoch][0]: break # スケジューラを1ステップ進める scheduler.step() return {'train': log_train, 'valid': log_valid}
# datasetの作成 dataset_train = CreateDataset(X_train, y_train) dataset_valid = CreateDataset(X_valid, y_valid) # モデルの定義 model = MLPNet(300, 200, 4, 1) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, 64, model, criterion, optimizer, 1000, device)
--- 出力 --- epoch: 1, loss_train: 1.1176, accuracy_train: 0.6679, loss_valid: 1.1150, accuracy_valid: 0.6572, 0.4695sec epoch: 2, loss_train: 0.8050, accuracy_train: 0.7620, loss_valid: 0.8005, accuracy_valid: 0.7687, 0.4521sec ・・・ epoch: 96, loss_train: 0.1708, accuracy_train: 0.9460, loss_valid: 0.2858, accuracy_valid: 0.9034, 0.4632sec epoch: 97, loss_train: 0.1702, accuracy_train: 0.9466, loss_valid: 0.2861, accuracy_valid: 0.9034, 0.5373sec
97エポックで打ち切りとなりました。 エポックごとの損失と正解率を可視化します。
fig, ax = plt.subplots(1, 2, figsize=(15, 5)) ax[0].plot(np.array(log['train']).T[0], label='train') ax[0].plot(np.array(log['valid']).T[0], label='valid') ax[0].set_xlabel('epoch') ax[0].set_ylabel('loss') ax[0].legend() ax[1].plot(np.array(log['train']).T[1], label='train') ax[1].plot(np.array(log['valid']).T[1], label='valid') ax[1].set_xlabel('epoch') ax[1].set_ylabel('accuracy') ax[1].legend() plt.show()

評価データの正解率を確認します。
def calculate_accuracy(model, loader, device): model.eval() total = 0 correct = 0 with torch.no_grad(): for inputs, labels in loader: inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return correct / total
# 正解率の確認 acc_train = calculate_accuracy(model, dataloader_train, device) acc_test = calculate_accuracy(model, dataloader_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')
--- 出力 --- 正解率(学習データ):0.947 正解率(評価データ):0.921
単層ニューラルネットワークでは評価データの正解率が0.891でしたが、多層にすることによって3ポイント向上しています。
理解を深めるためのオススメ教材
全100問の解答はこちら
【言語処理100本ノック 2020】第7章: 単語ベクトル【Python】

自然言語処理の問題集として有名な言語処理100本ノックの2020年版の解答例です。 この記事では、以下の第1章から第10章のうち、「第7章: 単語ベクトル」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNNとCNN
- 第10章: 機械翻訳
環境設定
コードの実行はGoogle Colaboratoryで行います。 以降の解答の実行結果をすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
第7章: 単語ベクトル
単語の意味を実ベクトルで表現する単語ベクトル(単語埋め込み)に関して,以下の処理を行うプログラムを作成せよ.
60. 単語ベクトルの読み込みと表示
Google Newsデータセット(約1,000億単語)での学習済み単語ベクトル(300万単語・フレーズ,300次元)をダウンロードし,”United States”の単語ベクトルを表示せよ.ただし,”United States”は内部的には”United_States”と表現されていることに注意せよ.
まずは、指定の学習済み単語ベクトルをダウンロードします。
import gdown url = 'https://drive.google.com/uc?id=0B7XkCwpI5KDYNlNUTTlSS21pQmM' output = 'GoogleNews-vectors-negative300.bin.gz' gdown.download(url, output, quiet=False)
続いて、自然言語処理のさまざまなタスクで利用されるGensimを用いて、単語ベクトルを読み込みます。
from gensim.models import KeyedVectors model = KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin.gz', binary=True)
読み込んだ後は、ベクトル化したい単語を指定するだけで簡単に単語ベクトルを得ることができます。
model['United_States']
--- 出力 ---
array([-3.61328125e-02, -4.83398438e-02, 2.35351562e-01, 1.74804688e-01,
-1.46484375e-01, -7.42187500e-02, -1.01562500e-01, -7.71484375e-02,
1.09375000e-01, -5.71289062e-02, -1.48437500e-01, -6.00585938e-02,
1.74804688e-01, -7.71484375e-02, 2.58789062e-02, -7.66601562e-02,
-3.80859375e-02, 1.35742188e-01, 3.75976562e-02, -4.19921875e-02,
・・・
61. 単語の類似度
“United States”と”U.S.”のコサイン類似度を計算せよ.
ここではsimilarityメソッドを利用します。2単語を指定すると、単語間のコサイン類似度を計算することができます。
model.similarity('United_States', 'U.S.')
--- 出力 --- 0.73107743
62. 類似度の高い単語10件
“United States”とコサイン類似度が高い10語と,その類似度を出力せよ.
ここではmost_similarメソッドを利用します。単語を指定すると、topnまでの類似度上位単語とその類似度を取得することができます。
model.most_similar('United_States', topn=10)
--- 出力 ---
[('Unites_States', 0.7877248525619507),
('Untied_States', 0.7541370391845703),
('United_Sates', 0.74007248878479),
('U.S.', 0.7310774326324463),
('theUnited_States', 0.6404393911361694),
('America', 0.6178410053253174),
('UnitedStates', 0.6167312264442444),
('Europe', 0.6132988929748535),
('countries', 0.6044804453849792),
('Canada', 0.6019070148468018)]
63. 加法構成性によるアナロジー
“Spain”の単語ベクトルから”Madrid”のベクトルを引き,”Athens”のベクトルを足したベクトルを計算し,そのベクトルと類似度の高い10語とその類似度を出力せよ.
前問でも利用したmost_similarメソッドは、足すベクトルと引くベクトルをそれぞれ指定した上で、計算後のベクトルと類似度が高い単語を取得することができます。
ここでは、問題文の指示に従い、Spain - Madrid + Athensのベクトルと類似度の高い単語を表示していますが、期待通りGreeceが1位に登場しています。
vec = model['Spain'] - model['madrid'] + model['Athens'] model.most_similar(positive=['Spain', 'Athens'], negative=['Madrid'], topn=10)
--- 出力 ---
[('Greece', 0.6898481249809265),
('Aristeidis_Grigoriadis', 0.5606848001480103),
('Ioannis_Drymonakos', 0.5552908778190613),
('Greeks', 0.545068621635437),
('Ioannis_Christou', 0.5400862693786621),
('Hrysopiyi_Devetzi', 0.5248444676399231),
('Heraklio', 0.5207759737968445),
('Athens_Greece', 0.516880989074707),
('Lithuania', 0.5166866183280945),
('Iraklion', 0.5146791934967041)]
64. アナロジーデータでの実験
単語アナロジーの評価データをダウンロードし,vec(2列目の単語) - vec(1列目の単語) + vec(3列目の単語)を計算し,そのベクトルと類似度が最も高い単語と,その類似度を求めよ.求めた単語と類似度は,各事例の末尾に追記せよ.
指定のデータをダウンロードします。
!wget http://download.tensorflow.org/data/questions-words.txt
# 先頭10行の確認 !head -10 questions-words.txt
--- 出力 --- : capital-common-countries Athens Greece Baghdad Iraq Athens Greece Bangkok Thailand Athens Greece Beijing China Athens Greece Berlin Germany Athens Greece Bern Switzerland Athens Greece Cairo Egypt Athens Greece Canberra Australia Athens Greece Hanoi Vietnam Athens Greece Havana Cuba
このデータは、(Athens-Greece, Tokyo-Japan)のように、意味的アナロジーを評価するための組と、(walk-walks, write-writes)のように文法的アナロジーを評価する組が含まれます。 全部で以下の14のカテゴリからなり、上の5つが前者、それ以外が後者に対応しています。
| No. | カテゴリ |
|---|---|
| 1 | capital-common-countries |
| 2 | capital-world |
| 3 | currency |
| 4 | city-in-state |
| 5 | family |
| 6 | gram1-adjective-to-adverb |
| 7 | gram2-opposite |
| 8 | gram3-comparative |
| 9 | gram4-superlative |
| 10 | gram5-present-participle |
| 11 | gram6-nationality-adjective |
| 12 | gram7-past-tense |
| 13 | gram8-plural |
| 14 | gram9-plural-verbs |
1行ずつ読込み、指定の単語と類似度を計算した上で整形したデータを出力します。
with open('./questions-words.txt', 'r') as f1, open('./questions-words-add.txt', 'w') as f2: for line in f1: # f1から1行ずつ読込み、求めた単語と類似度を追加してf2に書込む line = line.split() if line[0] == ':': category = line[1] else: word, cos = model.most_similar(positive=[line[1], line[2]], negative=[line[0]], topn=1)[0] f2.write(' '.join([category] + line + [word, str(cos) + '\n']))
!head -10 questions-words-add.txt
--- 出力 --- capital-common-countries Athens Greece Baghdad Iraq Iraqi 0.6351870894432068 capital-common-countries Athens Greece Bangkok Thailand Thailand 0.7137669324874878 capital-common-countries Athens Greece Beijing China China 0.7235777974128723 capital-common-countries Athens Greece Berlin Germany Germany 0.6734622120857239 capital-common-countries Athens Greece Bern Switzerland Switzerland 0.4919748306274414 capital-common-countries Athens Greece Cairo Egypt Egypt 0.7527809739112854 capital-common-countries Athens Greece Canberra Australia Australia 0.583732545375824 capital-common-countries Athens Greece Hanoi Vietnam Viet_Nam 0.6276341676712036 capital-common-countries Athens Greece Havana Cuba Cuba 0.6460992097854614 capital-common-countries Athens Greece Helsinki Finland Finland 0.6899983882904053
65. アナロジータスクでの正解率
64の実行結果を用い,意味的アナロジー(semantic analogy)と文法的アナロジー(syntactic analogy)の正解率を測定せよ.
対応するカテゴリごとにそれぞれ計算します。
with open('./questions-words-add.txt', 'r') as f: sem_cnt = 0 sem_cor = 0 syn_cnt = 0 syn_cor = 0 for line in f: line = line.split() if not line[0].startswith('gram'): sem_cnt += 1 if line[4] == line[5]: sem_cor += 1 else: syn_cnt += 1 if line[4] == line[5]: syn_cor += 1 print(f'意味的アナロジー正解率: {sem_cor/sem_cnt:.3f}') print(f'文法的アナロジー正解率: {syn_cor/syn_cnt:.3f}')
--- 出力 --- 意味的アナロジー正解率: 0.731 文法的アナロジー正解率: 0.740
66. WordSimilarity-353での評価
The WordSimilarity-353 Test Collectionの評価データをダウンロードし,単語ベクトルにより計算される類似度のランキングと,人間の類似度判定のランキングの間のスピアマン相関係数を計算せよ.
このデータは、単語のペアに対して人間が評価した類似度が付与されています。 それぞれのペアに対して単語ベクトルの類似度を計算し、両者のスピアマン順位相関係数を計算します。
!wget http://www.gabrilovich.com/resources/data/wordsim353/wordsim353.zip !unzip wordsim353.zip
--- 出力 --- Archive: wordsim353.zip inflating: combined.csv inflating: set1.csv inflating: set2.csv inflating: combined.tab inflating: set1.tab inflating: set2.tab inflating: instructions.txt
!head -10 './combined.csv'
--- 出力 --- Word 1,Word 2,Human (mean) love,sex,6.77 tiger,cat,7.35 tiger,tiger,10.00 book,paper,7.46 computer,keyboard,7.62 computer,internet,7.58 plane,car,5.77 train,car,6.31 telephone,communication,7.50
ws353 = [] with open('./combined.csv', 'r') as f: next(f) for line in f: # 1行ずつ読込み、単語ベクトルと類似度を計算 line = [s.strip() for s in line.split(',')] line.append(model.similarity(line[0], line[1])) ws353.append(line) # 確認 for i in range(5): print(ws353[i])
--- 出力 --- ['love', 'sex', '6.77', 0.2639377] ['tiger', 'cat', '7.35', 0.5172962] ['tiger', 'tiger', '10.00', 0.99999994] ['book', 'paper', '7.46', 0.3634626] ['computer', 'keyboard', '7.62', 0.39639163]
import numpy as np from scipy.stats import spearmanr # スピアマン相関係数の計算 human = np.array(ws353).T[2] w2v = np.array(ws353).T[3] correlation, pvalue = spearmanr(human, w2v) print(f'スピアマン相関係数: {correlation:.3f}')
--- 出力 --- スピアマン相関係数: 0.685
67. k-meansクラスタリング
国名に関する単語ベクトルを抽出し,k-meansクラスタリングをクラスタ数k=5として実行せよ.
適当な国名リストの取得元が見つからなかったため、単語アナロジーの評価データから収集しています。
# 国名の取得 countries = set() with open('./questions-words-add.txt') as f: for line in f: line = line.split() if line[0] in ['capital-common-countries', 'capital-world']: countries.add(line[2]) elif line[0] in ['currency', 'gram6-nationality-adjective']: countries.add(line[1]) countries = list(countries) # 単語ベクトルの取得 countries_vec = [model[country] for country in countries]
from sklearn.cluster import KMeans # k-meansクラスタリング kmeans = KMeans(n_clusters=5) kmeans.fit(countries_vec) for i in range(5): cluster = np.where(kmeans.labels_ == i)[0] print('cluster', i) print(', '.join([countries[k] for k in cluster]))
--- 出力 --- cluster 0 Taiwan, Afghanistan, Iraq, Lebanon, Indonesia, Turkey, Egypt, Libya, Syria, Korea, China, Nepal, Cambodia, India, Bhutan, Qatar, Laos, Malaysia, Iran, Vietnam, Oman, Bahrain, Pakistan, Thailand, Bangladesh, Morocco, Jordan, Israel cluster 1 Madagascar, Uganda, Botswana, Guinea, Malawi, Tunisia, Nigeria, Mauritania, Kenya, Zambia, Algeria, Mozambique, Ghana, Niger, Somalia, Angola, Mali, Senegal, Sudan, Zimbabwe, Gambia, Eritrea, Liberia, Burundi, Gabon, Rwanda, Namibia cluster 2 Suriname, Uruguay, Tuvalu, Nicaragua, Colombia, Belize, Venezuela, Ecuador, Fiji, Peru, Guyana, Jamaica, Brazil, Honduras, Samoa, Bahamas, Dominica, Philippines, Cuba, Chile, Mexico, Argentina cluster 3 Netherlands, Sweden, USA, Ireland, Canada, Spain, Malta, Greenland, Europe, Greece, France, Austria, Norway, Finland, Australia, Japan, Iceland, England, Italy, Denmark, Belgium, Switzerland, Germany, Portugal, Liechtenstein cluster 4 Croatia, Belarus, Uzbekistan, Latvia, Tajikistan, Slovakia, Ukraine, Hungary, Albania, Poland, Montenegro, Georgia, Russia, Kyrgyzstan, Armenia, Romania, Cyprus, Lithuania, Azerbaijan, Serbia, Slovenia, Turkmenistan, Moldova, Bulgaria, Estonia, Kazakhstan, Macedonia
68. Ward法によるクラスタリング
国名に関する単語ベクトルに対し,Ward法による階層型クラスタリングを実行せよ.さらに,クラスタリング結果をデンドログラムとして可視化せよ.
from matplotlib import pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage plt.figure(figsize=(15, 5)) Z = linkage(countries_vec, method='ward') dendrogram(Z, labels=countries) plt.show()

69. t-SNEによる可視化
国名に関する単語ベクトルのベクトル空間をt-SNEで可視化せよ.
t-SNEで単語ベクトルを2次元に圧縮し、散布図で可視化します。
!pip install bhtsne
import bhtsne embedded = bhtsne.tsne(np.array(countries_vec).astype(np.float64), dimensions=2, rand_seed=123) plt.figure(figsize=(10, 10)) plt.scatter(np.array(embedded).T[0], np.array(embedded).T[1]) for (x, y), name in zip(embedded, countries): plt.annotate(name, (x, y)) plt.show()

理解を深めるためのオススメ教材
全100問の解答はこちら
Google Colaboratoryで動画を再生する方法

この記事ではGoogle Colaboratoryで動画を再生する方法を紹介します。
web上の動画を再生したい場合
動画のURLを取得しておきます。URLを転記してセルで以下のコードを実行すると動画が表示されます。
from IPython.display import Video video_url = '取得したURL' Video(video_url)
オプションでwidth、heightの指定や、 html_attributes="loop autoplay"とすることで、自動ループ再生を指定することもできます。
PC上の動画を再生したい場合
まずは、再生したい動画をcolab上にアップロードします。アップロードの方法は以下の記事をご覧ください。
ここでは、sample.mp4というファイルを、/content/ディレクトリにアップロードしたとします。
ファイルの場合は、画像や動画をテキスト化するためのbase64という方式でエンコードした上で、HTML関数に渡します。width、heightで表示サイズを調節できるほか、自動再生(autoplay)やループ再生(loop)を指定できます。
from IPython.display import HTML from base64 import b64encode mp4 = open('/content/sample.mp4', 'rb').read() video_src = 'data:video/mp4;base64,' + b64encode(mp4).decode() HTML(f""" <video width="432" height="324" controls> <source type="video/mp4" src="{video_src}"> </video>) """)

渡辺 宙志 講談社 2020年12月17日頃
【言語処理100本ノック 2020】第6章: 機械学習【Python】

自然言語処理の問題集として有名な言語処理100本ノックの2020年版の解答例です。 この記事では、以下の第1章から第10章のうち、「第6章: 機械学習」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNNとCNN
- 第10章: 機械翻訳
環境設定
コードの実行はGoogle Colaboratoryで行います。 以降の解答の実行結果をすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
第6章: 機械学習
本章では,Fabio Gasparetti氏が公開しているNews Aggregator Data Setを用い,ニュース記事の見出しを「ビジネス」「科学技術」「エンターテイメント」「健康」のカテゴリに分類するタスク(カテゴリ分類)に取り組む.
50. データの入手・整形
News Aggregator Data Setをダウンロードし、以下の要領で学習データ(train.txt),検証データ(valid.txt),評価データ(test.txt)を作成せよ.
- ダウンロードしたzipファイルを解凍し,readme.txtの説明を読む.
- 情報源(publisher)が”Reuters”, “Huffington Post”, “Businessweek”, “Contactmusic.com”, “Daily Mail”の事例(記事)のみを抽出する.
- 抽出された事例をランダムに並び替える.
- 抽出された事例の80%を学習データ,残りの10%ずつを検証データと評価データに分割し,それぞれtrain.txt,valid.txt,test.txtというファイル名で保存する.ファイルには,1行に1事例を書き出すこととし,カテゴリ名と記事見出しのタブ区切り形式とせよ(このファイルは後に問題70で再利用する).
学習データと評価データを作成したら,各カテゴリの事例数を確認せよ.
まずは、指定のデータをダウンロードします。
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00359/NewsAggregatorDataset.zip !unzip NewsAggregatorDataset.zip
# 行数の確認 !wc -l ./newsCorpora.csv
--- 出力 --- 422937 ./newsCorpora.csv
# 先頭10行の確認 !head -10 ./newsCorpora.csv
--- 出力 --- 1 Fed official says weak data caused by weather, should not slow taper http://www.latimes.com/business/money/la-fi-mo-federal-reserve-plosser-stimulus-economy-20140310,0,1312750.story\?track=rss Los Angeles Times b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.latimes.com 1394470370698 2 Fed's Charles Plosser sees high bar for change in pace of tapering http://www.livemint.com/Politics/H2EvwJSK2VE6OF7iK1g3PP/Feds-Charles-Plosser-sees-high-bar-for-change-in-pace-of-ta.html Livemint b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.livemint.com 1394470371207 3 US open: Stocks fall after Fed official hints at accelerated tapering http://www.ifamagazine.com/news/us-open-stocks-fall-after-fed-official-hints-at-accelerated-tapering-294436 IFA Magazine b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.ifamagazine.com 1394470371550 4 Fed risks falling 'behind the curve', Charles Plosser says http://www.ifamagazine.com/news/fed-risks-falling-behind-the-curve-charles-plosser-says-294430 IFA Magazine b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.ifamagazine.com 1394470371793 5 Fed's Plosser: Nasty Weather Has Curbed Job Growth http://www.moneynews.com/Economy/federal-reserve-charles-plosser-weather-job-growth/2014/03/10/id/557011 Moneynews b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.moneynews.com 1394470372027 6 Plosser: Fed May Have to Accelerate Tapering Pace http://www.nasdaq.com/article/plosser-fed-may-have-to-accelerate-tapering-pace-20140310-00371 NASDAQ b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.nasdaq.com 1394470372212 7 Fed's Plosser: Taper pace may be too slow http://www.marketwatch.com/story/feds-plosser-taper-pace-may-be-too-slow-2014-03-10\?reflink=MW_news_stmp MarketWatch b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.marketwatch.com 1394470372405 8 Fed's Plosser expects US unemployment to fall to 6.2% by the end of 2014 http://www.fxstreet.com/news/forex-news/article.aspx\?storyid=23285020-b1b5-47ed-a8c4-96124bb91a39 FXstreet.com b ddUyU0VZz0BRneMioxUPQVP6sIxvM www.fxstreet.com 1394470372615 9 US jobs growth last month hit by weather:Fed President Charles Plosser http://economictimes.indiatimes.com/news/international/business/us-jobs-growth-last-month-hit-by-weatherfed-president-charles-plosser/articleshow/31788000.cms Economic Times b ddUyU0VZz0BRneMioxUPQVP6sIxvM economictimes.indiatimes.com 1394470372792 10 ECB unlikely to end sterilisation of SMP purchases - traders http://www.iii.co.uk/news-opinion/reuters/news/152615 Interactive Investor b dPhGU51DcrolUIMxbRm0InaHGA2XM www.iii.co.uk 1394470501265
# 読込時のエラー回避のためダブルクォーテーションをシングルクォーテーションに置換 !sed -e 's/"/'\''/g' ./newsCorpora.csv > ./newsCorpora_re.csv
続いて、pandasのデータフレームで読み込み、問題文の指示に従いデータを作成していきます。
データの分割にはscikit-learnのtrain_test_splitを利用しています。その際stratifyオプションを利用すると、指定したカラムの構成比が分割後の各データで等しくなるように分割されます。ここでは、分類の目的変数であるCATEGORYを指定し、データごとに偏りが生じないようにしています。
import pandas as pd from sklearn.model_selection import train_test_split # データの読込 df = pd.read_csv('./newsCorpora_re.csv', header=None, sep='\t', names=['ID', 'TITLE', 'URL', 'PUBLISHER', 'CATEGORY', 'STORY', 'HOSTNAME', 'TIMESTAMP']) # データの抽出 df = df.loc[df['PUBLISHER'].isin(['Reuters', 'Huffington Post', 'Businessweek', 'Contactmusic.com', 'Daily Mail']), ['TITLE', 'CATEGORY']] # データの分割 train, valid_test = train_test_split(df, test_size=0.2, shuffle=True, random_state=123, stratify=df['CATEGORY']) valid, test = train_test_split(valid_test, test_size=0.5, shuffle=True, random_state=123, stratify=valid_test['CATEGORY']) # データの保存 train.to_csv('./train.txt', sep='\t', index=False) valid.to_csv('./valid.txt', sep='\t', index=False) test.to_csv('./test.txt', sep='\t', index=False) # 事例数の確認 print('【学習データ】') print(train['CATEGORY'].value_counts()) print('【検証データ】') print(valid['CATEGORY'].value_counts()) print('【評価データ】') print(test['CATEGORY'].value_counts())
--- 出力 --- 【学習データ】 b 4501 e 4235 t 1220 m 728 Name: CATEGORY, dtype: int64 【検証データ】 b 563 e 529 t 153 m 91 Name: CATEGORY, dtype: int64 【評価データ】 b 563 e 530 t 152 m 91 Name: CATEGORY, dtype: int64
51. 特徴量抽出
学習データ,検証データ,評価データから特徴量を抽出し,それぞれtrain.feature.txt,valid.feature.txt,test.feature.txtというファイル名で保存せよ. なお,カテゴリ分類に有用そうな特徴量は各自で自由に設計せよ.記事の見出しを単語列に変換したものが最低限のベースラインとなるであろう.
今回は、記事の見出しをスペースで分割した単語群を対象にTF-IDFを算出し、その値を特徴量として利用することにします。また、1単語(uni-gram)だけでなく連続する2単語(bi-gram)についてもTF-IDFを計算します。 なお、上記を計算するにあたり、テキストの前処理として、①記号をスペースに置換、②アルファベットの小文字化、③数字列を0に置換、の3つの処理を行っています。
import string import re def preprocessing(text): table = str.maketrans(string.punctuation, ' '*len(string.punctuation)) text = text.translate(table) # 記号をスペースに置換 text = text.lower() # 小文字化 text = re.sub('[0-9]+', '0', text) # 数字列を0に置換 return text
# データの再結合 df = pd.concat([train, valid, test], axis=0) df.reset_index(drop=True, inplace=True) # indexを振りなおす # 前処理の実施 df['TITLE'] = df['TITLE'].map(lambda x: preprocessing(x)) print(df.head())
--- 出力 ---
TITLE CATEGORY
0 refile update 0 european car sales up for sixt... b
1 amazon plans to fight ftc over mobile app purc... t
2 kids still get codeine in emergency rooms desp... m
3 what on earth happened between solange and jay... e
4 nato missile defense is flight tested over hawaii b
from sklearn.feature_extraction.text import TfidfVectorizer # データの分割 train_valid = df[:len(train) + len(valid)] test = df[len(train) + len(valid):] # TfidfVectorizer vec_tfidf = TfidfVectorizer(min_df=10, ngram_range=(1, 2)) # ngram_rangeでTF-IDFを計算する単語の長さを指定 # ベクトル化 X_train_valid = vec_tfidf.fit_transform(train_valid['TITLE']) # testの情報は使わない X_test = vec_tfidf.transform(test['TITLE']) # ベクトルをデータフレームに変換 X_train_valid = pd.DataFrame(X_train_valid.toarray(), columns=vec_tfidf.get_feature_names()) X_test = pd.DataFrame(X_test.toarray(), columns=vec_tfidf.get_feature_names()) # データの分割 X_train = X_train_valid[:len(train)] X_valid = X_train_valid[len(train):] # データの保存 X_train.to_csv('./X_train.txt', sep='\t', index=False) X_valid.to_csv('./X_valid.txt', sep='\t', index=False) X_test.to_csv('./X_test.txt', sep='\t', index=False) print(X_train.head())
--- 出力 ---
0m 0million 0nd 0s 0st ... yuan zac zac efron zendaya zone
0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0
4 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0
[5 rows x 2815 columns]
52. 学習
51で構築した学習データを用いて,ロジスティック回帰モデルを学習せよ.
引き続きscikit-learnを利用して、ロジスティック回帰モデルを学習します。
from sklearn.linear_model import LogisticRegression # モデルの学習 lg = LogisticRegression(random_state=123, max_iter=10000) lg.fit(X_train, train['CATEGORY'])
--- 出力 ---
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=10000,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=123, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
53. 予測
52で学習したロジスティック回帰モデルを用い,与えられた記事見出しからカテゴリとその予測確率を計算するプログラムを実装せよ.
51のテキスト前処理からTF-IDFによるベクトル化までを経たデータセットを入力とする関数を定義します。
import numpy as np def score_lg(lg, X): return [np.max(lg.predict_proba(X), axis=1), lg.predict(X)]
train_pred = score_lg(lg, X_train)
test_pred = score_lg(lg, X_test)
print(train_pred)
--- 出力 ---
[array([0.8402725 , 0.67906432, 0.55642575, ..., 0.86051523, 0.61362406,
0.90827641]), array(['b', 't', 'm', ..., 'b', 'm', 'e'], dtype=object)]
54. 正解率の計測
52で学習したロジスティック回帰モデルの正解率を,学習データおよび評価データ上で計測せよ.
正解率の計算にはscikit-learnのaccuracy_scoreを利用します。
from sklearn.metrics import accuracy_score train_accuracy = accuracy_score(train['CATEGORY'], train_pred[1]) test_accuracy = accuracy_score(test['CATEGORY'], test_pred[1]) print(f'正解率(学習データ):{train_accuracy:.3f}') print(f'正解率(評価データ):{test_accuracy:.3f}')
--- 出力 --- 正解率(学習データ):0.927 正解率(評価データ):0.885
55. 混同行列の作成
52で学習したロジスティック回帰モデルの混同行列(confusion matrix)を,学習データおよび評価データ上で作成せよ.
混同行列もscikit-learnを用いて計算します。 さらに、算出した混同行列をseabornを用いて可視化します。
from sklearn.metrics import confusion_matrix import seaborn as sns import matplotlib.pyplot as plt # 学習データ train_cm = confusion_matrix(train['CATEGORY'], train_pred[1]) print(train_cm) sns.heatmap(train_cm, annot=True, cmap='Blues') plt.show()
--- 出力 --- [[4344 93 8 56] [ 52 4173 2 8] [ 96 125 494 13] [ 192 133 7 888]]

# 評価データ test_cm = confusion_matrix(test['CATEGORY'], test_pred[1]) print(test_cm) sns.heatmap(test_cm, annot=True, cmap='Blues') plt.show()
--- 出力 --- [[528 20 2 13] [ 12 516 1 1] [ 11 26 52 2] [ 38 26 1 87]]

56. 適合率,再現率,F1スコアの計測
52で学習したロジスティック回帰モデルの適合率,再現率,F1スコアを,評価データ上で計測せよ.カテゴリごとに適合率,再現率,F1スコアを求め,カテゴリごとの性能をマイクロ平均(micro-average)とマクロ平均(macro-average)で統合せよ.
from sklearn.metrics import precision_score, recall_score, f1_score def calculate_scores(y_true, y_pred): # 適合率 precision = precision_score(test['CATEGORY'], test_pred[1], average=None, labels=['b', 'e', 't', 'm']) # Noneを指定するとクラスごとの精度をndarrayで返す precision = np.append(precision, precision_score(y_true, y_pred, average='micro')) # 末尾にマイクロ平均を追加 precision = np.append(precision, precision_score(y_true, y_pred, average='macro')) # 末尾にマクロ平均を追加 # 再現率 recall = recall_score(test['CATEGORY'], test_pred[1], average=None, labels=['b', 'e', 't', 'm']) recall = np.append(recall, recall_score(y_true, y_pred, average='micro')) recall = np.append(recall, recall_score(y_true, y_pred, average='macro')) # F1スコア f1 = f1_score(test['CATEGORY'], test_pred[1], average=None, labels=['b', 'e', 't', 'm']) f1 = np.append(f1, f1_score(y_true, y_pred, average='micro')) f1 = np.append(f1, f1_score(y_true, y_pred, average='macro')) # 結果を結合してデータフレーム化 scores = pd.DataFrame({'適合率': precision, '再現率': recall, 'F1スコア': f1}, index=['b', 'e', 't', 'm', 'マイクロ平均', 'マクロ平均']) return scores
print(calculate_scores(test['CATEGORY'], test_pred[1]))
--- 出力 ---
適合率 再現率 F1スコア
b 0.896 0.938 0.917
e 0.878 0.974 0.923
t 0.845 0.572 0.682
m 0.929 0.571 0.707
マイクロ平均 0.885 0.885 0.885
マクロ平均 0.887 0.764 0.807
57. 特徴量の重みの確認
52で学習したロジスティック回帰モデルの中で,重みの高い特徴量トップ10と,重みの低い特徴量トップ10を確認せよ.
学習した各特徴量の重みは、クラスごとにcoef_に格納されています。
features = X_train.columns.values index = [i for i in range(1, 11)] for c, coef in zip(lg.classes_, lg.coef_): print(f'【カテゴリ】{c}') best10 = pd.DataFrame(features[np.argsort(coef)[::-1][:10]], columns=['重要度上位'], index=index).T worst10 = pd.DataFrame(features[np.argsort(coef)[:10]], columns=['重要度下位'], index=index).T display(pd.concat([best10, worst10], axis=0)) print('\n')
--- 出力 ---
【カテゴリ】b
1 2 3 4 5 6 7 8 9 \
重要度上位 bank fed china ecb stocks euro obamacare oil yellen
重要度下位 video ebola the her and she apple google star
10
重要度上位 dollar
重要度下位 microsoft
【カテゴリ】e
1 2 3 4 5 6 7 8 \
重要度上位 kardashian chris her movie star film paul he
重要度下位 us update google study china gm ceo facebook
9 10
重要度上位 wedding she
重要度下位 apple says
【カテゴリ】m
1 2 3 4 5 6 7 8 9 \
重要度上位 ebola study cancer drug mers fda cases cdc could
重要度下位 facebook gm ceo apple bank deal google sales climate
10
重要度上位 cigarettes
重要度下位 twitter
【カテゴリ】t
1 2 3 4 5 6 7 8 \
重要度上位 google facebook apple microsoft climate gm nasa tesla
重要度下位 stocks fed her percent drug american cancer ukraine
9 10
重要度上位 comcast heartbleed
重要度下位 still shares
58. 正則化パラメータの変更
ロジスティック回帰モデルを学習するとき,正則化パラメータを調整することで,学習時の過学習(overfitting)の度合いを制御できる.異なる正則化パラメータでロジスティック回帰モデルを学習し,学習データ,検証データ,および評価データ上の正解率を求めよ.実験の結果は,正則化パラメータを横軸,正解率を縦軸としたグラフにまとめよ.
from tqdm import tqdm result = [] for C in tqdm(np.logspace(-5, 4, 10, base=10)): # モデルの学習 lg = LogisticRegression(random_state=123, max_iter=10000, C=C) lg.fit(X_train, train['CATEGORY']) # 予測値の取得 train_pred = score_lg(lg, X_train) valid_pred = score_lg(lg, X_valid) test_pred = score_lg(lg, X_test) # 正解率の算出 train_accuracy = accuracy_score(train['CATEGORY'], train_pred[1]) valid_accuracy = accuracy_score(valid['CATEGORY'], valid_pred[1]) test_accuracy = accuracy_score(test['CATEGORY'], test_pred[1]) # 結果の格納 result.append([C, train_accuracy, valid_accuracy, test_accuracy])
100%|██████████| 10/10 [07:26<00:00, 44.69s/it] # tqdmを利用して進捗を表示
# 視覚化 result = np.array(result).T plt.plot(result[0], result[1], label='train') plt.plot(result[0], result[2], label='valid') plt.plot(result[0], result[3], label='test') plt.ylim(0, 1.1) plt.ylabel('Accuracy') plt.xscale ('log') plt.xlabel('C') plt.legend() plt.show()

正則化が強すぎる(Cが小さい)と学習が進まず精度が低く、正則化が弱すぎる(Cが大きい)と過学習してしまい、学習用と評価用の精度の差が開いています。 この結果から、適切なCを選ぶことが重要であることが分かります。
59. ハイパーパラメータの探索
学習アルゴリズムや学習パラメータを変えながら,カテゴリ分類モデルを学習せよ.検証データ上の正解率が最も高くなる学習アルゴリズム・パラメータを求めよ.また,その学習アルゴリズム・パラメータを用いたときの評価データ上の正解率を求めよ.
ここでは、正則化の強さを指定するC、および、L1正則化とL2正則化のバランスを指定するl1_ratioを対象にパラメータ探索を行います。
また、最適化にはoptunaを用いています。
!pip install optuna
import optuna # 最適化対象を関数で指定 def objective_lg(trial): # チューニング対象パラメータのセット l1_ratio = trial.suggest_uniform('l1_ratio', 0, 1) C = trial.suggest_loguniform('C', 1e-4, 1e4) # モデルの学習 lg = LogisticRegression(random_state=123, max_iter=10000, penalty='elasticnet', solver='saga', l1_ratio=l1_ratio, C=C) lg.fit(X_train, train['CATEGORY']) # 予測値の取得 valid_pred = score_lg(lg, X_valid) # 正解率の算出 valid_accuracy = accuracy_score(valid['CATEGORY'], valid_pred[1]) return valid_accuracy
# 最適化 study = optuna.create_study(direction='maximize') study.optimize(objective_lg, timeout=3600) # 結果の表示 print('Best trial:') trial = study.best_trial print(' Value: {:.3f}'.format(trial.value)) print(' Params: ') for key, value in trial.params.items(): print(' {}: {}'.format(key, value))
--- 出力 ---
Best trial:
Value: 0.892
Params:
l1_ratio: 0.23568685768996045
C: 4.92280374981671
探索したパラメータで再度モデルを学習し、正解率を確認します。
# パラメータの設定 l1_ratio = trial.params['l1_ratio'] C = trial.params['C'] # モデルの学習 lg = LogisticRegression(random_state=123, max_iter=10000, penalty='elasticnet', solver='saga', l1_ratio=l1_ratio, C=C) lg.fit(X_train, train['CATEGORY']) # 予測値の取得 train_pred = score_lg(lg, X_train) valid_pred = score_lg(lg, X_valid) test_pred = score_lg(lg, X_test) # 正解率の算出 train_accuracy = accuracy_score(train['CATEGORY'], train_pred[1]) valid_accuracy = accuracy_score(valid['CATEGORY'], valid_pred[1]) test_accuracy = accuracy_score(test['CATEGORY'], test_pred[1]) print(f'正解率(学習データ):{train_accuracy:.3f}') print(f'正解率(検証データ):{valid_accuracy:.3f}') print(f'正解率(評価データ):{test_accuracy:.3f}')
--- 出力 --- 正解率(学習データ):0.966 正解率(検証データ):0.892 正解率(評価データ):0.895
デフォルトのパラメータで学習した際の評価用データの正解率は0.885であったため、適切なパラメータの採用により精度が向上したことが分かります。
今回はさらにXGBoostも試してみることにします。 なお、こちらはパラメータ探索は行わず、決め打ちのパラメータでモデルを学習しています。
!pip install xgboost
import xgboost as xgb params={'objective': 'multi:softmax', 'num_class': 4, 'eval_metric': 'mlogloss', 'colsample_bytree': 1.0, 'colsample_bylevel': 0.5, 'min_child_weight': 1, 'subsample': 0.9, 'eta': 0.1, 'max_depth': 5, 'gamma': 0.0, 'alpha': 0.0, 'lambda': 1.0, 'num_round': 1000, 'early_stopping_rounds': 50, 'verbosity': 0 } # XGBoost用にフォーマット変換 category_dict = {'b': 0, 'e': 1, 't':2, 'm':3} y_train = train['CATEGORY'].map(lambda x: category_dict[x]) y_valid = valid['CATEGORY'].map(lambda x: category_dict[x]) y_test = test['CATEGORY'].map(lambda x: category_dict[x]) dtrain = xgb.DMatrix(X_train, label=y_train) dvalid = xgb.DMatrix(X_valid, label=y_valid) dtest = xgb.DMatrix(X_test, label=y_test) # モデルの学習 num_round = params.pop('num_round') early_stopping_rounds = params.pop('early_stopping_rounds') watchlist = [(dtrain, 'train'), (dvalid, 'eval')] model = xgb.train(params, dtrain, num_round, evals=watchlist, early_stopping_rounds=early_stopping_rounds)
# 予測値の取得 train_pred = model.predict(dtrain, ntree_limit=model.best_ntree_limit) valid_pred = model.predict(dvalid, ntree_limit=model.best_ntree_limit) test_pred = model.predict(dtest, ntree_limit=model.best_ntree_limit) # 正解率の算出 train_accuracy = accuracy_score(y_train, train_pred) valid_accuracy = accuracy_score(y_valid, valid_pred) test_accuracy = accuracy_score(y_test, test_pred) print(f'正解率(学習データ):{train_accuracy:.3f}') print(f'正解率(検証データ):{valid_accuracy:.3f}') print(f'正解率(評価データ):{test_accuracy:.3f}')
--- 出力 --- 正解率(学習データ):0.963 正解率(検証データ):0.873 正解率(評価データ):0.873
理解を深めるためのオススメ教材
全100問の解答はこちら
【言語処理100本ノック 2020】第5章: 係り受け解析【Python】

自然言語処理の問題集として有名な言語処理100本ノックの2020年版の解答例です。 この記事では、以下の第1章から第10章のうち、「第5章: 係り受け解析」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNNとCNN
- 第10章: 機械翻訳
環境設定
コードの実行はGoogle Colaboratoryで行います。 以降の解答の実行結果をすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
第5章: 係り受け解析
日本語Wikipediaの「人工知能」に関する記事からテキスト部分を抜き出したファイルがai.ja.zipに収録されている. この文章をCaboChaやKNP等のツールを利用して係り受け解析を行い,その結果をai.ja.txt.parsedというファイルに保存せよ.このファイルを読み込み,以下の問に対応するプログラムを実装せよ.
まずは指定のデータをダウンロードします。 Google Colaboratoryのセル上で下記のコマンドを実行すると、現在のディレクトリに対象のファイルがダウンロードされます。
!wget https://nlp100.github.io/data/ai.ja.zip !unzip ai.ja.zip
続いて、CaboChaおよびCaboChaの実行に必要なMeCabとCRF++をインストールします。
# MeCabのインストール !apt install mecab libmecab-dev mecab-ipadic-utf8
# CRF++のソースファイルのダウンロード・解凍・インストール import gdown url = "https://drive.google.com/uc?id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ" output = "crfpp.tar.gz" gdown.download(url, output, quiet=False) !tar xvf crfpp.tar.gz %cd /content/CRF++-0.58 !./configure && make && make install && ldconfig
# CaboChaのソースファイルのダウンロード・解凍・インストール url = "https://drive.google.com/uc?id=0B4y35FiV1wh7SDd1Q1dUQkZQaUU" output = "cabocha-0.69.tar.bz2" gdown.download(url, output, quiet=False) !tar -xvf cabocha-0.69.tar.bz2 %cd /content/cabocha-0.69 !./configure -with-charset=utf-8 && make && make check && make install && ldconfig
インストールが完了したら、早速係り受け解析を行います。
以下のコマンドを実行することにより、ai.ja.txtを係り受け解析した結果が、ai.ja.txt.parsedとして出力されます。
%cd /content !cabocha -f1 -o ai.ja.txt.parsed ai.ja.txt
出力結果を確認します。
# 行数の確認 !wc -l ./ai.ja.txt.parsed
--- 出力 --- 11744 ./ai.ja.txt.parsed
# 先頭15行の確認 !head -15 ./ai.ja.txt.parsed
--- 出力 --- * 0 -1D 1/1 0.000000 人工 名詞,一般,*,*,*,*,人工,ジンコウ,ジンコー 知能 名詞,一般,*,*,*,*,知能,チノウ,チノー EOS EOS * 0 17D 1/1 0.388993 人工 名詞,一般,*,*,*,*,人工,ジンコウ,ジンコー 知能 名詞,一般,*,*,*,*,知能,チノウ,チノー * 1 17D 2/3 0.613549 ( 記号,括弧開,*,*,*,*,(,(,( じん 名詞,一般,*,*,*,*,じん,ジン,ジン こうち 名詞,一般,*,*,*,*,こうち,コウチ,コーチ のう 助詞,終助詞,*,*,*,*,のう,ノウ,ノー 、 記号,読点,*,*,*,*,、,、,、 、 記号,読点,*,*,*,*,、,、,、
一部うまくいっていませんね。
40. 係り受け解析結果の読み込み(形態素)
形態素を表すクラスMorphを実装せよ.このクラスは表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をメンバ変数に持つこととする.さらに,係り受け解析の結果(ai.ja.txt.parsed)を読み込み,各文をMorphオブジェクトのリストとして表現し,冒頭の説明文の形態素列を表示せよ.
class Morph: def __init__(self, morph): surface, attr = morph.split('\t') attr = attr.split(',') self.surface = surface self.base = attr[6] self.pos = attr[0] self.pos1 = attr[1]
filename = './ai.ja.txt.parsed' sentences = [] morphs = [] with open(filename, mode='r') as f: for line in f: if line[0] == '*': # 係り受け関係を表す行:スキップ continue elif line != 'EOS\n': # 文末以外:Morphを適用し形態素リストに追加 morphs.append(Morph(line)) else: # 文末:形態素リストを文リストに追加 sentences.append(morphs) morphs = [] # 確認 for m in sentences[2]: print(vars(m))
--- 出力 ---
{'surface': '人工', 'base': '人工', 'pos': '名詞', 'pos1': '一般'}
{'surface': '知能', 'base': '知能', 'pos': '名詞', 'pos1': '一般'}
{'surface': '(', 'base': '(', 'pos': '記号', 'pos1': '括弧開'}
{'surface': 'じん', 'base': 'じん', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'こうち', 'base': 'こうち', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'のう', 'base': 'のう', 'pos': '助詞', 'pos1': '終助詞'}
{'surface': '、', 'base': '、', 'pos': '記号', 'pos1': '読点'}
{'surface': '、', 'base': '、', 'pos': '記号', 'pos1': '読点'}
{'surface': 'AI', 'base': '*\n', 'pos': '名詞', 'pos1': '一般'}
{'surface': '〈', 'base': '〈', 'pos': '記号', 'pos1': '括弧開'}
{'surface': 'エーアイ', 'base': '*\n', 'pos': '名詞', 'pos1': '固有名詞'}
{'surface': '〉', 'base': '〉', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': ')', 'base': ')', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': 'と', 'base': 'と', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': 'は', 'base': 'は', 'pos': '助詞', 'pos1': '係助詞'}
{'surface': '、', 'base': '、', 'pos': '記号', 'pos1': '読点'}
{'surface': '「', 'base': '「', 'pos': '記号', 'pos1': '括弧開'}
{'surface': '『', 'base': '『', 'pos': '記号', 'pos1': '括弧開'}
{'surface': '計算', 'base': '計算', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': '(', 'base': '(', 'pos': '記号', 'pos1': '括弧開'}
{'surface': ')', 'base': ')', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': '』', 'base': '』', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': 'という', 'base': 'という', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': '概念', 'base': '概念', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'と', 'base': 'と', 'pos': '助詞', 'pos1': '並立助詞'}
{'surface': '『', 'base': '『', 'pos': '記号', 'pos1': '括弧開'}
{'surface': 'コンピュータ', 'base': 'コンピュータ', 'pos': '名詞', 'pos1': '一般'}
{'surface': '(', 'base': '(', 'pos': '記号', 'pos1': '括弧開'}
{'surface': ')', 'base': ')', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': '』', 'base': '』', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': 'という', 'base': 'という', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': '道具', 'base': '道具', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'を', 'base': 'を', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': '用い', 'base': '用いる', 'pos': '動詞', 'pos1': '自立'}
{'surface': 'て', 'base': 'て', 'pos': '助詞', 'pos1': '接続助詞'}
{'surface': '『', 'base': '『', 'pos': '記号', 'pos1': '括弧開'}
{'surface': '知能', 'base': '知能', 'pos': '名詞', 'pos1': '一般'}
{'surface': '』', 'base': '』', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': 'を', 'base': 'を', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': '研究', 'base': '研究', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': 'する', 'base': 'する', 'pos': '動詞', 'pos1': '自立'}
{'surface': '計算', 'base': '計算', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': '機', 'base': '機', 'pos': '名詞', 'pos1': '接尾'}
{'surface': '科学', 'base': '科学', 'pos': '名詞', 'pos1': '一般'}
{'surface': '(', 'base': '(', 'pos': '記号', 'pos1': '括弧開'}
{'surface': ')', 'base': ')', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': 'の', 'base': 'の', 'pos': '助詞', 'pos1': '連体化'}
{'surface': '一', 'base': '一', 'pos': '名詞', 'pos1': '数'}
{'surface': '分野', 'base': '分野', 'pos': '名詞', 'pos1': '一般'}
{'surface': '」', 'base': '」', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': 'を', 'base': 'を', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': '指す', 'base': '指す', 'pos': '動詞', 'pos1': '自立'}
{'surface': '語', 'base': '語', 'pos': '名詞', 'pos1': '一般'}
{'surface': '。', 'base': '。', 'pos': '記号', 'pos1': '句点'}
{'surface': '「', 'base': '「', 'pos': '記号', 'pos1': '括弧開'}
{'surface': '言語', 'base': '言語', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'の', 'base': 'の', 'pos': '助詞', 'pos1': '連体化'}
{'surface': '理解', 'base': '理解', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': 'や', 'base': 'や', 'pos': '助詞', 'pos1': '並立助詞'}
{'surface': '推論', 'base': '推論', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': '、', 'base': '、', 'pos': '記号', 'pos1': '読点'}
{'surface': '問題', 'base': '問題', 'pos': '名詞', 'pos1': 'ナイ形容詞語幹'}
{'surface': '解決', 'base': '解決', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': 'など', 'base': 'など', 'pos': '助詞', 'pos1': '副助詞'}
{'surface': 'の', 'base': 'の', 'pos': '助詞', 'pos1': '連体化'}
{'surface': '知的', 'base': '知的', 'pos': '名詞', 'pos1': '一般'}
{'surface': '行動', 'base': '行動', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': 'を', 'base': 'を', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': '人間', 'base': '人間', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'に', 'base': 'に', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': '代わっ', 'base': '代わる', 'pos': '動詞', 'pos1': '自立'}
{'surface': 'て', 'base': 'て', 'pos': '助詞', 'pos1': '接続助詞'}
{'surface': 'コンピューター', 'base': 'コンピューター', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'に', 'base': 'に', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': '行わ', 'base': '行う', 'pos': '動詞', 'pos1': '自立'}
{'surface': 'せる', 'base': 'せる', 'pos': '動詞', 'pos1': '接尾'}
{'surface': '技術', 'base': '技術', 'pos': '名詞', 'pos1': '一般'}
{'surface': '」', 'base': '」', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': '、', 'base': '、', 'pos': '記号', 'pos1': '読点'}
{'surface': 'または', 'base': 'または', 'pos': '接続詞', 'pos1': '*'}
{'surface': '、', 'base': '、', 'pos': '記号', 'pos1': '読点'}
{'surface': '「', 'base': '「', 'pos': '記号', 'pos1': '括弧開'}
{'surface': '計算', 'base': '計算', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': '機', 'base': '機', 'pos': '名詞', 'pos1': '接尾'}
{'surface': '(', 'base': '(', 'pos': '記号', 'pos1': '括弧開'}
{'surface': 'コンピュータ', 'base': 'コンピュータ', 'pos': '名詞', 'pos1': '一般'}
{'surface': ')', 'base': ')', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': 'による', 'base': 'による', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': '知的', 'base': '知的', 'pos': '名詞', 'pos1': '形容動詞語幹'}
{'surface': 'な', 'base': 'だ', 'pos': '助動詞', 'pos1': '*'}
{'surface': '情報処理', 'base': '情報処理', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'システム', 'base': 'システム', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'の', 'base': 'の', 'pos': '助詞', 'pos1': '連体化'}
{'surface': '設計', 'base': '設計', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': 'や', 'base': 'や', 'pos': '助詞', 'pos1': '並立助詞'}
{'surface': '実現', 'base': '実現', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': 'に関する', 'base': 'に関する', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': '研究', 'base': '研究', 'pos': '名詞', 'pos1': 'サ変接続'}
{'surface': '分野', 'base': '分野', 'pos': '名詞', 'pos1': '一般'}
{'surface': '」', 'base': '」', 'pos': '記号', 'pos1': '括弧閉'}
{'surface': 'と', 'base': 'と', 'pos': '助詞', 'pos1': '格助詞'}
{'surface': 'も', 'base': 'も', 'pos': '助詞', 'pos1': '係助詞'}
{'surface': 'さ', 'base': 'する', 'pos': '動詞', 'pos1': '自立'}
{'surface': 'れる', 'base': 'れる', 'pos': '動詞', 'pos1': '接尾'}
{'surface': '。', 'base': '。', 'pos': '記号', 'pos1': '句点'}
41. 係り受け解析結果の読み込み(文節・係り受け)
40に加えて,文節を表すクラスChunkを実装せよ.このクラスは形態素(Morphオブジェクト)のリスト(morphs),係り先文節インデックス番号(dst),係り元文節インデックス番号のリスト(srcs)をメンバ変数に持つこととする.さらに,入力テキストの係り受け解析結果を読み込み,1文をChunkオブジェクトのリストとして表現し,冒頭の説明文の文節の文字列と係り先を表示せよ.本章の残りの問題では,ここで作ったプログラムを活用せよ.
文章は文(sentence)オブジェクトのリストで表され、文オブジェクトは文節(chunk)オブジェクトのリストを要素に持ち、文節オブジェクトは形態素(morph)オブジェクトのリストを要素に持つ階層構造を考え、ここでは指定のクラスChunkに加え、Sentenceを実装しています。
なお、Chunkオブジェクトの要素である係り元文節インデックス番号のリスト(srcs)の作成には1文のすべての文節情報を必要とするため、Sentenceオブジェクトの初期化時に作成しています。
class Chunk(): def __init__(self, morphs, dst): self.morphs = morphs self.dst = dst self.srcs = [] class Sentence(): def __init__(self, chunks): self.chunks = chunks for i, chunk in enumerate(self.chunks): if chunk.dst != -1: self.chunks[chunk.dst].srcs.append(i)
filename = './ai.ja.txt.parsed' sentences = [] chunks = [] morphs = [] with open(filename, mode='r') as f: for line in f: if line[0] == '*': # 係り受け関係を表す行:直前の文節の情報にChunkを適用し文節リストに追加 + 直後の文節の係り先を取得 if len(morphs) > 0: chunks.append(Chunk(morphs, dst)) morphs = [] dst = int(line.split(' ')[2].rstrip('D')) elif line != 'EOS\n': # 文末以外:Morphを適用し形態素リストに追加 morphs.append(Morph(line)) else: # 文末:直前の文節の情報にChunkを適用し文節リストに追加 + 文節リストにSentenceを適用し文リストに追加 chunks.append(Chunk(morphs, dst)) sentences.append(Sentence(chunks)) morphs = [] chunks = [] dst = None # 確認 for chunk in sentences[2].chunks: print([morph.surface for morph in chunk.morphs], chunk.dst, chunk.srcs)
--- 出力 --- ['人工', '知能'] 17 [] ['(', 'じん', 'こうち', 'のう', '、', '、'] 17 [] ['AI'] 3 [] ['〈', 'エーアイ', '〉', ')', 'と', 'は', '、'] 17 [2] ['「', '『', '計算'] 5 [] ['(', ')', '』', 'という'] 9 [4] ['概念', 'と'] 9 [] ['『', 'コンピュータ'] 8 [] ['(', ')', '』', 'という'] 9 [7] ['道具', 'を'] 10 [5, 6, 8] ['用い', 'て'] 12 [9] ['『', '知能', '』', 'を'] 12 [] ['研究', 'する'] 13 [10, 11] ['計算', '機', '科学'] 14 [12] ['(', ')', 'の'] 15 [13] ['一', '分野', '」', 'を'] 16 [14] ['指す'] 17 [15] ['語', '。'] 34 [0, 1, 3, 16] ['「', '言語', 'の'] 20 [] ['理解', 'や'] 20 [] ['推論', '、'] 21 [18, 19] ['問題', '解決', 'など', 'の'] 22 [20] ['知的', '行動', 'を'] 24 [21] ['人間', 'に'] 24 [] ['代わっ', 'て'] 26 [22, 23] ['コンピューター', 'に'] 26 [] ['行わ', 'せる'] 27 [24, 25] ['技術', '」', '、', 'または', '、'] 34 [26] ['「', '計算', '機'] 29 [] ['(', 'コンピュータ', ')', 'による'] 31 [28] ['知的', 'な'] 31 [] ['情報処理', 'システム', 'の'] 33 [29, 30] ['設計', 'や'] 33 [] ['実現', 'に関する'] 34 [31, 32] ['研究', '分野', '」', 'と', 'も'] 35 [17, 27, 33] ['さ', 'れる', '。'] -1 [34]
42. 係り元と係り先の文節の表示
係り元の文節と係り先の文節のテキストをタブ区切り形式ですべて抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
sentence = sentences[2] for chunk in sentence.chunks: if int(chunk.dst) != -1: modifier = ''.join([morph.surface if morph.pos != '記号' else '' for morph in chunk.morphs]) modifiee = ''.join([morph.surface if morph.pos != '記号' else '' for morph in sentence.chunks[int(chunk.dst)].morphs]) print(modifier, modifiee, sep='\t')
--- 出力 --- 人工知能 語 じんこうちのう 語 AI エーアイとは エーアイとは 語 計算 という という 道具を 概念と 道具を コンピュータ という という 道具を 道具を 用いて 用いて 研究する 知能を 研究する 研究する 計算機科学 計算機科学 の の 一分野を 一分野を 指す 指す 語 語 研究分野とも 言語の 推論 理解や 推論 推論 問題解決などの 問題解決などの 知的行動を 知的行動を 代わって 人間に 代わって 代わって 行わせる コンピューターに 行わせる 行わせる 技術または 技術または 研究分野とも 計算機 コンピュータによる コンピュータによる 情報処理システムの 知的な 情報処理システムの 情報処理システムの 実現に関する 設計や 実現に関する 実現に関する 研究分野とも 研究分野とも される
43. 名詞を含む文節が動詞を含む文節に係るものを抽出
名詞を含む文節が,動詞を含む文節に係るとき,これらをタブ区切り形式で抽出せよ.ただし,句読点などの記号は出力しないようにせよ.
sentence = sentences[2] for chunk in sentence.chunks: if int(chunk.dst) != -1: modifier = ''.join([morph.surface if morph.pos != '記号' else '' for morph in chunk.morphs]) modifier_pos = [morph.pos for morph in chunk.morphs] modifiee = ''.join([morph.surface if morph.pos != '記号' else '' for morph in sentence.chunks[int(chunk.dst)].morphs]) modifiee_pos = [morph.pos for morph in sentence.chunks[int(chunk.dst)].morphs] if '名詞' in modifier_pos and '動詞' in modifiee_pos: print(modifier, modifiee, sep='\t')
--- 出力 --- 道具を 用いて 知能を 研究する 一分野を 指す 知的行動を 代わって 人間に 代わって コンピューターに 行わせる 研究分野とも される
44. 係り受け木の可視化
与えられた文の係り受け木を有向グラフとして可視化せよ.可視化には,Graphviz等を用いるとよい.
係り元と係り先の文節のペアを作成し、pydotのgraph_from_edgesに渡すことで、グラフを作成しています。
なお、表層形そのままでは1文内に同じ文字列の文節が複数回出てきた場合に区別できないため、末尾にIDを付与して表示しています。
# 日本語表示用フォントのインストール !apt install fonts-ipafont-gothic
import pydot from IPython.display import Image,display_png from graphviz import Digraph sentence = sentences[7] edges = [] for id, chunk in enumerate(sentence.chunks): if int(chunk.dst) != -1: modifier = ''.join([morph.surface if morph.pos != '記号' else '' for morph in chunk.morphs] + ['(' + str(id) + ')']) modifiee = ''.join([morph.surface if morph.pos != '記号' else '' for morph in sentence.chunks[int(chunk.dst)].morphs] + ['(' + str(chunk.dst) + ')']) edges.append([modifier, modifiee]) n = pydot.Node('node') n.fontname = 'IPAGothic' g = pydot.graph_from_edges(edges, directed=True) g.add_node(n) g.write_png('./ans44.png') display_png(Image('./ans44.png'))
45. 動詞の格パターンの抽出
今回用いている文章をコーパスと見なし,日本語の述語が取りうる格を調査したい. 動詞を述語,動詞に係っている文節の助詞を格と考え,述語と格をタブ区切り形式で出力せよ. ただし,出力は以下の仕様を満たすようにせよ.
- 動詞を含む文節において,最左の動詞の基本形を述語とする
- 述語に係る助詞を格とする
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
このプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
- コーパス中で頻出する述語と格パターンの組み合わせ
- 「行う」「なる」「与える」という動詞の格パターン(コーパス中で出現頻度の高い順に並べよ)
with open('./ans45.txt', 'w') as f: for sentence in sentences: for chunk in sentence.chunks: for morph in chunk.morphs: if morph.pos == '動詞': # chunkの左から順番に動詞を探す cases = [] for src in chunk.srcs: # 見つけた動詞の係り元chunkから助詞を探す cases = cases + [morph.surface for morph in sentence.chunks[src].morphs if morph.pos == '助詞'] if len(cases) > 0: # 助詞が見つかった場合は重複除去後辞書順にソートして出力 cases = sorted(list(set(cases))) line = '{}\t{}'.format(morph.base, ' '.join(cases)) print(line, file=f) break
# 確認 !cat ./ans45.txt | sort | uniq -c | sort -nr | head -n 10
--- 出力 ---
136 する を
100 する て を
44 する て で は
15 ある が て に は
9 行う を
7 呼ぶ も
6 基づく に
6 なる から で と
6 する から を
5 関わる に も
!cat ./ans45.txt | grep '行う' | sort | uniq -c | sort -nr | head -n 5
--- 出力 ---
9 行う を
5 行う て に
4 行う て に を
1 行う まで を
1 行う から
!cat ./ans45.txt | grep 'なる' | sort | uniq -c | sort -nr | head -n 5
--- 出力 ---
8 なる が と
6 なる に
5 なる が て と
1 異なる が で
1 異なる も
!cat ./ans45.txt | grep '与える' | sort | uniq -c | sort -nr | head -n 5
--- 出力 ---
1 与える が など に
1 与える に は を
1 与える が に
46. 動詞の格フレーム情報の抽出
45のプログラムを改変し,述語と格パターンに続けて項(述語に係っている文節そのもの)をタブ区切り形式で出力せよ.45の仕様に加えて,以下の仕様を満たすようにせよ.
- 項は述語に係っている文節の単語列とする(末尾の助詞を取り除く必要はない)
- 述語に係る文節が複数あるときは,助詞と同一の基準・順序でスペース区切りで並べる
with open('./ans46.txt', 'w') as f: for sentence in sentences: for chunk in sentence.chunks: for morph in chunk.morphs: if morph.pos == '動詞': # chunkの左から順番に動詞を探す cases = [] modi_chunks = [] for src in chunk.srcs: # 見つけた動詞の係り元chunkから助詞を探す case = [morph.surface for morph in sentence.chunks[src].morphs if morph.pos == '助詞'] if len(case) > 0: # 助詞を含むchunkの場合は助詞と項を取得 cases = cases + case modi_chunks.append(''.join(morph.surface for morph in sentence.chunks[src].morphs if morph.pos != '記号')) if len(cases) > 0: # 助詞が1つ以上見つかった場合は重複除去後辞書順にソートし、項と合わせて出力 cases = sorted(list(set(cases))) line = '{}\t{}\t{}'.format(morph.base, ' '.join(cases), ' '.join(modi_chunks)) print(line, file=f) break
# 確認 !cat ./ans46.txt | head -n 10
--- 出力 --- 用いる を 道具を する て を 用いて 知能を 指す を 一分野を 代わる に を 知的行動を 人間に 行う て に 代わって コンピューターに する と も 研究分野とも 述べる で に の は 解説で 佐藤理史は 次のように する で を 知的能力を コンピュータ上で する を 推論判断を する を 画像データを
47. 機能動詞構文のマイニング
動詞のヲ格にサ変接続名詞が入っている場合のみに着目したい.46のプログラムを以下の仕様を満たすように改変せよ.
- 「サ変接続名詞+を(助詞)」で構成される文節が動詞に係る場合のみを対象とする 述語は「サ変接続名詞+を+動詞の基本形」とし,文節中に複数の動詞があるときは,最左の動詞を用いる
- 述語に係る助詞(文節)が複数あるときは,すべての助詞をスペース区切りで辞書順に並べる
- 述語に係る文節が複数ある場合は,すべての項をスペース区切りで並べる(助詞の並び順と揃えよ)
このプログラムの出力をファイルに保存し,以下の事項をUNIXコマンドを用いて確認せよ.
- コーパス中で頻出する述語(サ変接続名詞+を+動詞)
- コーパス中で頻出する述語と助詞パターン
with open('./ans47.txt', 'w') as f: for sentence in sentences: for chunk in sentence.chunks: for morph in chunk.morphs: if morph.pos == '動詞': # chunkの左から順番に動詞を探す for i, src in enumerate(chunk.srcs): # 見つけた動詞の係り元chunkが「サ変接続名詞+を」で構成されるか確認 if len(sentence.chunks[src].morphs) == 2 and sentence.chunks[src].morphs[0].pos1 == 'サ変接続' and sentence.chunks[src].morphs[1].surface == 'を': predicate = ''.join([sentence.chunks[src].morphs[0].surface, sentence.chunks[src].morphs[1].surface, morph.base]) cases = [] modi_chunks = [] for src_r in chunk.srcs[:i] + chunk.srcs[i + 1:]: # 残りの係り元chunkから助詞を探す case = [morph.surface for morph in sentence.chunks[src_r].morphs if morph.pos == '助詞'] if len(case) > 0: # 助詞を含むchunkの場合は助詞と項を取得 cases = cases + case modi_chunks.append(''.join(morph.surface for morph in sentence.chunks[src_r].morphs if morph.pos != '記号')) if len(cases) > 0: # 助詞が1つ以上見つかった場合は重複除去後辞書順にソートし、項と合わせて出力 cases = sorted(list(set(cases))) line = '{}\t{}\t{}'.format(predicate, ' '.join(cases), ' '.join(modi_chunks)) print(line, file=f) break
# 確認 !cat ./ans47.txt | cut -f 1 | sort | uniq -c | sort -nr | head -n 10
--- 出力 ---
3 注目を集める
2 運転をする
2 話をする
2 研究をいる
2 特許をする
1 開発を行う
1 進化を見せる
1 進化をいる
1 追及を受ける
1 議論を行う
!cat ./ans47.txt | cut -f 1,2 | sort | uniq -c | sort -nr | head -n 10
--- 出力 ---
2 話をする は
2 特許をする が に まで
2 注目を集める が
1 開発を行う は
1 運転をする て に
1 運転をする に
1 進化を見せる て において は
1 進化をいる て において は
1 追及を受ける て で と とともに は
1 議論を行う まで
48. 名詞から根へのパスの抽出
文中のすべての名詞を含む文節に対し,その文節から構文木の根に至るパスを抽出せよ. ただし,構文木上のパスは以下の仕様を満たすものとする.
- 各文節は(表層形の)形態素列で表現する
- パスの開始文節から終了文節に至るまで,各文節の表現を” -> “で連結する
sentence = sentences[2] for chunk in sentence.chunks: if '名詞' in [morph.pos for morph in chunk.morphs]: # chunkが名詞を含むか確認 path = [''.join(morph.surface for morph in chunk.morphs if morph.pos != '記号')] while chunk.dst != -1: # 名詞を含むchunkを先頭に、dstを根まで順に辿ってリストに追加 path.append(''.join(morph.surface for morph in sentence.chunks[chunk.dst].morphs if morph.pos != '記号')) chunk = sentence.chunks[chunk.dst] print(' -> '.join(path))
--- 出力 --- 人工知能 -> 語 -> 研究分野とも -> される じんこうちのう -> 語 -> 研究分野とも -> される AI -> エーアイとは -> 語 -> 研究分野とも -> される エーアイとは -> 語 -> 研究分野とも -> される 計算 -> という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される 概念と -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される コンピュータ -> という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される 道具を -> 用いて -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される 知能を -> 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される 研究する -> 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される 計算機科学 -> の -> 一分野を -> 指す -> 語 -> 研究分野とも -> される 一分野を -> 指す -> 語 -> 研究分野とも -> される 語 -> 研究分野とも -> される 言語の -> 推論 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術または -> 研究分野とも -> される 理解や -> 推論 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術または -> 研究分野とも -> される 推論 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術または -> 研究分野とも -> される 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術または -> 研究分野とも -> される 知的行動を -> 代わって -> 行わせる -> 技術または -> 研究分野とも -> される 人間に -> 代わって -> 行わせる -> 技術または -> 研究分野とも -> される コンピューターに -> 行わせる -> 技術または -> 研究分野とも -> される 技術または -> 研究分野とも -> される 計算機 -> コンピュータによる -> 情報処理システムの -> 実現に関する -> 研究分野とも -> される コンピュータによる -> 情報処理システムの -> 実現に関する -> 研究分野とも -> される 知的な -> 情報処理システムの -> 実現に関する -> 研究分野とも -> される 情報処理システムの -> 実現に関する -> 研究分野とも -> される 設計や -> 実現に関する -> 研究分野とも -> される 実現に関する -> 研究分野とも -> される 研究分野とも -> される
49. 名詞間の係り受けパスの抽出
文中のすべての名詞句のペアを結ぶ最短係り受けパスを抽出せよ.ただし,名詞句ペアの文節番号が
(
- 問題48と同様に,パスは開始文節から終了文節に至るまでの各文節の表現(表層形の形態素列)を” -> “で連結して表現する
- 文節
また,係り受けパスの形状は,以下の2通りが考えられる.
- 文節
- 上記以外で,文節
で交わる場合: 文節
例えば、
i -> a -> b -> j -> 根であれば、i -> a -> b -> ji -> a -> k -> 根、j -> b -> k -> 根であれば、i -> a | j -> b | k
とし、、
の名詞をそれぞれX、Yに変換して表示すればよいことになります。
from itertools import combinations import re sentence = sentences[2] nouns = [] for i, chunk in enumerate(sentence.chunks): if '名詞' in [morph.pos for morph in chunk.morphs]: # 名詞を含む文節を抽出 nouns.append(i) for i, j in combinations(nouns, 2): # 名詞を含む文節のペアごとにパスを作成 path_i = [] path_j = [] while i != j: if i < j: path_i.append(i) i = sentence.chunks[i].dst else: path_j.append(j) j = sentence.chunks[j].dst if len(path_j) == 0: # 1つ目のケース chunk_X = ''.join([morph.surface if morph.pos != '名詞' else 'X' for morph in sentence.chunks[path_i[0]].morphs]) chunk_Y = ''.join([morph.surface if morph.pos != '名詞' else 'Y' for morph in sentence.chunks[i].morphs]) chunk_X = re.sub('X+', 'X', chunk_X) chunk_Y = re.sub('Y+', 'Y', chunk_Y) path_XtoY = [chunk_X] + [''.join(morph.surface for morph in sentence.chunks[n].morphs) for n in path_i[1:]] + [chunk_Y] print(' -> '.join(path_XtoY)) else: # 2つ目のケース chunk_X = ''.join([morph.surface if morph.pos != '名詞' else 'X' for morph in sentence.chunks[path_i[0]].morphs]) chunk_Y = ''.join([morph.surface if morph.pos != '名詞' else 'Y' for morph in sentence.chunks[path_j[0]].morphs]) chunk_k = ''.join([morph.surface for morph in sentence.chunks[i].morphs]) chunk_X = re.sub('X+', 'X', chunk_X) chunk_Y = re.sub('Y+', 'Y', chunk_Y) path_X = [chunk_X] + [''.join(morph.surface for morph in sentence.chunks[n].morphs) for n in path_i[1:]] path_Y = [chunk_Y] + [''.join(morph.surface for morph in sentence.chunks[n].morphs) for n in path_j[1:]] print(' | '.join([' -> '.join(path_X), ' -> '.join(path_Y), chunk_k]))
--- 出力 --- X | (Yのう、、 | 語。 X | Y -> 〈エーアイ〉)とは、 | 語。 X | 〈Y〉)とは、 | 語。 X | 「『Y -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X | Yと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X | 『Y -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X | Yを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X | 『Y』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X | Yする -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X | Y -> ()の -> 一分野」を -> 指す | 語。 X | Y」を -> 指す | 語。 X -> Y。 X -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 語。 | Y」、または、 | 研究分野」とも X -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも X -> 語。 | Yの -> 実現に関する | 研究分野」とも X -> 語。 | Yや -> 実現に関する | 研究分野」とも X -> 語。 | Yに関する | 研究分野」とも X -> 語。 -> Y」とも (Xのう、、 | Y -> 〈エーアイ〉)とは、 | 語。 (Xのう、、 | 〈Y〉)とは、 | 語。 (Xのう、、 | 「『Y -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 (Xのう、、 | Yと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 (Xのう、、 | 『Y -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 (Xのう、、 | Yを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 (Xのう、、 | 『Y』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 (Xのう、、 | Yする -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 (Xのう、、 | Y -> ()の -> 一分野」を -> 指す | 語。 (Xのう、、 | Y」を -> 指す | 語。 (Xのう、、 -> Y。 (Xのう、、 -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも (Xのう、、 -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも (Xのう、、 -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも (Xのう、、 -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも (Xのう、、 -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも (Xのう、、 -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも (Xのう、、 -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも (Xのう、、 -> 語。 | Y」、または、 | 研究分野」とも (Xのう、、 -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも (Xのう、、 -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも (Xのう、、 -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも (Xのう、、 -> 語。 | Yの -> 実現に関する | 研究分野」とも (Xのう、、 -> 語。 | Yや -> 実現に関する | 研究分野」とも (Xのう、、 -> 語。 | Yに関する | 研究分野」とも (Xのう、、 -> 語。 -> Y」とも X -> 〈Y〉)とは、 X -> 〈エーアイ〉)とは、 | 「『Y -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X -> 〈エーアイ〉)とは、 | Yと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X -> 〈エーアイ〉)とは、 | 『Y -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X -> 〈エーアイ〉)とは、 | Yを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X -> 〈エーアイ〉)とは、 | 『Y』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X -> 〈エーアイ〉)とは、 | Yする -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 X -> 〈エーアイ〉)とは、 | Y -> ()の -> 一分野」を -> 指す | 語。 X -> 〈エーアイ〉)とは、 | Y」を -> 指す | 語。 X -> 〈エーアイ〉)とは、 -> Y。 X -> 〈エーアイ〉)とは、 -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Y」、または、 | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Yの -> 実現に関する | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Yや -> 実現に関する | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 | Yに関する | 研究分野」とも X -> 〈エーアイ〉)とは、 -> 語。 -> Y」とも 〈X〉)とは、 | 「『Y -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 〈X〉)とは、 | Yと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 〈X〉)とは、 | 『Y -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 〈X〉)とは、 | Yを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 〈X〉)とは、 | 『Y』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 〈X〉)とは、 | Yする -> 計算機科学 -> ()の -> 一分野」を -> 指す | 語。 〈X〉)とは、 | Y -> ()の -> 一分野」を -> 指す | 語。 〈X〉)とは、 | Y」を -> 指す | 語。 〈X〉)とは、 -> Y。 〈X〉)とは、 -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 〈X〉)とは、 -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 〈X〉)とは、 -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 〈X〉)とは、 -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 〈X〉)とは、 -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 〈X〉)とは、 -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 〈X〉)とは、 -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも 〈X〉)とは、 -> 語。 | Y」、または、 | 研究分野」とも 〈X〉)とは、 -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも 〈X〉)とは、 -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも 〈X〉)とは、 -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも 〈X〉)とは、 -> 語。 | Yの -> 実現に関する | 研究分野」とも 〈X〉)とは、 -> 語。 | Yや -> 実現に関する | 研究分野」とも 〈X〉)とは、 -> 語。 | Yに関する | 研究分野」とも 〈X〉)とは、 -> 語。 -> Y」とも 「『X -> ()』という | Yと | 道具を 「『X -> ()』という | 『Y -> ()』という | 道具を 「『X -> ()』という -> Yを 「『X -> ()』という -> 道具を -> 用いて | 『Y』を | 研究する 「『X -> ()』という -> 道具を -> 用いて -> Yする 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> Y 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> Y」を 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> Y。 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y」、または、 | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yの -> 実現に関する | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 実現に関する | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに関する | 研究分野」とも 「『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 -> Y」とも Xと | 『Y -> ()』という | 道具を Xと -> Yを Xと -> 道具を -> 用いて | 『Y』を | 研究する Xと -> 道具を -> 用いて -> Yする Xと -> 道具を -> 用いて -> 研究する -> Y Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> Y」を Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> Y。 Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y」、または、 | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yの -> 実現に関する | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 実現に関する | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに関する | 研究分野」とも Xと -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 -> Y」とも 『X -> ()』という -> Yを 『X -> ()』という -> 道具を -> 用いて | 『Y』を | 研究する 『X -> ()』という -> 道具を -> 用いて -> Yする 『X -> ()』という -> 道具を -> 用いて -> 研究する -> Y 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> Y」を 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> Y。 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y」、または、 | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yの -> 実現に関する | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 実現に関する | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに関する | 研究分野」とも 『X -> ()』という -> 道具を -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 -> Y」とも Xを -> 用いて | 『Y』を | 研究する Xを -> 用いて -> Yする Xを -> 用いて -> 研究する -> Y Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> Y」を Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> Y。 Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y」、または、 | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yの -> 実現に関する | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 実現に関する | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに関する | 研究分野」とも Xを -> 用いて -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 -> Y」とも 『X』を -> Yする 『X』を -> 研究する -> Y 『X』を -> 研究する -> 計算機科学 -> ()の -> Y」を 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> Y。 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y」、または、 | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yの -> 実現に関する | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 実現に関する | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに関する | 研究分野」とも 『X』を -> 研究する -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 -> Y」とも Xする -> Y Xする -> 計算機科学 -> ()の -> Y」を Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> Y。 Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Y」、または、 | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yの -> 実現に関する | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 実現に関する | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 | Yに関する | 研究分野」とも Xする -> 計算機科学 -> ()の -> 一分野」を -> 指す -> 語。 -> Y」とも X -> ()の -> Y」を X -> ()の -> 一分野」を -> 指す -> Y。 X -> ()の -> 一分野」を -> 指す -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Y」、または、 | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Yの -> 実現に関する | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Yや -> 実現に関する | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 | Yに関する | 研究分野」とも X -> ()の -> 一分野」を -> 指す -> 語。 -> Y」とも X」を -> 指す -> Y。 X」を -> 指す -> 語。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X」を -> 指す -> 語。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X」を -> 指す -> 語。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X」を -> 指す -> 語。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X」を -> 指す -> 語。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X」を -> 指す -> 語。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X」を -> 指す -> 語。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも X」を -> 指す -> 語。 | Y」、または、 | 研究分野」とも X」を -> 指す -> 語。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X」を -> 指す -> 語。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X」を -> 指す -> 語。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも X」を -> 指す -> 語。 | Yの -> 実現に関する | 研究分野」とも X」を -> 指す -> 語。 | Yや -> 実現に関する | 研究分野」とも X」を -> 指す -> 語。 | Yに関する | 研究分野」とも X」を -> 指す -> 語。 -> Y」とも X。 | 「Yの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X。 | Yや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X。 | Y、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X。 | Yなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X。 | Yを -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X。 | Yに -> 代わって -> 行わせる -> 技術」、または、 | 研究分野」とも X。 | Yに -> 行わせる -> 技術」、または、 | 研究分野」とも X。 | Y」、または、 | 研究分野」とも X。 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X。 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X。 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも X。 | Yの -> 実現に関する | 研究分野」とも X。 | Yや -> 実現に関する | 研究分野」とも X。 | Yに関する | 研究分野」とも X。 -> Y」とも 「Xの | Yや | 推論、 「Xの -> Y、 「Xの -> 推論、 -> Yなどの 「Xの -> 推論、 -> 問題解決などの -> Yを 「Xの -> 推論、 -> 問題解決などの -> 知的行動を | Yに | 代わって 「Xの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって | Yに | 行わせる 「Xの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> Y」、または、 「Xの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも 「Xの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも 「Xの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも 「Xの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yの -> 実現に関する | 研究分野」とも 「Xの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yや -> 実現に関する | 研究分野」とも 「Xの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yに関する | 研究分野」とも 「Xの -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 -> Y」とも Xや -> Y、 Xや -> 推論、 -> Yなどの Xや -> 推論、 -> 問題解決などの -> Yを Xや -> 推論、 -> 問題解決などの -> 知的行動を | Yに | 代わって Xや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって | Yに | 行わせる Xや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> Y」、または、 Xや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも Xや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yの -> 実現に関する | 研究分野」とも Xや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yや -> 実現に関する | 研究分野」とも Xや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yに関する | 研究分野」とも Xや -> 推論、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 -> Y」とも X、 -> Yなどの X、 -> 問題解決などの -> Yを X、 -> 問題解決などの -> 知的行動を | Yに | 代わって X、 -> 問題解決などの -> 知的行動を -> 代わって | Yに | 行わせる X、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> Y」、または、 X、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも X、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yの -> 実現に関する | 研究分野」とも X、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yや -> 実現に関する | 研究分野」とも X、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yに関する | 研究分野」とも X、 -> 問題解決などの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 -> Y」とも Xなどの -> Yを Xなどの -> 知的行動を | Yに | 代わって Xなどの -> 知的行動を -> 代わって | Yに | 行わせる Xなどの -> 知的行動を -> 代わって -> 行わせる -> Y」、または、 Xなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも Xなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yの -> 実現に関する | 研究分野」とも Xなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yや -> 実現に関する | 研究分野」とも Xなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 | Yに関する | 研究分野」とも Xなどの -> 知的行動を -> 代わって -> 行わせる -> 技術」、または、 -> Y」とも Xを | Yに | 代わって Xを -> 代わって | Yに | 行わせる Xを -> 代わって -> 行わせる -> Y」、または、 Xを -> 代わって -> 行わせる -> 技術」、または、 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xを -> 代わって -> 行わせる -> 技術」、または、 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xを -> 代わって -> 行わせる -> 技術」、または、 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも Xを -> 代わって -> 行わせる -> 技術」、または、 | Yの -> 実現に関する | 研究分野」とも Xを -> 代わって -> 行わせる -> 技術」、または、 | Yや -> 実現に関する | 研究分野」とも Xを -> 代わって -> 行わせる -> 技術」、または、 | Yに関する | 研究分野」とも Xを -> 代わって -> 行わせる -> 技術」、または、 -> Y」とも Xに -> 代わって | Yに | 行わせる Xに -> 代わって -> 行わせる -> Y」、または、 Xに -> 代わって -> 行わせる -> 技術」、または、 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xに -> 代わって -> 行わせる -> 技術」、または、 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xに -> 代わって -> 行わせる -> 技術」、または、 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも Xに -> 代わって -> 行わせる -> 技術」、または、 | Yの -> 実現に関する | 研究分野」とも Xに -> 代わって -> 行わせる -> 技術」、または、 | Yや -> 実現に関する | 研究分野」とも Xに -> 代わって -> 行わせる -> 技術」、または、 | Yに関する | 研究分野」とも Xに -> 代わって -> 行わせる -> 技術」、または、 -> Y」とも Xに -> 行わせる -> Y」、または、 Xに -> 行わせる -> 技術」、または、 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xに -> 行わせる -> 技術」、または、 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも Xに -> 行わせる -> 技術」、または、 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも Xに -> 行わせる -> 技術」、または、 | Yの -> 実現に関する | 研究分野」とも Xに -> 行わせる -> 技術」、または、 | Yや -> 実現に関する | 研究分野」とも Xに -> 行わせる -> 技術」、または、 | Yに関する | 研究分野」とも Xに -> 行わせる -> 技術」、または、 -> Y」とも X」、または、 | 「Y -> (コンピュータ)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X」、または、 | (Y)による -> 情報処理システムの -> 実現に関する | 研究分野」とも X」、または、 | Yな -> 情報処理システムの -> 実現に関する | 研究分野」とも X」、または、 | Yの -> 実現に関する | 研究分野」とも X」、または、 | Yや -> 実現に関する | 研究分野」とも X」、または、 | Yに関する | 研究分野」とも X」、または、 -> Y」とも 「X -> (Y)による 「X -> (コンピュータ)による | Yな | 情報処理システムの 「X -> (コンピュータ)による -> Yの 「X -> (コンピュータ)による -> 情報処理システムの | Yや | 実現に関する 「X -> (コンピュータ)による -> 情報処理システムの -> Yに関する 「X -> (コンピュータ)による -> 情報処理システムの -> 実現に関する -> Y」とも (X)による | Yな | 情報処理システムの (X)による -> Yの (X)による -> 情報処理システムの | Yや | 実現に関する (X)による -> 情報処理システムの -> Yに関する (X)による -> 情報処理システムの -> 実現に関する -> Y」とも Xな -> Yの Xな -> 情報処理システムの | Yや | 実現に関する Xな -> 情報処理システムの -> Yに関する Xな -> 情報処理システムの -> 実現に関する -> Y」とも Xの | Yや | 実現に関する Xの -> Yに関する Xの -> 実現に関する -> Y」とも Xや -> Yに関する Xや -> 実現に関する -> Y」とも Xに関する -> Y」とも
理解を深めるためのオススメ教材


youwht 翔泳社 2021年12月06日頃
全100問の解答はこちら