



Human Motion Diffusion Modelによるテキストから3Dモーションの自動生成

この記事では、Human Motion Diffusion Modelによって、人の動きの3Dアニメーションモデルを生成する方法を紹介します。
Human Motion Diffusion Modelとは
Human Motion Diffusion Modelは、拡散モデルの仕組みを利用して人の3Dモーションを生成するモデルです。
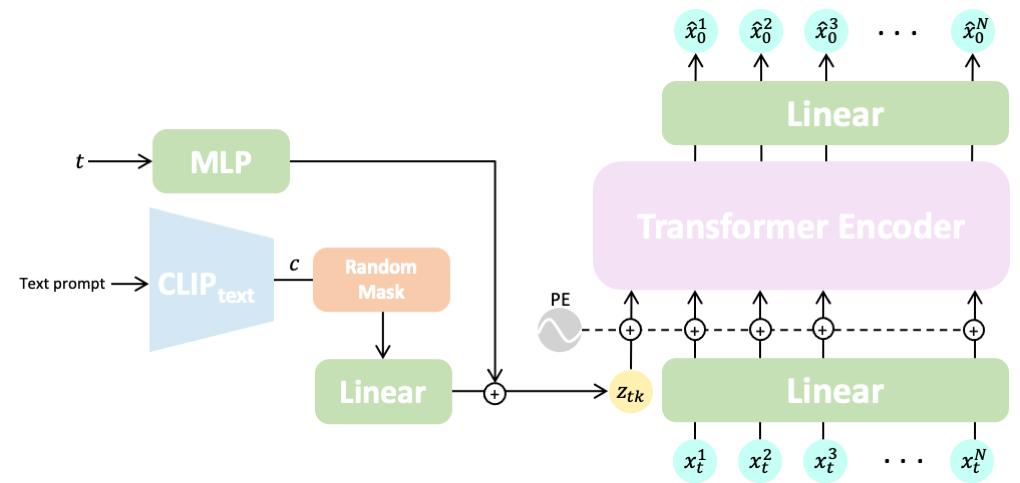
学習時の予測対象を工夫することにより、よりリアルなモーションの生成を実現しているところに大きな特徴があります。ここでは、入力したテキストに沿った3Dモーションを生成するText-to-Motionのデモのみ行いますが、特定のクラスのアクションの3Dモーションを生成するAction-to-Motion、モーションをテキストで修正するMotion Editingも同じモデルで実現することができます。理論面の詳細は論文をご覧ください。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
環境設定
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、推論時にGPUを利用することができます。
※ 2022年10月よりGoogle Colaboratoryの料金プランがこちらの内容に変更されました。ご利用の際はご注意ください。
conda環境を利用するため、condacolabをインストールします。colab上でcondaを利用する方法については、下記の記事をご覧ください。
!pip install -q condacolab
import condacolab
condacolab.install()
続いて、リポジトリをクローンし、conda仮想環境を構築します。
!git clone https://github.com/GuyTevet/motion-diffusion-model.git %cd motion-diffusion-model !conda env create -f environment.yml
必要なライブラリ等をインストールします。
%%bash eval "$(conda shell.bash hook)" conda activate mdm python -m spacy download en_core_web_sm pip install git+https://github.com/openai/CLIP.git
最後に、描画に必要なSMPLモデルのパラメータをダウンロードしておきます。
!bash prepare/download_smpl_files.sh
モデル設定
学習済みのパラメータをダウンロードします。
import gdown # 学習済みパラメータのダウンロード url = 'https://drive.google.com/uc?id=1PE0PK8e5a5j-7-Xhs5YET5U5pGh0c821' output = 'humanml_trans_enc_512.zip' gdown.download(url, output, quiet=False) !unzip humanml_trans_enc_512.zip -d ./save/
推論
モーションを生成します。text_promptでプロンプトを指定することができます。
%%bash eval "$(conda shell.bash hook)" conda activate mdm pip install ipykernel python -m sample --model_path ./save/humanml_trans_enc_512/model000200000.pt --text_prompt "the person walked forward and is picking up his toolbox."
出力された結果がこちら。
前掲のYoutubeの動画のように、人型のメッシュで動画化するためのobjファイルやsmplパラメータを生成したい場合は、以下のコードを実行します。input_pathには、上記のコードで出力されたmp4ファイルのパスを入力します。
%%bash eval "$(conda shell.bash hook)" conda activate mdm python -m visualize.render_mesh --input_path /content/motion-diffusion-model/save/humanml_trans_enc_512/samples_humanml_trans_enc_512_000200000_seed10_the_person_walked_forward_and_is_picking_up_his_toolbox/sample00_rep00.mp4
まとめ
テキストから3Dモデルを生成し、さらにそれをテキストで動かす、といった技術があっという間に現実的になってきました。今後の発展に要注目です。

チーム・カルポ 秀和システム 2021年08月31日頃
参考文献
Google Colaboratoryでファイルをアップロード・ダウンロードする方法

この記事ではGoogle Colaboratoryでファイルをアップロード・ダウンロードする2つの方法を紹介します。
ColaboratoryのUIを利用する方法
Colaboratoryは画面上で直感的にファイルを操作することが可能です。
アップロード
まず、左側のサイドバーに表示されているファイルマークをクリックします。
表示されたエリアに、ローカルディレクトリからファイルをドラッグ&ドロップします。
ファイル名が表示されれば、アップロード完了です。デフォルトでは、/content/というディレクトリにアップロードされるため、ファイル名がsample_image.pngであれば、セル上で/content/sample_image.pngを指定することで、アップロードしたファイルを操作することができます。
ダウンロード
先ほどと同様に左側のサイドバーに表示されているファイルマークをクリックします。対象のファイル名にカーソルを合わせると、右端に三つの点が表示されるので、クリックしてダウンロードを選択するとファイルのダウンロードが開始されます。
セルから操作する方法
セルに特定のコードを記載することで、アップロード・ダウンロードを行うことも可能です。
アップロード
セルから以下のコードを実行すると、ファイル選択ボタンが表示されます。対象のファイルを選択すると、colab上の現在のディレクトリにファイルがアップロードされます。
from google.colab import files uploaded = files.upload()
なお、アップロードしたファイル名は、以下のように取得することができるので、後続処理でファイル名を入力する必要はありません。
file_name = list(uploaded.keys())[0]
ダウンロード
セルから以下のコードを実行すると、対象ファイルがダウンロードされます。
from google.colab import files files.download('対象ファイルのパス' )
長い処理が終了した後に、結果を自動的にダウンロードしたい場合などは、あらかじめこちらを記載しておくとセッション落ちで結果を取り損なうこともなくなり便利です。
ディレクトリごとダウンロードしたい場合は、以下のようにzipなどにまとめておけば、同様にダウンロードできます。
import shutil shutil.make_archive('zipファイルの保存パス', 'zip', '圧縮したいディレクトリ') # ex: shutil.make_archive('result_for_download', 'zip', '/content/result')

渡辺 宙志 講談社 2020年12月17日頃
Google Colaboratoryでcondaを利用する方法

この記事ではGoogle Colaboratoryでcondaを利用する2つの方法を紹介します。
概要
condaはpipのような、パッケージ管理用のコマンドです。colab上でライブラリをインストールする場合、通常pipを使えば足りることがほとんどです。しかし、誰かのgithubのコードを実行しようとする場合に、conda環境設定用ファイルが配布されているときは、condaを利用した方が便利なケースもあります。
そこで、以下ではcolab上でcondaを利用する方法を解説します。
Minicondaをインストールする方法
condaコマンドは、デフォルトのcolabでは使えません。そこで、condaコマンドを含むMinicondaのインストーラを取得し、colab上にインストールするのが一つ目の方法です。
!wget -c https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh !chmod +x Miniconda3-latest-Linux-x86_64.sh !bash ./Miniconda3-latest-Linux-x86_64.sh -b -f -p /usr/local
condacolabを利用する方法
condacolabというcolabでcondaを利用するためのライブラリも存在しています。こちらは、以下のコードを実行することにより、condaが利用可能になります。
!pip install -q condacolab
import condacolab
condacolab.install()
【参考】conda仮想環境の利用方法
最後に、特定のリポジトリをクローンして、仮想環境を構築し、スクリプトを実行するまでの流れの一例を紹介します。ここでは、https://github.com/amaru_ai/example.gitというリポジトリにenvironment.ymlという環境設定用のyamlファイルとrun.pyというpythonファイルが存在しているとします(仮のURLです。実際には存在しません)。
まず、リポジトリをクローンして、そのディレクトリに移動します。
!git clone https://github.com/amaru_ai/example.git %cd example
続いて、conda環境を構築します。
!conda env create -f environment.yml
仮想環境に入り、pythonファイルを実行します。
%%bash eval "$(conda shell.bash hook)" conda activate example_env python run.py
example_envは仮想環境の名前です。自分でつけることもできますが、通常はenvironment.ymlで指定されています。conda env createコマンド実行時のログに環境名が表示されるので、そちらを参照してください。
渡辺 宙志 講談社 2020年12月17日頃
【言語処理100本ノック 2020】第4章: 形態素解析【Python】

自然言語処理の問題集として有名な言語処理100本ノックの2020年版の解答例です。 この記事では、以下の第1章から第10章のうち、「第4章: 形態素解析」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNNとCNN
- 第10章: 機械翻訳
環境設定
コードの実行はGoogle Colaboratoryで行います。 以降の解答の実行結果をすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
第4章: 形態素解析
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
まずは指定のデータをダウンロードします。 Google Colaboratoryのセル上で下記のコマンドを実行すると、現在のディレクトリに対象のファイルがダウンロードされます。
!wget https://nlp100.github.io/data/neko.txt
続いて、MeCabをインストールします。
!apt install mecab libmecab-dev mecab-ipadic-utf8
インストールが完了したら、早速形態素解析を行います。
以下のコマンドを実行することにより、neko.txtを形態素解析した結果が、neko.txt.mecabとして出力されます。
!mecab -o ./neko.txt.mecab ./neko.txt
出力結果を確認します。
# 行数の確認 !wc -l ./neko.txt.mecab
--- 出力 --- 226266 ./neko.txt.mecab
# 先頭15行の確認 !head -15 ./neko.txt.mecab
--- 出力 ---
一 名詞,数,*,*,*,*,一,イチ,イチ
記号,一般,*,*,*,*,*
EOS
記号,一般,*,*,*,*,*
EOS
記号,空白,*,*,*,*, , ,
吾輩 名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
猫 名詞,一般,*,*,*,*,猫,ネコ,ネコ
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
ある 助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル
。 記号,句点,*,*,*,*,。,。,。
記号,一般,*,*,*,*,*
EOS
名前 名詞,一般,*,*,*,*,名前,ナマエ,ナマエ
30. 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
filename = './neko.txt.mecab' sentences = [] morphs = [] with open(filename, mode='r') as f: for line in f: # 1行ずつ読込 if line != 'EOS\n': # 文末以外:形態素解析情報を辞書型に格納して形態素リストに追加 fields = line.split('\t') if len(fields) != 2 or fields[0] == '': # 文頭以外の空白と改行文字はスキップ continue else: attr = fields[1].split(',') morph = {'surface': fields[0], 'base': attr[6], 'pos': attr[0], 'pos1': attr[1]} morphs.append(morph) else: # 文末:形態素リストを文リストに追加 sentences.append(morphs) morphs = [] # 確認 for morph in sentences[2]: print(morph)
--- 出力 ---
{'surface': '\u3000', 'base': '\u3000', 'pos': '記号', 'pos1': '空白'}
{'surface': '吾輩', 'base': '吾輩', 'pos': '名詞', 'pos1': '代名詞'}
{'surface': 'は', 'base': 'は', 'pos': '助詞', 'pos1': '係助詞'}
{'surface': '猫', 'base': '猫', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'で', 'base': 'だ', 'pos': '助動詞', 'pos1': '*'}
{'surface': 'ある', 'base': 'ある', 'pos': '助動詞', 'pos1': '*'}
{'surface': '。', 'base': '。', 'pos': '記号', 'pos1': '句点'}
31. 動詞
動詞の表層形をすべて抽出せよ.
以降、30で作成したsentencesに対して処理を行っていきます。
ここで結果を格納しているset型は、集合を表すデータ型であり重複を許しません。ですので、何も考えずに要素を追加していっても自然と重複のない結果を得られるため、本問のようなケースで便利です。
ans = set() for sentence in sentences: for morph in sentence: if morph['pos'] == '動詞': ans.add(morph['surface']) # set型なので重複しない要素のみ保持していく # 確認 print(f'動詞の表層形の種類: {len(ans)}\n') for v in list(ans)[:10]: print(v)
--- 出力 --- 動詞の表層形の種類: 3893 儲け 忍ん 並べる 気がつい 候え やい 隔て 保っ まつわっ から
32. 動詞の原形
動詞の基本形をすべて抽出せよ.
ans = set() for sentence in sentences: for morph in sentence: if morph['pos'] == '動詞': ans.add(morph['base']) # 確認 print(f'動詞の基本形の種類: {len(ans)}\n') for v in list(ans)[:10]: print(v)
--- 出力 --- 動詞の基本形の種類: 2300 並べる 待ち受ける 拗じる 打てる 応ずる 引き受ける 畳み込む 刺し通す 生える 言い付ける
33. 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
ans = set() for sentence in sentences: for i in range(1, len(sentence) - 1): if sentence[i - 1]['pos'] == '名詞' and sentence[i]['surface'] == 'の' and sentence[i + 1]['pos'] == '名詞': ans.add(sentence[i - 1]['surface'] + sentence[i]['surface'] + sentence[i + 1]['surface']) # 確認 print(f'「名詞+の+名詞」の種類: {len(ans)}\n') for n in list(ans)[:10]: print(n)
--- 出力 --- 「名詞+の+名詞」の種類: 4924 辟易の体 介の半面 自分の嫌い 警察の厄介 法のうち 事物の適 世人の探偵 護の恐れ 二つの要素 立てのフロック
34. 名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
文ごとに、最初の形態素から順に以下のルールを適用し、名詞の連接を最長一致で抽出しています。
- 名詞であれば
nounsに連結し、連結数(num)をカウント - 名詞以外の場合、ここまでの連結数が2以上であれば出力し、
nounsとnumを初期化 - それ以外の場合、
nounsとnumを初期化
ans = set() for sentence in sentences: nouns = '' num = 0 for morph in sentence: if morph['pos'] == '名詞': # 最初の形態素から順に、名詞であればnounsに連結し、連結数(num)をカウント nouns = ''.join([nouns, morph['surface']]) num += 1 elif num >= 2: # 名詞以外、かつここまでの連結数が2以上の場合は出力し、nounsとnumを初期化 ans.add(nouns) nouns = '' num = 0 else: # それ以外の場合、nounsとnumを初期化 nouns = '' num = 0 if num >= 2: ans.add(nouns) # 確認 print(f'連接名詞の種類: {len(ans)}\n') for n in list(ans)[:10]: print(n)
--- 出力 --- 連接名詞の種類: 4454 かん猪口 通り今日 必竟世間 二枚かけ 君シャンパン 近付 ばかよう 木槿垣 今十年 刺激以外
35. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
from collections import defaultdict ans = defaultdict(int) for sentence in sentences: for morph in sentence: if morph['pos'] != '記号': ans[morph['base']] += 1 # 単語数の更新(初登場の単語であれば1をセット) ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) # 確認 for w in ans[:10]: print(w)
--- 出力 ---
('の', 9194)
('て', 6848)
('は', 6420)
('に', 6243)
('を', 6071)
('だ', 5972)
('と', 5508)
('が', 5337)
('た', 4267)
('する', 3657)
36. 頻度上位10語
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
matplotlibで日本語を表示させるため、japanize_matplotlibをインストールしておきます。
!pip install japanize_matplotlib
そして、35と同様に出現頻度を集計し、棒グラフで視覚化します。
import matplotlib.pyplot as plt import japanize_matplotlib ans = defaultdict(int) for sentence in sentences: for morph in sentence: if morph['pos'] != '記号': ans[morph['base']] += 1 # 単語数の更新(初登場の単語であれば1をセット) ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) keys = [a[0] for a in ans[0:10]] values = [a[1] for a in ans[0:10]] plt.figure(figsize=(8, 4)) plt.bar(keys, values) plt.show()
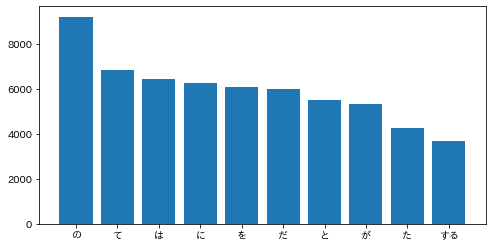
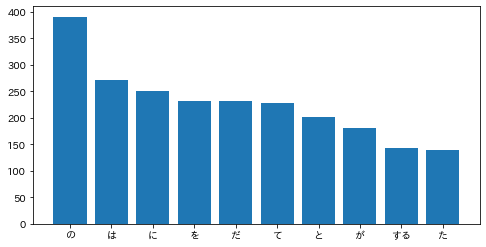
37. 「猫」と共起頻度の高い上位10語
「猫」とよく共起する(共起頻度が高い)10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
ここでは特に指示がないため品詞を選択していませんが、目的によっては助詞等を除くことによって、より意味のありそうな結果になると思います。
ans = defaultdict(int) for sentence in sentences: if '猫' in [morph['surface'] for morph in sentence]: # 文章の形態素に「猫」が含まれる場合のみ辞書に追加 for morph in sentence: if morph['pos'] != '記号': ans[morph['base']] += 1 # 単語数の更新(初登場の単語であれば1をセット) del ans['猫'] ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) keys = [a[0] for a in ans[0:10]] values = [a[1] for a in ans[0:10]] plt.figure(figsize=(8, 4)) plt.bar(keys, values) plt.show()
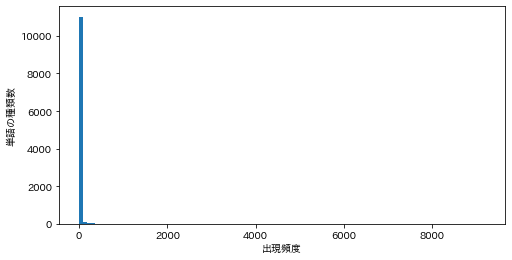
38. ヒストグラム
単語の出現頻度のヒストグラム(横軸に出現頻度,縦軸に出現頻度をとる単語の種類数を棒グラフで表したもの)を描け.
ans = defaultdict(int) for sentence in sentences: for morph in sentence: if morph['pos'] != '記号': ans[morph['base']] += 1 # 単語数の更新(初登場の単語であれば1をセット) ans = ans.values() plt.figure(figsize=(8, 4)) plt.hist(ans, bins=100) plt.xlabel('出現頻度') plt.ylabel('単語の種類数') plt.show()
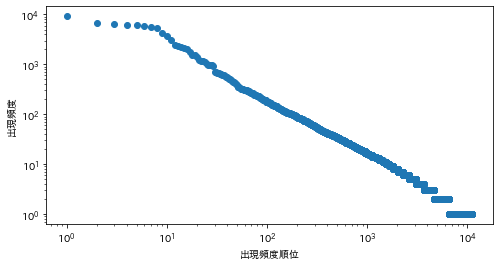
39. Zipfの法則
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
import math ans = defaultdict(int) for sentence in sentences: for morph in sentence: if morph['pos'] != '記号': ans[morph['base']] += 1 ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) ranks = [r + 1 for r in range(len(ans))] values = [a[1] for a in ans] plt.figure(figsize=(8, 4)) plt.scatter(ranks, values) plt.xscale('log') plt.yscale('log') plt.xlabel('出現頻度順位') plt.ylabel('出現頻度') plt.show()
理解を深めるためのオススメ教材


youwht 翔泳社 2021年12月06日頃
全100問の解答はこちら
【言語処理100本ノック 2020】第3章: 正規表現【Python】

自然言語処理の問題集として有名な言語処理100本ノックの2020年版の解答例です。 この記事では、以下の第1章から第10章のうち、「第3章: 正規表現」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNNとCNN
- 第10章: 機械翻訳
環境設定
コードの実行はGoogle Colaboratoryで行います。 以降の解答の実行結果をすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
第3章: 正規表現
Wikipediaの記事を以下のフォーマットで書き出したファイルjawiki-country.json.gzがある.
- 1行に1記事の情報がJSON形式で格納される
- 各行には記事名が”title”キーに,記事本文が”text”キーの辞書オブジェクトに格納され,そのオブジェクトがJSON形式で書き出される
- ファイル全体はgzipで圧縮される
以下の処理を行うプログラムを作成せよ.
まずは指定のデータをダウンロードします。 Google Colaboratoryのセル上で下記のコマンドを実行すると、現在のディレクトリに対象の圧縮ファイルがダウンロードされます。
!wget https://nlp100.github.io/data/jawiki-country.json.gz
解凍し、内容を確認します。
!gunzip ./jawiki-country.json.gz
# 行数の確認 !wc -l ./jawiki-country.json
--- 出力 --- 248 ./jawiki-country.json
# 先頭行の確認 !head -1 ./jawiki-country.json
--- 出力 ---
{"title": "エジプト", "text": "{{otheruses|主に現代のエジプト・アラブ共和国|古代|古代エジプト}}\n{{基礎情報 国\n|略名 =エジプト\n|漢字書き=埃及\n|日本語国名 =エジプト・アラブ共和国\n|公式国名 ={{lang|ar|'''جمهورية مصر العربية'''}}\n|国旗画像 =Flag of Egypt.svg\n|国章画像 =[[ファイル:Coat_of_arms_of_Egypt.svg|100px|エジプトの国章]]\n|国章リンク =([[エジプトの国章|国章]])\n|標語 =なし\n|位置画像 =Egypt (orthographic projection).svg\n|公用語 =[[アラビア語]]\n|首都 =[[File:Flag of Cairo.svg|24px]] [[カイロ]]\n|最大都市 =カイロ\n|元首等肩書 =[[近代エジプトの国家元首の一覧|大統領]]\n|元首等氏名 =[[アブドルファッターフ・アッ=シーシー]]\n|首相等肩書 ={{ill2|エジプトの首相|en|Prime Minister of Egypt|label=首相}}\n|首相等氏名 ={{仮リンク|ムスタファ・マドブーリー|ar|مصطفى مدبولي|en|Moustafa Madbouly}}\n|面積順位 =29\n|面積大きさ =1 E12\n|面積値 =1,010,408\n|水面積率 =0.6%\n|人口統計年 =2012\n|人口順位 =\n|人口大きさ =1 E7\n|人口値 =1億人\n|人口密度値 =76\n|GDP統計年元 =2018\n|GDP値元 =4兆4,374億<ref name=\"economy\">IMF Data and Statistics 2020年2月3日閲覧([https://www.imf.org/external/pubs/ft/weo/2019/02/weodata/weorept.aspx?sy=2017&ey=2024&scsm=1&ssd=1&sort=country&ds=.&br=1&c=469&s=NGDP%2CNGDPD%2CPPPGDP%2CNGDPDPC%2CPPPPC&grp=0&a=&pr.x=57&pr.y=4])</ref>\n|GDP統計年MER =2018\n|GDP順位MER =45\n|GDP値MER =2,496億<ref name=\"economy\" />\n|GDP統計年 =2018\n|GDP順位 =21\n|GDP値 =1兆2,954億<ref name=\"economy\" />\n|GDP/人 =13,358<ref name=\"economy\" />\n|建国形態 =[[独立]]<br /> - 日付\n|建国年月日 =[[イギリス]]より<br />[[1922年]][[2月28日]]\n|通貨 =[[エジプト・ポンド]] (£)\n|通貨コード =EGP\n|時間帯 = +2\n|夏時間 =なし\n|国歌 =[[エジプトの国歌|{{lang|ar|بلادي، بلادي، بلادي}}]]{{ar icon}}<br>''我が祖国''<br>{{center|[[file:Bilady, Bilady, Bilady.ogg]]}}\n|ISO 3166-1 = EG / EGY\n|ccTLD =[[.eg]]\n|国際電話番号 =20\n|注記 =\n}}\n'''エジプト・アラブ共和国'''(エジプト・アラブきょうわこく、{{lang-ar|جمهورية مصر العربية}})、通称'''エジプト'''は、[[中東]]([[アラブ世界]])および[[北アフリカ]]にある[[共和国]]。[[首都]]は[[カイロ]]。\n\n[[アフリカ大陸]]では北東端に位置し、西に[[リビア]]、南に[[スーダン]]、北東の[[シナイ半島]]では[[イスラエル]]、[[ガザ地区]]と[[国境]]を接する。北は[[地中海]]、東は[[紅海]]に面している。南北に流れる[[ナイル川]]の[[河谷]]と[[三角州|デルタ]]地帯([[ナイル・デルタ]])のほかは、国土の大部分の95%以上が[[砂漠]]である<ref>[https://kotobank.jp/word/エジプト-36404 エジプト]藤井宏志『日本大百科全書』小学館 2020年2月1日閲覧</ref>。ナイル河口の東に地中海と紅海を結ぶ[[スエズ運河]]がある。\n\n== 国号 ==\n正式名称は[[アラビア語]]で {{lang|ar|'''جمهورية مصر العربية'''}}(ラテン[[翻字]]: {{transl|ar|DIN|Ǧumhūrīyah Miṣr al-ʿarabīyah}})。通称は {{lang|ar|'''مصر'''}}([[フスハー|標準語]]: {{transl|ar|DIN|Miṣr}} ミスル、[[アラビア語エジプト方言|エジプト方言]]ほか、口語アラビア語: {{IPA|mɑsˤɾ}} マスル)。[[コプト語]]: {{Lang|cop|Ⲭⲏⲙⲓ}}(Khemi ケーミ)。\n\nアラビア語の名称'''ミスル'''は、古代から[[セム語派|セム語]]でこの地を指した名称である。なお、セム語の一派である[[ヘブライ語]]では、[[双数形]]の'''ミスライム'''({{lang|he|מצרים}}, ミツライム)となる。\n\n公式の英語表記は '''Arab Republic of Egypt'''。通称 '''Egypt''' {{IPA-en|ˈiːdʒɨpt|}}。形容詞はEgyptian {{IPA-en|ɨˈdʒɪpʃ''ə''n|}}。エジプトの呼称は、古代[[エジプト語]]のフート・カア・プタハ([[プタハ]]神の魂の神殿)から転じてこの地を指すようになったギリシャ語の単語である、[[ギリシャ神話]]の[[アイギュプトス (ギリシア神話)|アイギュプトス]]にちなむ。\n\n[[日本語]]の表記はエジプト・アラブ共和国。通称[[wikt:エジプト|エジプト]]。[[漢字]]では'''埃及'''と表記し、'''埃'''と略す。この[[国名の漢字表記一覧|漢字表記]]は、[[漢文]]がそのまま日本語や[[中国語]]などに輸入されたものである。英語では「イージプト」と呼ばれる。\n\n* [[1882年]] - 1922年 ({{仮リンク|イギリス領エジプト|en|History of Egypt under the British}})\n* 1922年 - 1953年 [[エジプト王国]]\n* 1953年 - 1958年 [[エジプト共和国]]\n* 1958年 - 1971年 [[アラブ連合共和国]]\n* 1971年 - 現在 エジプト・アラブ共和国\n\n== 歴史 ==\n{{Main|エジプトの歴史}}\n\n=== 古代エジプト ===\n[[ファイル:All Gizah Pyramids.jpg|thumb|300px|right|[[ギーザ|ギザ]]の[[三大ピラミッド]]]]\n[[ファイル:Egyptiska hieroglyfer, Nordisk familjebok.png|thumb|260px|right|[[ヒエログリフ]]]]\n{{Main|古代エジプト}}\n\n「エジプトはナイルの賜物」という[[古代ギリシア]]の[[歴史家]][[ヘロドトス]]の言葉で有名なように、エジプトは豊かな[[ナイル川]]の[[三角州|デルタ]]に支えられ[[古代エジプト|古代エジプト文明]]を発展させてきた。エジプト人は[[紀元前3000年]]ごろには早くも中央集権国家を形成し、[[ピラミッド]]や[[王家の谷]]、[[ヒエログリフ]]などを通じて世界的によく知られている高度な[[文明]]を発達させた。\n\n=== アケメネス朝ペルシア ===\n3000年にわたる諸王朝の盛衰の末、[[紀元前525年]]に[[アケメネス朝]]ペルシアに支配された。\n\n=== ヘレニズム文化 ===\n[[紀元前332年]]には[[アレクサンドロス3世|アレクサンドロス大王]]に征服された。その後、[[ギリシャ人|ギリシア系]]の[[プトレマイオス朝]]が成立し、[[ヘレニズム]]文化の中心のひとつとして栄えた。\n\n=== ローマ帝国 ===\nプトレマイオス朝は[[紀元前30年]]に滅ぼされ、エジプトは[[ローマ帝国]]の[[属州]]となり[[アエギュプトゥス]]と呼ばれた。ローマ帝国の統治下では[[キリスト教]]が広まり、[[コプト教会]]が生まれた。ローマ帝国の分割後は[[東ローマ帝国]]に属し、豊かな[[穀物]]生産でその繁栄を支えた。\n\n=== イスラム王朝 ===\n7世紀に[[イスラム教|イスラム化]]。[[639年]]に[[イスラム帝国]]の[[将軍]][[アムル・イブン・アル=アース]]によって征服され、[[ウマイヤ朝]]および[[アッバース朝]]の一部となった。アッバース朝の支配が衰えると、そのエジプト[[総督]]から自立した[[トゥールーン朝]]、[[イフシード朝]]の短い支配を経て、[[969年]]に現在の[[チュニジア]]で興った[[ファーティマ朝]]によって征服された。これ以来、[[アイユーブ朝]]、[[マムルーク朝]]とエジプトを本拠地として[[歴史的シリア|シリア地方]]まで版図に組み入れた[[イスラム王朝]]が500年以上にわたって続く。特に250年間続いたマムルーク朝の下で[[中央アジア]]や[[カフカス]]などアラブ世界の外からやってきた[[マムルーク]](奴隷軍人)による支配体制が確立した。\n\n=== オスマン帝国 ===\n[[1517年]]に、マムルーク朝を滅ぼしてエジプトを属州とした[[オスマン帝国]]のもとでもマムルーク支配は温存された({{仮リンク|エジプト・エヤレト|en|Egypt Eyalet}})。\n\n=== ムハンマド・アリー朝 ===\n[[ファイル:ModernEgypt, Muhammad Ali by Auguste Couder, BAP 17996.jpg|thumb|180px|[[ムハンマド・アリー]]]]\n[[1798年]]、[[フランス]]の[[ナポレオン・ボナパルト]]による[[エジプト・シリア戦役|エジプト遠征]]をきっかけに、エジプトは[[近代国家]]形成の時代を迎える。フランス軍撤退後、混乱を収拾して権力を掌握したのはオスマン帝国が派遣した[[アルバニア人]]部隊の隊長としてエジプトにやってきた軍人、[[ムハンマド・アリー]]であった。彼は実力によってエジプト総督に就任すると、マムルークを打倒して総督による中央集権化を打ち立て、[[経済]]・[[軍事]]の近代化を進め、エジプトをオスマン帝国から半ば独立させることに成功した。アルバニア系ムハンマド・アリー家による[[世襲]]政権を打ち立てた([[ムハンマド・アリー朝]])。しかし、当時の世界に勢力を広げた[[ヨーロッパ]][[列強]]はエジプトの独立を認めず、また、ムハンマド・アリー朝の急速な近代化政策による社会矛盾は結局、エジプトを列強に経済的に従属させることになった。\n\n=== イギリスの進出 ===\nムハンマド・アリーは[[綿花]]を主体とする農産物[[専売制]]をとっていたが、1838年に宗主オスマン帝国が[[イギリス]]と自由貿易協定を結んだ。ムハンマド・アリーが1845年に三角州の堰堤を着工。死後に専売制が崩壊し、また堰堤の工期も延びて3回も支配者の交代を経た1861年、ようやく一応の完工をみた。1858年末には国庫債券を発行しなければならないほどエジプト財政は窮迫していた。[[スエズ運河会社]]に払い込む出資金の不足分は、シャルル・ラフィット([[:fr:Charles Laffitte|Charles Laffitte]])と割引銀行(現・[[BNPパリバ]])から借り、国庫債券で返済することにした。[[イスマーイール・パシャ]]が出資の継続を認めたとき、フランスの[[ナポレオン3世]]の裁定により契約責任を問われ、違約金が[[自転車操業]]に拍車をかけた。[[1869年]]、エジプトはフランスとともに[[スエズ運河]]を開通させた。この前後(1862 - 1873年)に8回も[[外債]]が起債され、額面も次第に巨額となっていた。エジプトはやむなくスエズ運河会社持分を398万[[スターリング・ポンド|ポンド]]でイギリスに売却したが、1876年4月に[[デフォルト]]した<ref>西谷進、「[https://doi.org/10.20624/sehs.37.2_113 一九世紀後半エジプト国家財政の行詰まりと外債 (一)]」 『社会経済史学』 1971年 37巻 2号 p.113-134,216\n, {{doi|10.20624/sehs.37.2_113}}</ref>。\n\n英仏が負債の償還をめぐって争い、エジプトの蔵相は追放された。[[イタリア]]や[[オーストリア]]も交えた負債委員会が組織された。2回目のリスケジュールでイスマーイール一族の直轄地がすべて移管されたが、土地税収が滞った<ref>西谷進、「[https://doi.org/10.20624/sehs.37.3_283 一九世紀後半エジプト国家財政の行詰まりと外債 (二)]」 社会経済史学 1971年 37巻 3号 p.283-311,330-33, {{doi|10.20624/sehs.37.3_283}}</ref>。\n\n[[1882年]]、[[アフマド・オラービー]]が中心となって起きた反英運動([[ウラービー革命]])がイギリスによって武力鎮圧された。エジプトはイギリスの[[保護国]]となる。結果として、政府の教育支出が大幅カットされるなどした。[[1914年]]には、[[第一次世界大戦]]によってイギリスがエジプトの名目上の[[宗主国]]であるオスマン帝国と開戦したため、エジプトはオスマン帝国の宗主権から切り離された。さらに[[サアド・ザグルール]]の逮捕・国外追放によって反英独立運動たる[[エジプト革命 (1919年)|1919年エジプト革命]]が勃発し、英国より主政の国として独立した。\n\n=== 独立・エジプト王国 ===\n第一次大戦後の[[1922年]][[2月28日]]に'''[[エジプト王国]]'''が成立し、翌年イギリスはその[[独立]]を認めたが、その後もイギリスの間接的な支配体制は続いた。\n\nエジプト王国は[[立憲君主制]]を布いて議会を設置し、緩やかな近代化を目指した。[[第二次世界大戦]]では、[[枢軸国軍]]がイタリア領リビアから侵攻したが、英軍が撃退した([[北アフリカ戦線]])。第二次世界大戦前後から[[パレスチナ問題]]の深刻化や、1948年から1949年の[[パレスチナ戦争]]([[第一次中東戦争]])での[[イスラエル]]への敗北、経済状況の悪化、[[ムスリム同胞団]]など政治のイスラム化([[イスラム主義]])を唱える社会勢力の台頭によって次第に動揺していった。\n\n=== エジプト共和国 ===\nこの状況を受けて[[1952年]]、軍内部の秘密組織[[自由将校団]]が[[クーデター]]を起こし、国王[[ファールーク1世 (エジプト王)|ファールーク1世]]を亡命に追い込み、ムハンマド・アリー朝を打倒した([[エジプト革命 (1952年)|エジプト革命]]<ref>片山正人『現代アフリカ・クーデター全史』叢文社 2005年 ISBN 4-7947-0523-9 p49</ref>)。生後わずか半年の[[フアード2世 (エジプト王)|フアード2世]]を即位させ、[[自由将校団]]団長の[[ムハンマド・ナギーブ]]が首相に就任して権力を掌握した。さらに翌年の1953年、国王を廃位して共和政へと移行、[[ムハンマド・ナギーブ|ナギーブ]]が首相を兼務したまま初代大統領となり、'''エジプト共和国'''が成立した。\n\n=== ナーセル政権 ===\n[[ファイル:Gamal Nasser.jpg|thumb|180px|right|[[ガマール・アブドゥル=ナーセル]]。[[第二次中東戦争]]に勝利し、スエズ運河を国有化した。ナーセルの下でエジプトは[[汎アラブ主義]]の中心となった]]\n[[1956年]]、第2代大統領に就任した[[ガマール・アブドゥル=ナーセル]]のもとでエジプトは[[冷戦]]下での中立外交と[[汎アラブ主義|汎アラブ主義(アラブ民族主義)]]を柱とする独自の政策を進め、[[第三世界]]・[[アラブ諸国]]の雄として台頭する。同年にエジプトは[[スエズ運河国有化宣言|スエズ運河国有化]]を断行し、これによって勃発した[[第二次中東戦争]](スエズ戦争)で政治的に勝利を収めた。[[1958年]]には[[シリア]]と連合して'''[[アラブ連合共和国]]'''を成立させた。しかし[[1961年]]にはシリアが連合から脱退し、[[国家連合]]としてのアラブ連合共和国はわずか3年で事実上崩壊した。さらに[[1967年]]の[[第三次中東戦争]]は惨敗に終わり、これによってナーセルの権威は求心力を失った。\n\n=== サーダート政権 ===\n[[1970年]]に急死したナーセルの後任となった[[アンワル・アッ=サーダート]]は、自ら主導した[[第四次中東戦争]]後に[[ソビエト連邦]]と対立して[[アメリカ合衆国]]など[[西側諸国]]に接近。[[社会主義]]的経済政策の転換、[[イスラエル]]との融和など、ナーセル体制の切り替えを進めた。[[1971年]]には、国家連合崩壊後もエジプトの国号として使用されてきた「アラブ連合共和国」の国号を捨てて'''エジプト・アラブ共和国'''に改称した。また、サーダートは、経済の開放などに舵を切るうえで、左派に対抗させるべくイスラーム主義勢力を一部容認した。しかしサーダートは、イスラエルとの和平を実現させたことの反発を買い、[[1981年]]に[[イスラム過激派]]の[[ジハード団]]によって[[暗殺]]された。\n\n=== ムバーラク政権 ===\n[[ファイル:Hosni Mubarak ritratto.jpg|thumb|180px|[[アラブの春]]で失脚するまで30年以上にわたり長期政権を維持した[[ホスニー・ムバーラク]]]]\n[[イラク]]の[[クウェート侵攻]]はエジプトの国際収支を悪化させた。サーダートに代わって副大統領から大統領に昇格した[[ホスニー・ムバーラク]]は、対米協調外交を進める一方、[[開発独裁]]的な[[政権]]を20年以上にわたって維持した。\n\nムバラク政権は1990年12月に「1000日計画」と称する経済改革案を発表した。クウェート解放を目指す[[湾岸戦争]]では[[多国籍軍]]へ2万人を派兵し、これにより約130億ドルも[[対外債務]]を減らすという外交成果を得た。累積債務は500億ドル規模であった。軍事貢献により帳消しとなった債務は、クウェート、[[サウジアラビア]]に対するものと、さらに対米軍事債務67億ドルであった。1991年5月には[[国際通貨基金]]のスタンドバイクレジットおよび[[世界銀行]]の構造調整借款(SAL)が供与され、[[パリクラブ]]において200億ドルの債務削減が合意された。エジプト経済の構造調整で画期的だったのは、ドル・ペッグによる為替レート一本化であった<ref>『エジプトの経済発展の現状と課題』 [[海外経済協力基金]]開発援助研究所 1998年 23頁</ref>。\n\n海外の[[機関投資家]]に有利な条件が整えられていった。イスラム主義運動は厳しく[[弾圧]]され、[[ザカート|喜捨]]の精神は失われていった。[[1997年]]には[[イスラム集団]]による[[ルクソール事件]]が発生している。1999年にイスラム集団は武装闘争放棄を宣言し、近年、観光客を狙った事件は起こっていない。しかし、ムバーラクが大統領就任と同時に発令した[[非常事態法]]は、彼が追放されるまで30年以上にわたって継続された<ref>[http://www.cnn.co.jp/world/30001719.html エジプト副大統領が野党代表者らと会談、譲歩示す]</ref>。\n\n2002年6月、エジプト政府は15億ドルの[[ユーロ債]]を起債したが、2002年から2003年に為替差損を被り、対外債務を増加させた<ref>IMF, ''Arab Republic of Egypt: Selected Issues'', 2005, [https://books.google.co.jp/books?id=aZDSd_fjJzkC&pg=PT49&dq=reschedule+egypt+eurobond&hl=ja&sa=X&ved=0ahUKEwiD0qHpn8DbAhWLWbwKHXRrDGQQ6AEIJzAA#v=onepage&q=reschedule%20egypt%20eurobond&f=false]</ref>。\n\n=== ムルシー政権 ===\n[[ファイル:Mohamed Morsi-05-2013.jpg|thumb|180px|民主化後初の大統領だった[[ムハンマド・ムルシー]]]]\n{{Main|エジプト革命 (2011年)|2012年エジプト大統領選挙}}\n[[チュニジア]]の[[ジャスミン革命]]に端を発した近隣諸国の民主化運動がエジプトにおいても波及し、[[2011年]]1月、30年以上にわたって独裁体制を敷いてきたムバーラク大統領の辞任を求める大規模なデモが発生した。同2月には大統領支持派によるデモも発生して騒乱となり、国内主要都市において大混乱を招いた。大統領辞任を求める声は日に日に高まり、2月11日、ムバーラクは大統領を辞任し、全権が[[エジプト軍最高評議会]]に委譲された。同年12月7日には{{仮リンク|カマール・ガンズーリ|en|Kamal Ganzouri}}を暫定首相とする政権が発足した。その後、2011年12月から翌年1月にかけて人民議会選挙が、また2012年5月から6月にかけて大統領選挙が実施され[[ムハンマド・ムルシー]]が当選し、同年6月30日の大統領に就任したが、人民議会は大統領選挙決選投票直前に、選挙法が違憲との理由で裁判所から解散命令を出されており、立法権は軍最高評議会が有することとなった。\n\n2012年11月以降、新憲法の制定などをめぐって反政府デモや暴動が頻発した({{仮リンク|2012年-13年エジプト抗議運動|en|2012–13 Egyptian protests}})。ムルシー政権は、政権への不満が大規模な暴動に発展するにつれて、当初の警察改革を進める代わりに既存の組織を温存する方向に転換した。{{仮リンク|ムハンマド・イブラヒーム・ムスタファ|ar|محمد إبراهيم مصطفى|label=ムハンマド・イブラヒーム}}が内相に就任した[[2013年]]1月以降、治安部隊による政治家やデモ隊への攻撃が激化。1月末には当局との衝突でデモ参加者など40人以上が死亡したが、治安部隊への調査や処罰は行われていない<ref>「『アラブの春』の国で繰り返される悪夢」 エリン・カニンガム 『Newsweek[[ニューズウィーク]]日本版』 2013年3月5日号</ref>。イブラヒーム内相は、「国民が望むならば辞任する用意がある」と2月に述べている<ref>{{Cite news\n|url=http://english.ahram.org.eg/News/63894.aspx\n|title=I will leave my position if people want: Egypt's interior minister\n|newspaper=アハラムオンライン\n|date=2013-02-02\n|accessdate=2013-05-08\n}}</ref>。下落する[[エジプト・ポンド]]がとめどなく[[アメリカ合衆国ドル|USドル]]に交換され、[[外貨準備]]を減らすような混乱が同月10日の[[ロイター通信]]で報じられている。下落は1月から起きており、同月には[[ドバイ]]のエミレーツNBD([[:en:Emirates NBD|Emirates NBD]])が[[BNPパリバ]]のエジプト支店を完全買収した。[[オイルマネー]]がエジプト経済を我が物にする社会現象が起こっていた。さらに『[[フィナンシャル・タイムズ]]』が1月19日に報じたのは、[[エチオピア]]がナイルの川上に48億ドルの予算をかけて[[ダム]]を造るという計画であった。混乱中のエジプトが水紛争で負ければ大きな水ストレスが生じるだろうと予測された。\n\n2013年4月、[[エジプト中央銀行]]は[[リビア]]から20億ドルの預金を得た。リビア側が利害を説明したところによると、リビアはエジプト株を100億ドル近く保有しているという。リビアは[[世界金融危機]]の時から欧米の[[メガバンク]]と癒着を疑われている。\n\nムルシー政権は発足後約1年後の[[2013年エジプトクーデター|2013年7月3日、軍部によるクーデター]]によって終焉を迎えた<ref>{{Cite news\n|url=http://middleeast.asahi.com/watch/2013070800008.html\n|title=エジプトのクーデターに至る過程:朝日新聞記事再録\n|work=asahi.com\n|newspaper=[[朝日新聞]]\n|date=2013-07-09\n|accessdate=2013-07-13\n}}</ref>。8月下旬にムバラクが釈放され、国内銀行が平常運転に復帰した。8月30日の[[CNN]]では、[[中国石油化工]]が米国[[ヒューストン]]のアパッチ([[:en:Apache Corporation|Apache Corporation]])とエジプト内[[油田]]事業を提携したことが報じられた。10月下旬、[[アラブ首長国連邦]]がエジプトに50億ドルの支援を申し出た。エジプトエリートの売国とソブリン危機は翌年4月まで深化していった。\n\nなお、イブラヒームは、クーデター後に成立した[[ハーゼム・エル=ベブラーウィー|ベブラーウィー]]暫定内閣でも続投している。\n\n=== アッ=シーシー政権 ===\n[[ファイル:Abdel_Fattah_el-Sisi_September_2017.jpg|thumb|180px|[[アブドルファッターフ・アッ=シーシー]]。2013年のクーデターを主導し、大統領に就任した]]\n2014年5月26日 - 28日に行われた大統領選挙では2013年のクーデターの主導者[[アブドルファッターフ・アッ=シーシー]]が当選して6月8日、大統領に就任し<ref>http://www.afpbb.com/articles/-/3017089 エジプトのシシ新大統領が就任、前大統領の追放からほぼ1年</ref>、8月5日からは[[新スエズ運河]]の建設など大規模なプロジェクトを推し進めた。[[2015年]][[3月13日]]には、[[カイロ]]の東側に向こう5 - 7年で、450億ドルを投じて新しい行政首都の建設も計画していることを明らかにした<ref>http://jp.reuters.com/article/topNews/idJPKBN0MC0B720150316 エジプト、カイロの東に新行政首都建設へ=住宅相(ロイター通信)</ref>。行政と経済の中心となる新首都はカイロと紅海の間に建設され、広さは約700平方キロメートルで、米[[ニューヨーク]]の[[マンハッタン]]のおよそ12倍の面積の予定であり<ref>http://jp.wsj.com/articles/SB10030317691824024149004580519060782977390 エジプト、新首都建設を計画―カイロと紅海の間に</ref>、大統領府などエジプトの行政を担う地区は当初覚書を交わした[[アラブ首長国連邦]](UAE)の[[エマール・プロパティーズ]]や[[中華人民共和国|中国]]の[[中国建築|中国建築股份有限公司]]との破談はあったものの[[2016年]]4月に地元企業によって工事を開始し<ref>{{Cite news|url=http://www.xinhuanet.com/english/2016-04/02/c_135246252.htm|tile=Egypt kicks off 1st phase of building new capital|work= [[新華社]]|date=2016-04-02|accessdate=2018-06-25}}</ref>、代わりにエジプト政府がピラミッド<ref>{{Cite news|url= https://zhuanlan.zhihu.com/p/41444500|title=埃及总理表示,将新首都CBD项目建成“金字塔”一样的地标|work= 知乎专栏|date=2018-08-06|accessdate=2018-08-18}}</ref>に匹敵する一大事業の[[ランドマーク]]と位置づけている、アフリカでもっとも高いビルも建設予定である経済を担う[[中央業務地区]]を中国企業が請け負って[[2018年]]3月に着工した<ref>{{Cite news|url=http://www.xinhuanet.com/english/2017-10/12/c_136672905.htm|tile=Chinese firm finalizes deal for building huge business district in Egypt's new capital|work= amwalalghad|date=2017-10-12|accessdate=2018-07-28}}</ref><ref>{{Cite news|url=http://en.amwalalghad.com/china-to-build-egypt-africa-tallest-tower-in-new-capital-spokesperson/|tile=China to build Egypt-Africa tallest tower in new capital: spokesperson|work= amwalalghad|date=2018-06-28|accessdate=2018-06-29}}</ref><ref>{{Cite news|url=https://www.bloomberg.com/news/articles/2018-03-18/china-to-finance-majority-of-new-egypt-capital-s-tower-district|tile=China to Finance Majority of New Egypt Capital's Tower District|work= [[ブルームバーグ (企業)|ブルームバーグ]]|date=2018-03-18|accessdate=2018-07-28}}</ref><ref>{{Cite news|url= http://eg.mofcom.gov.cn/article/todayheader/201803/20180302720170.shtml|title=中建埃及新行政首都CBD项目开工仪式在开罗举行|work= 中華人民共和国駐エジプト大使館|date=2018-03-21|accessdate=2018-06-25}}</ref>。\n\nUAEや中国と破談した背景には通貨不安が存在する。2016年11月3日、エジプト中央銀行が[[変動相場制]]を採用すると発表した。エジプト・ポンドが売られるのを革命の影響だけで片付けるには、この不安は長引きすぎている。同行は6日後、国際金融機関から20億ドルの[[シャドー・バンキング・システム#レポ市場|レポ借入]]を始めた。4月に[[国際通貨基金]]からも120億ドルを借りている。エジプトは経済主権を失っている。[[ガーディアン]]が10月4日に報じたところでは、国際金融機関の[[バークレイズ]]がエジプト事業を[[ダノン#ワファバンク|ワファバンク]]に売却した。\n\n2017年末、政府が[[世界銀行]]に対し、エチオピアのダム事業を差し止めるように要請した。世銀は5月にエジプトへ10億ドルを追加融資しており、エジプトは厳しい立場にある。翌2018年1月中旬にエチオピアとの水紛争が妥協に至った。5月末にエジプトの対外債務累積額は829億ドルであった。9月、ムバラクの息子ら2人([[:en:Gamal Mubarak|Gamal]] and [[:en:Alaa Mubarak|Alaa]])がエジプトの株価を操作した疑いで逮捕された。\n\n== 政治 ==\n{{エジプトの政治}}\n{{Main2|詳細は{{仮リンク|エジプトの政治|en|Politics of Egypt|ar|السياسة في مصر}}および[[近代エジプトの国家元首の一覧]]}}\n\n=== 政体 ===\n[[共和制]]\n=== 大統領 ===\n[[国家元首]]の大統領は、立法・行政・司法の三権において大きな権限を有する。また国軍([[エジプト軍]])の[[総司令官|最高司令官]]でもある。大統領の選出は、[[直接選挙]]による。任期は4年で、三選禁止となった<ref>{{Cite journal|和書|author = 鈴木恵美|coauthors = |title = エジプト革命以後の新体制形成過程における軍の役割|journal = 地域研究|volume = 12|issue = 1|pages = 135-147|publisher = 京都大学地域研究統合情報センター|location = |date = 2012-03-28|language = |url = http://www.cias.kyoto-u.ac.jp/publish/?cat=4|jstor = |issn = 1349-5038 |isbn =978-4-8122-1178-6|doi = |id = |naid = |accessdate = 2012-06-17}}</ref>。最高大統領選挙委員会(The Supreme Presidential Election Commission, SPEC)委員長は、最高憲法裁判所長官が兼任していたが、現在は副長官がその任を負う。\n\n第2代大統領[[ガマール・アブドゥル=ナーセル]]以来、事実上の終身制が慣例で、第4代大統領[[ホスニー・ムバーラク]]は[[1981年]]の就任以来、約30年にわたって[[独裁]]体制を築いた。ムバーラクの[[親米]]・親[[イスラエル]]路線が欧米諸国によって評価されたために、独裁が見逃されてきた面がある。当時は任期6年、多選可。議会が候補者を指名し、国民は[[信任投票]]を行っていた。ただし、2005年は複数候補者による大統領選挙が実施された。\n\n[[2011年]]9月に大統領選が予定されていたが、2011年1月に騒乱状態となり、[[2月11日]]、ムバーラクは国民の突き上げを受ける形で辞任した。翌日より[[国防大臣]]で[[エジプト軍最高評議会|軍最高評議会]]議長の[[ムハンマド・フセイン・タンターウィー]]が元首代行を務め、それは[[2012年エジプト大統領選挙]]の当選者[[ムハンマド・ムルシー]]が[[6月30日]]に大統領に就任するまで続いた。2011年[[3月19日]]、[[憲法改正]]に関する[[国民投票]]が行われ、承認された<ref name=jpnmofa>{{Cite web|title = エジプト・アラブ共和国 基礎データ|work = 各国:地域情勢|publisher = 外務省(日本)|url = http://www.mofa.go.jp/mofaj/area/egypt/data.html|accessdate =2016-10-01}}</ref><ref>{{Cite web|title = エジプト基礎情報~政治・外交|work = エジプト情報|publisher = 在エジプト日本国大使館|date = 2011-07-30|url = http://www.eg.emb-japan.go.jp/j/egypt_info/basic/seiji.htm|accessdate =2016-10-01}}</ref>。\n\nしかしムルシー政権発足からわずか1年後の2013年、[[2013年エジプトクーデター|軍事クーデター]]が勃発。ムルシーは解任され、エジプトは再び軍による統治へと逆戻りした。2014年1月に再び憲法が修正され<ref name=jpnmofa />、同年5月の大統領選挙を経て再び民政へと復帰した。\n\n=== 議会 ===\n議会は、[[一院制]]の'''人民議会'''(マジュリス・アッ=シャアブ)。全508議席で、498議席は公選、10議席は大統領指名枠<ref>2011年12月現在では、定数498議席のうち、3分の2(332議席)が政党(連合)リストによる[[比例代表制]]で、3分の1(166議席)が[[小選挙区制]]で選出される</ref>。任期5年。これとは別に、'''諮問評議会'''(シューラ)が1980年設置されたが、立法権は有さない大統領の諮問機関である<ref>{{Cite web| author = 鈴木恵美\n | coauthors =\n | title = エジプト\n | work = 中東・イスラーム諸国の民主化\n | publisher = NIHU プログラム・イスラーム地域研究、東京大学拠点\n | date =\n | url = http://www.l.u-tokyo.ac.jp/~dbmedm06/me_d13n/database/egypt/egypt_all.html\n | format =\n | doi =\n | accessdate = 2012-06-15}}</ref>。全270議席で、180議席が公選、90議席が大統領指名枠。\n\n=== 選挙 ===\n2011年[[11月21日]]、[[イサーム・シャラフ]]暫定内閣は、デモと中央[[治安部隊]]の衝突で多数の死者が出たことの責任を取り軍最高評議会へ辞表を提出した。軍最高評議会議長タンターウィーは[[11月22日]]テレビで演説し、「28日からの人民議会選挙を予定通り実施し、次期大統領選挙を2012年6月末までに実施する」と表明した<ref>[http://www.asahi.com/special/meastdemo/TKY201111220122.html エジプト・シャラフ内閣が総辞職表明 デモの混乱で引責] 『朝日新聞』 2011年11月22日</ref><ref>[http://www.asahi.com/special/meastdemo/TKY201111230004.html エジプト軍議長「近く挙国一致内閣」とテレビ演説] 『朝日新聞』 2011年11月23日</ref><ref>[http://www.asahi.com/special/meastdemo/TKY201111250136.html エジプト軍議長、元首相に組閣要請 選挙管理内閣を想定] 『朝日新聞』 2011年11月25日</ref>。人民議会選挙は2011年[[11月28日]]から[[2012年]][[1月]]までに、行政区ごとに3回に分けて、また、投票日を1日で終わりにせず2日間をとり、大勢の投票での混乱を緩和し実施、諮問評議会選挙も[[3月11日]]までに実施された。また[[5月23日]]と[[5月24日|24日]]に[[2012年エジプト大統領選挙|大統領選挙]]の投票が実施された。\n\nしかし、[[6月14日]]に最高[[憲法裁判所]]が出した「現行の議会選挙法は違憲で無効(3分の1の議員について当選を無効と認定)」との判決を受け<ref>[http://www.asahi.com/international/reuters/RTR201206150031.html「エジプト議会選は無効」、憲法裁が大統領選直前に違法判断] 『朝日新聞』 2012年6月15日</ref><ref>[http://www.news24.jp/articles/2012/06/15/10207632.html エジプト議会、解散へ 大統領選にも影響か] [[日テレNEWS24]] 2012年6月15日</ref>、[[6月16日|16日]]までにタンターウィー議長は人民議会解散を命じた<ref>{{Cite news\n | author = カイロ共同\n | title = エジプト、軍が議会に解散命令 憲法裁判所の判断で\n | newspaper = 47NEWS\n | location =\n | pages = 6\n | language =\n | publisher = 共同通信\n | date = 2012-06-18\n | url = http://www.47news.jp/CN/201206/CN2012061701001315.html\n | accessdate = 2012-06-18}}</ref>。大統領選挙の決選投票は6月16日と[[6月17日|17日]]に実施され、イスラム主義系の[[ムハンマド・ムルシー]]が当選した。\n\n=== 政党 ===\n{{main|エジプトの政党}}\n\n2011年3月28日に改正政党法が公表され、エジプトでは[[宗教]]を基盤とした[[政党]]が禁止された。そのため、[[ムスリム同胞団]](事実上の最大[[野党]]であった)などは非合法化され、初めての選挙(人民議会選挙)では、ムスリム同胞団を母体とする[[自由公正党]]({{lang-ar|حزب الحرية والعدالة}} - {{lang|en|Ḥizb Al-Ḥurriya Wal-’Adala}}, {{lang-en-short|Freedom and Justice Party}})が結成された。また、[[ヌール党]]([[サラフィー主義]]、イスラーム保守派)、[[新ワフド党]](エジプト最古の政党)、[[政党連合]]{{仮リンク|エジプト・ブロック|en|Egyptian Bloc}}(含む[[自由エジプト人党]](世俗派)、[[エジプト社会民主党]](中道左派)、[[国民進歩統一党]](左派))、[[ワサト党]]、{{仮リンク|政党連合革命継続|en|The Revolution Continues Alliance}}、{{仮リンク|アダラ党|en|Justice Party (Egypt)|label=公正党}}({{lang-ar|حزب العدل}} - {{lang|en|Hizb ElAdl}}, {{lang-en-short|Justice Party}}、今回の革命の中心を担った青年活動家による政党)など、全部で50以上の政党が参加していた<ref>{{Cite web\n | last =\n | first =\n | authorlink =\n | coauthors =\n | title = エジプト・アラブ共和国 基礎データ\n | work = 各国:地域情勢\n | publisher = 外務省(日本)\n | date =\n | url = http://www.mofa.go.jp/mofaj/area/egypt/data.html\n | format =\n | doi =\n | accessdate =2012-06-17 }}</ref><ref>{{Cite web\n | last =\n | first =\n | authorlink =\n | coauthors =\n | title = エジプト基礎情報~政治・外交\n | work = エジプト情報\n | publisher = 在エジプト日本国大使館\n | date = 2011-07-30\n | url = http://www.eg.emb-japan.go.jp/j/egypt_info/basic/seiji.htm\n | format =\n | doi =\n | accessdate =2012-06-17 }}</ref>。\n\n=== 政府 ===\n* {{仮リンク|エジプトの首相|en|Prime Minister of Egypt|label=首相}}・{{仮リンク|ムスタファ・マドブーリー|en|Moustafa Madbouly}} 2018年6月就任。\n* {{仮リンク|エジプトの国防大臣の一覧|en|List of Ministers of Defence of Egypt|label=国防大臣}}・{{仮リンク|セドキ・ソブヒィ|en|Sedki Sobhi}} 2014年3月就任、エジプト軍総司令官。\n\n== 司法 ==\n{{Main2|詳細は[[エジプトの法]]}}\n[[ナポレオン法典]]と[[イスラム法]]に基づく、混合した法システム<ref>{{Cite web|title = Egypt| publisher = CIA-The World Factbook| url = https://www.cia.gov/library/publications/the-world-factbook/geos/eg.html| accessdate = 2012-06-15}}</ref>。フランスと同じく、司法訴訟と行政訴訟は別の系統の裁判所が担当する。{{仮リンク|フランスにおける裁判所の二元性|fr|Dualité des ordres de juridiction en France}}参照。\n* {{仮リンク|最高憲法裁判所|en|Supreme Constitutional Court of Egypt}} - 法律が違憲か否かを判断する。1979年設立。長官はアドリー・マンスール(2013年7月1日 - )<ref>{{Cite web| title = Aperçu Historique | publisher = 最高憲法裁判所\n | url =http://www.hccourt.gov.eg/About/history.asp\n | accessdate = 2013-08-27}}</ref>。ほか、10人の判事は1998年から2013年7月までに着任している<ref>{{Cite web| title = Current Members of the Court | publisher = 最高憲法裁判所\n | date =\n | url =http://www.hccourt.gov.eg/CourtMembers/CurrentCourt.asp\n | accessdate = 2013-08-27}}</ref>。長官は[[最高大統領選挙委員会]](The Supreme Presidential Election Commission, SPEC)の委員長を兼任していた<ref>{{Cite news\n | author = 貫洞欣寛\n| title = エジプト司法が逆襲 ムバラク裁判「判決批判許さん」\n | newspaper = 朝日新聞 | date = 2012-06-09\n | url = http://digital.asahi.com/articles/TKY201206080567.html?ref=comkiji_txt_end\n | accessdate = 2012-06-15}}</ref>が、2012年9月には副長官ハーティム・バガートゥーが務めていた<ref>{{Cite web\n | title = 中東要人講演会\n | newspaper = 中東調査会 | date =\n | url = http://www.meij.or.jp/members/20120903124551000000.pdf\n | accessdate = 2012-09-09}}</ref>。\n* [[司法省]]管轄の一般の[[裁判所]] - [[最高裁判所]]([[破毀院]]、1931年設立)と以下の[[下級裁判所]]([[控訴院]]、[[第一審]]裁判所、[[地区裁判所]]および[[家庭裁判所]] - 2004年設立)からなる。\n* [[国務院]]管轄の[[行政裁判所]] - [[コンセイユ・デタ]] - 1946年設立<ref>{{Cite web| title = Judiciary Authority| publisher = Egypt State Information Service\n| url =http://www.sis.gov.eg/En/Templates/Categories/tmpListArticles.aspx?CatID=248\n | accessdate = 2013-08-29}}</ref>。2011年[[2月19日]]、従来の[[政党委員会]](政府運営)の申請却下に対する不服申し立てを認めた形の判決で、[[政党]]の許認可<ref>{{Cite web| title = エジプトでイスラーム政党が認可 | work =[中東研ニュースリポート]| publisher = [[日本エネルギー経済研究所]] 中東研究センター| date = 2月21日\n | url =http://jime.ieej.or.jp/htm/extra/ronbun/003pol.htm\n | format =\n | doi =\n | accessdate = 2012-05-19}}</ref>を、[[4月16日]]、[[与党]]・[[国民民主党 (エジプト)|国民民主党]](NDP)の解散を裁定した。\n\n== 国際関係 ==\n{{main|{{仮リンク|エジプトの国際関係|en|Foreign relations of Egypt}}}}\n国力、文化的影響力などの面からアラブ世界のリーダーとなっている。ガマール・アブドゥル=ナーセル時代には[[非同盟諸国]]の雄としてアラブに限らない影響力を持ったが、ナーセル死後はその影響力は衰えた。ナーセル時代は親ソ連だった外交はサーダート時代に入って親米路線となり、さらにそれに伴いイスラエルとの外交関係が進展。1978年の[[キャンプ・デービッド合意]]とその翌年のイスラエル国交回復によって親米路線は確立したが、これはイスラエルを仇敵とするアラブ諸国の憤激を買い、ほとんどのアラブ諸国から断交されることとなった。その後、[[1981年]]にサーダートが暗殺されたあとに政権を握ったムバーラクは親米路線を堅持する一方、アラブ諸国との関係回復を進め、1988年には[[シリア]]、[[レバノン]]、[[リビア]]を除くすべてのアラブ諸国との関係が回復した<ref>『アフリカを知る事典』、平凡社、ISBN 4-582-12623-5 1989年2月6日 初版第1刷 p.58</ref>。以降はアラブの大国として域内諸国と協調する一方、アフリカの一国として2004年9月には[[国際連合安全保障理事会]]の[[常任理事国]]入りを目指すことを表明した。[[2011年]]、[[パレスチナ]]の[[ガザ]]の[[国境検問所|検問所]]を開放した。また、[[イラン]]との関係を修復しようとしている<ref>[http://www.asyura2.com/11/lunchbreak47/msg/284.html エジプト:ガザ、出入り自由に 検問所開放、外交転換鮮明に]</ref>。\n\nシーシー政権はムスリム同胞団政権時代のこうした外交政策とは一線を画している。欧米や日本、親米アラブ諸国、イスラエルのほか、中国や[[ロシア]]<ref>[https://www.nikkei.com/article/DGXMZO24487270R11C17A2FF2000/ 「ロシアが中東に接近 プーチン大統領、エジプトに軍事協力 米の中東政策の揺らぎつく」][[日本経済新聞]]ニュースサイト(2017年12月11日)2019年1月9日閲覧。</ref>などと広範な協力関係を築いている。\n\n[[2017年カタール外交危機]]では、サウジアラビアとともに、ムスリム同胞団を支援してきたカタールと[[国交]]を断絶した国のひとつとなった。またサウジアラビアとは、[[アカバ湾]]口に架橋して陸上往来を可能とするプロジェクトが話し合われた([[チラン島]]を参照)。\n\n=== 日本国との関係 ===\n{{Main|日本とエジプトの関係}}\n\n== 軍事 ==\n[[ファイル:Abrams in Tahrir.jpg|thumb|陸軍の主力戦車[[M1エイブラムス]]]]\n{{Main|エジプト軍}}\n中東有数の軍事大国であり、イスラエルと軍事的に対抗できる数少ないアラブ国家であると目されている。2010年11月見積もりの総兵力は46万8,500人。[[予備役]]47万9,000人。兵員数は[[陸軍]]34万人([[軍警察]]を含む)、[[海軍]]1万8,500人([[沿岸警備隊]]を含む)、[[空軍]]3万人、[[防空軍]]8万人<ref>{{Cite book\n | title = The Middle East and North Africa 2012\n | publisher = Routledge\n | edition = 58th\n | date = 2011\n | page = 380\n | isbn = 978-1-85743-626-6}}</ref>。内務省管轄の中央[[治安部隊]]、[[国境警備隊]]と国防省管轄の革命[[国家警備隊]](大統領[[親衛隊]])の[[準軍事組織]]が存在する。\n\nイスラエルとは4度にわたる[[中東戦争]]で毎回干戈を交えたが、[[第二次中東戦争]]で政治的な勝利を得、[[第四次中東戦争]]の緒戦で勝利を収めたほかは劣勢のまま終わっている。その後はイスラエルと接近し、シーシー政権下ではシナイ半島で活動する[[イスラム過激派]]([[ISIS]])に対する掃討作戦で、[[イスラエル空軍]]による[[爆撃]]を容認していることを公式に認めた<ref>[http://www.tokyo-np.co.jp/article/world/list/201901/CK2019010602000123.html 「対IS イスラエルと協力」エジプト大統領 治安重視]『[[東京新聞]]』朝刊2019年1月6日(国際面)2019年1月9日閲覧。</ref>。\n\n軍事的にはアメリカと協力関係にあるため、[[北大西洋条約機構]](NATO)のメンバーではないものの同機構とは親密な関係を保っている。また、ロシアや中国からも武器の供給を受けており、中露の主導する[[上海協力機構]]への参加も申請している<ref>{{Cite web|date=2015-07-11|url=http://jp.sputniknews.com/politics/20150710/556387.html|title=上海協力機構事務総長:機構はカラー革命など恐れていない|publisher=Sputnik 日本|accessdate=2019-08-18}}</ref><ref>{{Cite web|date=2015-07-27|url=http://arab.rbth.com/news/2015/07/27/30859.html|title=وزير الخارجية المصري: مصر لا تستبعد عضويتها في منظمة \"شنغهاي\" للتعاون في المستقبل | روسيا ما وراء العناوين|publisher=ロシアNOWアラビア語版|accessdate=2019-08-18}}</ref><ref>{{Cite web|date=2016-06-23|url=http://www.interfax.com/newsinf.asp?id=683491|title=Syria, Israel, Egypt willing to join SCO's activity - president's special envoy|publisher=[[インテルファクス通信]]|accessdate=2019-08-18}}</ref>。\n\n== 地方行政区画 ==\n[[ファイル:Governorates of Egypt.svg|thumb|right|280px|エジプトの行政区画]]\n{{Main|エジプトの県}}\nエジプトの最上級の地方行政単位は、29あるムハーファザ({{lang|ar|محافظة}}, '''県'''、'''州''' と訳されることもある)である。[[知事]]は中央政府から派遣される官選知事で、内務省の管轄下において中央集権体制をとる。極端な行政区分でナイル川流域やナイル下流は非常に細分化されているにもかかわらず、南部は非常に大まかに分けられている。これは、ナイル流域以外が全域砂漠であり、居住者がほとんどいないことによるものである。\n\n=== 主要都市 ===\n{{Main|エジプトの都市の一覧}}\n{{Main|エジプトの県}}\n{{Col-begin}}\n{{Col-break}}\n* [[アシュート]]\n* [[アスワン]]\n* [[マラウィー]]\n* [[アブ・シンベル]]\n* [[アレクサンドリア]]\n* [[イスマイリア]]\n* [[インバーバ]]\n* [[エスナ]]\n* [[エドフ]]\n* [[エル・アラメイン]]\n* [[カイロ]]\n{{Col-break}}\n* [[ケナ]]\n* [[ギーザ]]\n* [[コム・オンボ]]\n* [[ザガジグ]]\n* [[サッカラ]]\n* [[シャルム・エル・シェイク]]\n* [[スエズ]]\n* [[スブラエルケーマ]]\n* [[ソハーグ県|ソハーグ]]\n* [[ダマンフール]]\n* [[タンター]]\n{{Col-break}}\n* [[ディムヤート]]\n* [[ハルガダ]]\n* [[ファイユーム]]\n* [[ベニスエフ]]\n* [[ポートサイド]]\n* [[エル=マハッラ・エル=コブラ|マハッラ・クブラー]]\n* [[マンスーラ]]\n* [[ミニヤー県|ミニヤ]]\n* [[メンフィス (エジプト)]]\n* [[ルクソール]]\n* [[ロゼッタ (エジプト)|ロゼッタ]]\n{{Col-end}}\n<!-- 五十音順 -->\n\n== 地理 ==\n{{Main2|詳細は{{仮リンク|エジプトの地理|en|Geography of Egypt}}}}\n[[ファイル:Egypt Topography.png|thumb|200px|エジプトの地形図]]\n[[ファイル:Egypt 2010 population density1.png|thumb|200px|エジプトの人口分布図]]\n[[アフリカ大陸]]北東隅に位置し、国土面積は100万2,450㎢で、世界で30番目の大きさである。国土の95%は砂漠で、ナイル川の西側には[[サハラ砂漠]]の一部である西部砂漠([[リビア砂漠]])、東側には[[紅海]]と[[スエズ湾]]に接する[[東部砂漠]]({{lang|ar|الصحراء الشرقية}} - シャルキーヤ砂漠)がある。西部砂漠には海抜0m以下という地域が多く、面積1万8,000km<sup>2</sup>の広さをもつ[[カッターラ低地]]は海面より133mも低く、[[ジブチ]]の[[アッサル湖]]に次いでアフリカ大陸で2番目に低い地点である。[[シナイ半島]]の北部は砂漠、南部は山地になっており、エジプト最高峰の[[カテリーナ山]](2,637m)や、[[旧約聖書]]で[[モーセ]]が[[モーセの十戒|十戒]]を授かったといわれる[[シナイ山]](2,285m)がある。シナイ半島とナイル河谷との間は[[スエズ湾]]が大きく湾入して細くくびれており、ここが[[アフリカ大陸]]と[[ユーラシア大陸]]の境目とされている。この細い部分は低地であるため、[[スエズ運河]]が建設され、紅海と地中海、ひいてはヨーロッパとアジアを結ぶ大動脈となっている。\n[[ファイル:S F-E-CAMERON 2006-10-EGYPT-LUXOR-0439.JPG|thumb|left|200px|[[ナイル川]]]]\n[[ナイル川]]は南隣の[[スーダン]]で[[白ナイル川]]と[[青ナイル川]]が合流し、エジプト国内を南北1,545Kmにもわたって北上し、河口で広大な[[三角州|デルタ]]を形成して[[地中海]]にそそぐ。[[アスワン]]以北は人口稠密な河谷が続くが、幅は5Kmほどとさほど広くない。上エジプト中部のキーナでの湾曲以降はやや幅が広がり<ref>『朝倉世界地理講座 アフリカI』初版所収「ナイル川の自然形態」春山成子、2007年4月10日(朝倉書店)p198</ref>、[[アシュート]]近辺で分岐の支流が[[ファイユーム]]近郊の[[モエリス湖|カールーン湖]]({{lang|ar|Birket Qarun}}、かつての[[モエリス湖]])へと流れ込む。この支流によって、カールーン湖近辺は肥沃な{{仮リンク|ファイユーム・オアシス|en|Faiyum Oasis}}を形成している。一方、本流は、[[カイロ]]近辺で典型的な扇状三角州となる'''[[ナイル・デルタ]]'''は、地中海に向かって約250Kmも広がっている。かつてはナイル川によって運ばれる土で、デルタ地域は国内でもっとも肥沃な土地だったが、[[アスワン・ハイ・ダム]]によってナイル川の水量が減少したため、地中海から逆に塩水が入りこむようになった。ナイル河谷は、古くから[[下エジプト]]と[[上エジプト]]という、カイロを境にした2つの地域に分けられている。前者はデルタ地域を指し、後者はカイロから上流の谷を指している。ナイル河谷は、世界でももっとも[[人口密度]]の高い地域のひとつである。\n\nナイル河谷以外にはほとんど人は住まず、わずかな人が[[オアシス]]に集住しているのみである。乾燥が激しく地形がなだらかなため、特にリビア砂漠側には[[ワジ]](涸れ川)が全くない。[[シワ・オアシス|シーワ]]、[[ファラフラ (エジプト)|ファラーフラ]]、[[ハルガ]]、バハレイヤ、ダフラといった[[オアシス]]が点在している<ref>『ミリオーネ全世界事典』第10巻 アフリカI([[学習研究社]]、1980年11月)p206</ref>。ナイル以東のシャルキーヤ砂漠は地形がやや急峻であり、ワジがいくつか存在する。紅海沿岸も降雨はほとんどないが、ナイルと[[アラビア半島]]を結ぶ重要な交通路に位置しているため、いくつかの小さな港が存在する。\n\n=== 国境 ===\n1885年に列強が[[ドイツ]]の[[ベルリン]]で開いた会議で、それまでに植民地化していたアフリカの分割を確定した。リビア国境の大部分で[[東経25度線|東経25度]]に、スーダンでは[[北緯22度線|北緯22度]]に定めたため、国境が直線的である。\n\nスーダンとの間では、エジプトが[[実効支配]]する[[ハラーイブ・トライアングル]]に対してスーダンも領有権を主張している。一方、その西にある[[ビル・タウィール]]は両国とも領有権を主張していない[[無主地]]である。\n\n=== 気候 ===\n{{Main2|詳細は{{仮リンク|エジプトの気候|en|Climate of Egypt}}}}\n国土の全域が[[砂漠気候]]で人口はナイル河谷および[[デルタ地帯]]、[[スエズ運河]]付近に集中し、国土の大半は[[サハラ砂漠]]に属する。夏には日中の気温は40℃を超え、50℃になることもある。降雨はわずかに[[地中海|地中海岸]]にあるにすぎない。冬の平均気温は下エジプトで13 - 14℃、上エジプトで16℃程度である。2013年12月にはカイロ市内でも降雪・積雪があったが、観測史上初ということで注目された。\n\n== 経済 ==\n{{Main2|詳細は{{仮リンク|エジプトの経済|en|Economy of Egypt}}}}\n[[ファイル:View from Cairo Tower 31march2007.jpg|thumb|left|220px|カイロはビジネス、文化、政治などを総合評価した[[世界都市#世界と指数|世界都市格付け]]でアフリカ第1位の都市と評価された<ref>[http://www.atkearney.com/documents/10192/4461492/Global+Cities+Present+and+Future-GCI+2014.pdf/3628fd7d-70be-41bf-99d6-4c8eaf984cd5 2014 Global Cities Index and Emerging Cities Outlook] (2014年4月公表)</ref>]]\n\n2018年のエジプトの[[GDP]]は約2,496億ドル(約27兆円)、一人当たりでは2,573ドルである<ref name=\"economy\" />。アフリカでは屈指の経済規模であり、[[BRICs]]の次に経済発展が期待できるとされている[[NEXT11]]の一国にも数えられている。しかし、一人当たりのGDPでみると、中東や北アフリカ諸国の中では、最低水準であり、[[トルコ]]の約4分の1、[[イラン]]の半分に過ぎず、更に同じ北アフリカ諸国である[[チュニジア]]や[[モロッコ]]に比べても、水準は低い<ref name=\"エジプト経済の現状と今後の展望\" >{{Cite report|author=堀江 正人|date=2019-01-08|title=エジプト経済の現状と今後の展望 ~経済の復調が注目される中東北アフリカの大国エジプト~|url=https://www.murc.jp/report/economy/analysis/research/report_190108/|publisher=[[三菱UFJリサーチ&コンサルティング|三菱UFJリサーチ&コンサルティング株式会社]]|accessdate=2020-02-03}}</ref>。\n\n[[スエズ運河]]収入と[[観光産業]]収入、更には在外労働者からの送金の3大外貨収入の依存が大きく、エジプト政府は、それらの手段に安易に頼っている<ref name=\"エジプト経済の現状と今後の展望\" />。更に政情に左右されやすい。\n\nかつては[[綿花]]の世界的生産地であり、ナイル川のもたらす肥沃な土壌とあいまって農業が重要な役割を果たしていた。しかし、通年灌漑の導入によってナイルの洪水に頼ることが減り、アスワン・ハイ・ダムの建設によって、上流からの土壌がせき止められるようになった。そのため、ダムによる水位コントロールによって農地が大幅に拡大した。農業生産高が格段に上がったにもかかわらず、[[肥料]]の集中投入などが必要になったため、コストが増大し、近年代表的な農業製品である綿製品は価格競争において後塵を拝している。\n\n[[1970年代]]に農業の機械化および各種生産業における機械への転換により、地方での労働力の過剰供給が見受けられ、労働力は都市部に流出し、治安・衛生の悪化及び社会政策費の増大を招いた。80年代には、[[石油]]産業従事者の増大に伴い、農業において労働力不足が顕著となる。このため綿花および綿製品の価格上昇を招き、国際競争力を失った。1990年代から、[[国際通貨基金|IMF]]の支援を受け経済成長率5%を達成するが、社会福祉政策の低所得者向け補助の増大および失業率10%前後と支出の増大に加え、資源に乏しく食料も輸入に頼るため、2004年には物価上昇率10%に達するなどの構造的問題を抱えている。現状、中小企業育成による国際競争力の強化、雇用創生に取り組んでいるが、結果が出ていない。[[2004年]]のナズィーフ内閣が成立後は、国営企業の民営化および税制改革に取り組んでいる。[[2008年]]、世界的な食料高騰によるデモが発生した。\n\nまた、「[[アラブの春]]」により、2012年~2014年の間は2~3%台と一時低迷していたが、その後政情の安定化により、2015年には、4%台に回復している。また[[IMF]]の勧告を受け、2016年に[[為替相場]]の大幅切り下げや[[補助金]]削減などの改革をしたことで、経済健全化への期待感より、外国からの資本流入が拡大していき、経済の復調を遂げている<ref name=\"エジプト経済の現状と今後の展望\" />。\n\n農業は農薬などを大量に使っているため世界一コストの高い農業となっているがそれなりの自給率を保っているし果物は日本にもジャムなどに加工され輸出されている。工業は石油などの資源はないが様々な工業が発展しており今後も成長が見込まれる。近年IT IC産業が急速に成長している。\nしかしながらGDPの約半分が軍関連企業が占めていて主に農業 建築業などの工業を担っている。\n金融はイスラーム銀行も近代式銀行の両方とも発達しており投資家層も厚くトランプ政権にはエジプトの敏腕女性投資家が起用されている。\n\n== 交通 ==\n{{Main|エジプトの交通}}\nエジプトの交通の柱は歴史上常に[[ナイル川]]であった。[[アスワン・ハイ・ダム]]の建設後、ナイル川の流れは穏やかになり、交通路として安定性が増した。しかし貨物輸送はトラック輸送が主となり、内陸水運の貨物国内シェアは2%にすぎない。[[ファルーカ]]という伝統的な[[帆船]]や、観光客用のリバークルーズなどの運航もある。\n\n[[鉄道]]は、国有の[[エジプト鉄道]]が運営している。営業キロは5,063キロにのぼり、カイロを起点として[[ナイル川デルタ]]や[[ナイル河谷]]の主要都市を結んでいる。\n\n航空は、[[フラッグ・キャリア]]である[[エジプト航空]]を筆頭にいくつもの航空会社が運行している。[[カイロ国際空港]]はこの地域の[[ハブ空港]]の一つである。\n\n== 国民 ==\n{{Main2|詳細は{{仮リンク|エジプトの人口統計|en|Demographics of Egypt}}}}\n[[ファイル:Cairo mosques.jpg|thumb|left|220px|[[カイロ]]の[[モスク]]]]\n=== 人口構成 ===\n[[ファイル:Egypt population pyramid 2005.svg|thumb|[[2005年]]の人口ピラミッド。30歳以下の若年層が非常に多く、若者の失業が深刻な問題となっている]]\n[[ファイル:Egypt demography.png|thumb|400px|[[国際連合食糧農業機関]]の2005年データによるエジプト人口の推移。1960年の3,000万人弱から人口が急増しているのが読み取れる]]\nエジプトの人口は8,254万人(2013年1月現在)で、近年急速に増大し続けている。年齢構成は0から14歳が33%、15から64歳が62.7%、65歳以上が4.3%(2010年)で、若年層が非常に多く、ピラミッド型の人口構成をしている。しかし、若年層はさらに増加傾向にあるにもかかわらず、経済はそれほど拡大していないため、若者の[[失業]]が深刻な問題となっており、[[2011年エジプト騒乱]]の原因のひとつともなった。年齢の中央値は24歳である。人口増加率は2.033%。\n\n=== 民族 ===\n{{See also|エジプト民族}}\n住民は[[ムスリム|イスラム教徒]]と[[キリスト教徒]]([[コプト教会]]、[[東方正教会]]など)からなる[[アラブ人]]がほとんどを占め、そのほかに[[ベドウィン]](遊牧民)や[[ベルベル人]]、{{仮リンク|ヌビア人|en|Nubian people}}、[[アルメニア人]]、[[トルコ人]]、[[ギリシア人]]などがいる。遺伝的に見れば、エジプト住民のほとんどが古代エジプト人の直系であり、[[エジプト民族]]との呼称でも呼ばれる所以である。また、エジプト人の大半は、イスラム勢力のエジプト征服とそれに続くイスラム系国家の統治の間に言語学的にアラブ化し、本来のエジプト語を捨てた人々であるとする見解がある。それだけではなく、長いイスラーム統治時代の人的交流と都市としての重要性から、多くのアラブ人が流入・定住していったのも事実である。1258年にアッバース朝が崩壊した際、[[カリフ]]周辺を含む多くの人々がエジプト(おもにカイロ近郊)へ移住したという史実は、中東地域一帯における交流が盛んであったことを示す一例である。現代においてカイロは[[世界都市]]となっており、また歴史的にも[[アル=アズハル大学]]は、イスラム教[[スンナ派]]で最高権威を有する教育機関として、中東・イスラム圏各地から人々が参集する。\n\nなお[[古代エジプト]]文明の印象があまりに大きいためか、特に現代エジプトに対する知識を多く持たない人は、現代のエジプト人を古代エジプト人そのままにイメージしていることが多い。すなわち、[[ギザの大スフィンクス]]や[[ギザの大ピラミッド]]を建て、太陽神やさまざまな神を信仰([[エジプト神話]])していた古代エジプト人を、現代のエジプト人にもそのまま当てはめていることが多い。しかし、上述のとおり現代エジプト人の9割はイスラム教徒であり、アラビア語を母語とするアラブ人である。それもアラブ世界の中で比較的主導的な立場に立つ、代表的なアラブ人のひとつである。\n\n=== 言語 ===\n{{Main2|詳細は{{仮リンク|エジプトの言語|en|Languages of Egypt}}}}\n現在のエジプトでは[[アラビア語]]が[[公用語]]である。これは、イスラムの征服当時にもたらされたもので、エジプトのイスラム化と同時に普及していった。ただし、公用語となっているのは[[正則アラビア語]](フスハー)だが、実際に用いられているのは[[アラビア語エジプト方言]]である{{要出典|date=2012年8月}}<!-- 実際に「通用」の意味か? 行政等の用語は? -->。\n\n古代エジプトの公用語であった[[エジプト語]](4世紀以降の近代エジプト語は[[コプト語]]の名で知られる)は、現在では少数のキリスト教徒が典礼言語として使用するほかはエジプトの歴史に興味を持つ知識層が学んでいるだけであり、これを話せる国民はきわめて少ない。日常言語としてコプト語を使用する母語話者は数十名程度である<ref>[http://www.dailystaregypt.com/article.aspx?ArticleID=106 The Dairy Star of Egypt 2007年1月23日]</ref>。他には地域的に[[ヌビア諸語]]、[[教育]]・[[ビジネス]]に[[英語]]、[[文化_(代表的なトピック)|文化]]においては[[フランス語]]なども使われている。\n\n=== 宗教 ===\n{{Main2|詳細は{{仮リンク|エジプトの宗教|en|Religion in Egypt}}}}\n{{bar box\n|title=宗教構成(エジプト)\n|titlebar=#ddd\n|width= 300px\n|float=right\n|bars=\n{{bar percent|イスラム教(スンナ派)|green|90}}\n{{bar percent|キリスト教その他|blue|10}}\n}}\n宗教は[[イスラム教]]が90%(ほとんどが[[スンナ派]])であり、[[憲法]]では[[国教]]に指定されている(既述の通り、現在では宗教政党の活動ならびにイスラム主義活動は禁止されている)<ref name=2010cia/>。その他の宗派では、エジプト土着の[[キリスト教会]]である[[コプト教会]]の信徒が9%、その他のキリスト教徒が1%となる<ref name=2010cia/>。\n\n=== 婚姻 ===\n多くの場合、婚姻時に女性は改姓しない([[夫婦別姓]])が、改姓する女性もいる<ref>[https://culturalatlas.sbs.com.au/egyptian-culture/naming-9bdb9e00-ffa6-4f6f-9b29-1616ec7bb952#naming-9bdb9e00-ffa6-4f6f-9b29-1616ec7bb952 Egyptian Culture], Cultural Atlas.</ref>。\n\n=== 教育 ===\n{{Main2|詳細は{{仮リンク|エジプトの教育|en|Education in Egypt}}}}\n[[ファイル:Bibalex-egypt.JPG|thumb|180px|[[新アレクサンドリア図書館]]]]\nエジプトの教育制度は、1999年から[[小学校]]の課程が1年延び、日本と同じく小学校6年・[[中学校]]3年・[[高等学校|高校]]3年・[[大学]]4年の6・3・3・4制となっている<ref>[http://www.mofa.go.jp/mofaj/toko/world_school/07africa/infoC70400.html 諸外国の学校情報(国の詳細情報) 日本国外務省]</ref>。[[義務教育]]は小学校と中学校の9年である。[[1923年]]のエジプト独立時に初等教育はすでに無料とされ、以後段階的に無料教育化が進み、[[1950年]]には著名な作家でもあった文部大臣[[ターハー・フセイン]]によって中等教育が無料化され、1952年のエジプト革命によって高等教育も含めたすべての公的機関による教育が無料化された。しかし、公立学校の[[教員]]が給料の少なさなどから個人の[[家庭教師]]を兼任することが広く行われており、社会問題化している<ref>[http://www.fukuoka-pu.ac.jp/kiyou/kiyo15_1/1501_tanaka.pdf 『福岡県立大学人間社会学部紀要』 田中哲也]</ref>。高額な授業料を取る代わりに教育カリキュラムの充実した私立学校も多数存在する。エジプト国内には、20万以上の小中学校、1,000万人以上の学生、13の主要大学、67の[[師範学校]]がある。\n\n[[2018年]]より「エジプト日本学校(EJS=Egypt-Japan School)」が35校、開校した<ref>[https://www.jica.go.jp/publication/mundi/1904/201904_03_01.html 「日本式教育」で、子どもたちが変わる! エジプト]</ref>\n<ref>[https://www.jica.go.jp/press/2018/20181004_01.html 「エジプト・日本学校」35校が開校:日本式教育をエジプトへ本格導入]</ref>。これは2017年に[[JICA]]が技術協力「学びの質向上のための環境整備プロジェクト」を開始ししたことに始まるもので、[[日本の学校教育]]で行われている[[学級会]]や生徒による清掃などをエジプトの教育に取り入れようとする教育方針である<ref>[https://www.nippon.com/ja/japan-topics/g00727/ エジプトの小学校に「日本式教育」、協調性など成果も]</ref>。試験的に導入した際には文化的な違いから反発も見受けられたが、校内での暴力が減った、子供が家でも掃除をするようになったなど、徐々に成果が見えるようになり本格的に導入されることになった<ref>[https://www.huffingtonpost.jp/entry/egypt-japan-school_jp_5cdba4c0e4b0c39d2a13534f 「日本式教育」はエジプトの教育現場をどう変えたか。「掃除は社会階層が低い人が行うもの」という反発を乗り越えて]</ref><ref>[https://egyptcesbtokyo.wordpress.com/2018/10/10/「エジプト・日本学校」について/ 「エジプト・日本学校」(EJS)について]</ref>。\n\n2005年の推計によれば、15歳以上の国民の[[識字率]]は71.4%(男性:83%、女性:59.4%)である<ref name=2010cia>[https://www.cia.gov/library/publications/the-world-factbook/geos/za.html CIA World Factbook \"Egypt\"]2010年1月31日閲覧。</ref>。2006年にはGDPの4.2%が教育に支出された<ref name=2010cia/>。\n\nおもな高等教育機関としては、[[アル=アズハル大学]](988年 p? )、[[吉村作治]]、[[小池百合子]]らが出身の[[カイロ大学]](1908年~)などが存在する。\n\n国立図書館として[[新アレクサンドリア図書館]]が存在する。\n\n== 文化 ==\n[[ファイル:Necip Mahfuz.jpg|thumb|[[ナギーブ・マフフーズ]]は[[1988年]]に[[ノーベル文学賞]]を受賞した]]\n{{Main2|詳細は{{仮リンク|エジプトの文化|en|Culture of Egypt}}}}\n\n* [[古代エジプト]]の建造物で有名。\n* [[ボードゲーム]]や[[カードゲーム]]の発祥の地としても知られている。\n* 座った時に足を組むと、相手に敵意があると受けとられる。\n\n=== 食文化 ===\n{{Main|エジプト料理}}\n\n=== 文学 ===\n{{Main|古代エジプト文学|アラビア語文学|エジプト文学}}\n古代エジプトにおいては[[パピルス]]に[[ヒエログリフ]]で創作がなされ、[[古代エジプト文学]]には『[[死者の書 (古代エジプト)|死者の書]]』や『[[シヌヘの物語]]』などの作品が現代にも残っている。7世紀にアラブ化したあともエジプトは[[アラビア語文学]]のひとつの中心地となった。近代の文学者として[[ターハー・フセイン]]の名が挙げられ、現代の作家である[[ナギーブ・マフフーズ]]は1988年に[[ノーベル文学賞]]を受賞している。\n{{clear}}\n\n=== スポーツ ===\n* [[サッカーエジプト代表]]の[[モハメド・サラー]]は[[プレミアリーグ]]で得点王、[[PFA年間最優秀選手賞]]を獲得、[[UEFAチャンピオンズリーグ 2018-19|2018-19シーズン]]に[[UEFAチャンピオンズリーグ]]優勝を果たした。\n* [[スカッシュ (スポーツ)|スカッシュ]]では[[21世紀]]に入ってからワールドオープン([[:en:World Squash Championships]])で男女ともに多くの優勝者を輩出している。\n\n=== 世界遺産 ===\n{{Main|エジプトの世界遺産}}\nエジプト国内には、[[国際連合教育科学文化機関|ユネスコ]]の[[世界遺産]]リストに登録された文化遺産が6件、自然遺産が1件登録されている。\n\n<gallery widths=\"180\" heights=\"120\">\nファイル:Egypt.Giza.Sphinx.01.jpg|[[メンフィスとその墓地遺跡|メンフィスとその墓地遺跡-ギーザからダハシュールまでのピラミッド地帯]](1979年、文化遺産)\nファイル:S F-E-CAMERON 2006-10-EGYPT-KARNAK-0002.JPG|古代都市[[テーベ]]とその墓地遺跡(1979年、文化遺産)\nファイル:Abou simbel face.jpg|[[アブ・シンベル]]から[[フィラエ]]までの[[ヌビア遺跡]]群(1979年、文化遺産)\nファイル:Al Azhar, Egypt.jpg|[[カイロ|カイロ歴史地区]](1979年、文化遺産)\nファイル:Katharinenkloster Sinai BW 2.jpg|* [[聖カタリナ修道院|聖カトリーナ修道院地域]](2002年、文化遺産)\nファイル:Whale skeleton 2.jpg|[[ワディ・アル・ヒタン]](2005年、自然遺産)\n</gallery>\n\n== 参考文献 ==\n*鈴木恵美編著『現代エジプトを知るための60章』、[[明石書店]]、2012年 ISBN 4750336483\n{{節スタブ}}\n\n== 脚注 ==\n{{脚注ヘルプ}}\n{{Reflist|2}}\n\n== 関連項目 ==\n* [[エジプト民族]]\n* [[エジプト美術]]\n* [[エジプト神話]]\n* [[エジプト軍]]\n* [[エジプト海軍艦艇一覧]]\n* [[エジプト革命 (2011年)]]\n* [[エジプトの法]]\n* [[エジプト関係記事の一覧]]\n\n== 外部リンク ==\n{{Wiktionary}}\n{{Commons&cat|Egypt|Egypt}}\n{{Wikivoyage|Egypt|エジプト{{en icon}}}}\n{{osm box|r|1473947}}\n{{ウィキポータルリンク|アフリカ|[[画像:Africa_satellite_orthographic.jpg|36px|ウィキポータルリンク アフリカ]]}}\n; 政府\n:* [http://www.egypt.gov.eg/arabic/home.aspx エジプト政府サービス・ポータル] {{ar icon}}\n:* [http://www.egypt.gov.eg/english/home.aspx エジプト政府サービス・ポータル] {{en icon}}\n:* [http://www.egypt.or.jp/index.html 在日エジプト大使館 エジプト学・観光局] - 「観光情報」と「基本情報」{{ja icon}}\n:\n; 日本政府\n:* [https://www.mofa.go.jp/mofaj/area/egypt/ 日本外務省 HP>各国・地域情勢>アフリカ>エジプト・アラブ共和国] {{ja icon}}\n:* [https://www.eg.emb-japan.go.jp/itprtop_ja/index.html 在エジプト日本国大使館] {{ja icon}}\n:** [https://www.eg.emb-japan.go.jp/itpr_ja/00_000035.html 在エジプト日本国大使館>エジプト情報]\n:\n; その他\n:* [https://www.jica.go.jp/index.html 独立行政法人 JICA 国際協力機構]\n:** [https://www.jica.go.jp/egypt/ HP>各国における取り組み>中東>エジプト生活情報]\n:** [https://libportal.jica.go.jp/fmi/xsl/library/public/ShortTermStayInformation/MiddleEast/Egypt-Short.pdf HP>世界の現状を知る>世界の様子(国別生活情報)>中東>エジプト短期滞在者用国別情報(2011)]\n:* [https://www.jetro.go.jp/world/africa/eg/ 独立行政法人 JETRO 日本貿易振興機構 HP>海外ビジネス情報>国・地域別情報>アフリカ>エジプト]\n:* [https://www.jccme.or.jp/08/08-07-08.html 財団法人 JCCME 中東協力センター HP>中東各国情報>エジプト]\n:* [https://wikitravel.org/ja/%E3%82%A8%E3%82%B8%E3%83%97%E3%83%88 ウィキトラベル旅行ガイド - エジプト] {{ja icon}}\n:* {{Wikiatlas|Egypt}} {{en icon}}\n:* {{CIA World Factbook link|eg|Egypt}} {{en icon}}\n:* {{dmoz|Regional/Africa/Egypt}} {{en icon}}\n\n{{アフリカ}}\n{{アジア}}\n{{OIC}}\n{{OIF}}\n{{NATOに加盟していない米国の同盟国}}\n{{Authority control}}\n{{Coord|30|2|N|31|13|E|type:city|display=title}}\n\n{{デフォルトソート:えしふと}}\n[[Category:エジプト|*]]\n[[Category:共和国]]\n[[Category:軍事政権]]\n[[Category:フランコフォニー加盟国]]"}
20. JSONデータの読み込み
Wikipedia記事のJSONファイルを読み込み,「イギリス」に関する記事本文を表示せよ.問題21-29では,ここで抽出した記事本文に対して実行せよ.
import json filename = 'jawiki-country.json' with open(filename, mode='r') as f: for line in f: line = json.loads(line) if line['title'] == 'イギリス': text_uk = line['text'] break # 確認 print(text_uk)
--- 出力 ---
{{redirect|UK}}
{{redirect|英国|春秋時代の諸侯国|英 (春秋)}}
{{Otheruses|ヨーロッパの国|長崎県・熊本県の郷土料理|いぎりす}}
{{基礎情報 国
|略名 =イギリス
・・・
21. カテゴリ名を含む行を抽出
記事中でカテゴリ名を宣言している行を抽出せよ.
^はデフォルトでは文字列全体の先頭にのみマッチします。 今回はすべての行をチェックしたいため、MULTILINEオプションを利用して、^を各行の先頭にマッチさせています。
import re pattern = r'^(.*\[\[Category:.*\]\].*)$' result = '\n'.join(re.findall(pattern, text_uk, re.MULTILINE)) print(result)
--- 出力 --- [[Category:イギリス|*]] [[Category:イギリス連邦加盟国]] [[Category:英連邦王国|*]] [[Category:G8加盟国]] [[Category:欧州連合加盟国|元]] [[Category:海洋国家]] [[Category:現存する君主国]] [[Category:島国]] [[Category:1801年に成立した国家・領域]]
22. カテゴリ名の抽出
記事のカテゴリ名を(行単位ではなく名前で)抽出せよ.
一部のカテゴリ名に含まれる「カテゴリ名|記号」の|以降を拾わないようにするために、カッコ内の正規表現にマッチはするが拾ってはこない(?:...)を利用しています。
pattern = r'^.*\[\[Category:(.*?)(?:\|.*)?\]\].*$' result = '\n'.join(re.findall(pattern, text_uk, re.MULTILINE)) print(result)
--- 出力 --- イギリス イギリス連邦加盟国 英連邦王国 G8加盟国 欧州連合加盟国 海洋国家 現存する君主国 島国 1801年に成立した国家・領域
23. セクション構造
記事中に含まれるセクション名とそのレベル(例えば”== セクション名 ==”なら1)を表示せよ.
('=='), ('セクション名'), ('==')のグループを抽出し、=の長さをもとにレベルも併せて表示しています。
pattern = r'^(\={2,})\s*(.+?)\s*(\={2,}).*$' result = '\n'.join(i[1] + ':' + str(len(i[0]) - 1) for i in re.findall(pattern, text_uk, re.MULTILINE)) print(result)
--- 出力 --- 国名:1 歴史:1 地理:1 主要都市:2 気候:2 ・・・
24. ファイル参照の抽出
記事から参照されているメディアファイルをすべて抜き出せ.
各行の先頭以外にも登場しているため、MULTILINEオプションを外しています。
pattern = r'\[\[ファイル:(.+?)\|' result = '\n'.join(re.findall(pattern, text_uk)) print(result)
--- 出力 --- Royal Coat of Arms of the United Kingdom.svg Descriptio Prime Tabulae Europae.jpg Lenepveu, Jeanne d'Arc au siège d'Orléans.jpg London.bankofengland.arp.jpg Battle of Waterloo 1815.PNG ・・・
25. テンプレートの抽出
記事中に含まれる「基礎情報」テンプレートのフィールド名と値を抽出し,辞書オブジェクトとして格納せよ.
# テンプレートの抽出 pattern = r'^\{\{基礎情報.*?$(.*?)^\}\}' template = re.findall(pattern, text_uk, re.MULTILINE + re.DOTALL) print(template) # フィールド名と値を辞書オブジェクトに格納 pattern = r'^\|(.+?)\s*=\s*(.+?)(?:(?=\n\|)|(?=\n$))' result = dict(re.findall(pattern, template[0], re.MULTILINE + re.DOTALL)) for k, v in result.items(): print(k + ': ' + v)
--- 出力 ---
・・・
標語: {{lang|fr|[[Dieu et mon droit]]}}<br />([[フランス語]]:[[Dieu et mon droit|神と我が権利]])
国歌: [[女王陛下万歳|{{lang|en|God Save the Queen}}]]{{en icon}}<br />''神よ女王を護り賜え''<br />{{center|[[ファイル:United States Navy Band - God Save the Queen.ogg]]}}
地図画像: Europe-UK.svg
位置画像: United Kingdom (+overseas territories) in the World (+Antarctica claims).svg
公用語: [[英語]]
・・・
26. 強調マークアップの除去
25の処理時に,テンプレートの値からMediaWikiの強調マークアップ(弱い強調,強調,強い強調のすべて)を除去してテキストに変換せよ.
以降、25で作成したresultに対して処理を行っていきます。
def remove_markup(text): # 強調マークアップの除去 pattern = r'\'{2,5}' text = re.sub(pattern, '', text) return text result_rm = {k: remove_markup(v) for k, v in result.items()} for k, v in result_rm.items(): print(k + ': ' + v)
--- 出力 ---
・・・
標語: {{lang|fr|[[Dieu et mon droit]]}}<br />([[フランス語]]:[[Dieu et mon droit|神と我が権利]])
国歌: [[女王陛下万歳|{{lang|en|God Save the Queen}}]]{{en icon}}<br />神よ女王を護り賜え<br />{{center|[[ファイル:United States Navy Band - God Save the Queen.ogg]]}}
地図画像: Europe-UK.svg
位置画像: United Kingdom (+overseas territories) in the World (+Antarctica claims).svg
公用語: [[英語]]
・・・
27. 内部リンクの除去
26の処理に加えて,テンプレートの値からMediaWikiの内部リンクマークアップを除去し,テキストに変換せよ.
def remove_markup(text): # 強調マークアップの除去 pattern = r'\'{2,5}' text = re.sub(pattern, '', text) # 内部リンクマークアップの除去 pattern = r'\[\[(?:[^|]*?\|)??([^|]*?)\]\]' text = re.sub(pattern, r'\1', text) return text result_rm = {k: remove_markup(v) for k, v in result.items()} for k, v in result_rm.items(): print(k + ': ' + v)
--- 出力 ---
・・・
標語: {{lang|fr|Dieu et mon droit}}<br />(フランス語:神と我が権利)
国歌: [[女王陛下万歳|{{lang|en|God Save the Queen}}]]{{en icon}}<br />神よ女王を護り賜え<br />{{center|ファイル:United States Navy Band - God Save the Queen.ogg}}
地図画像: Europe-UK.svg
位置画像: United Kingdom (+overseas territories) in the World (+Antarctica claims).svg
公用語: 英語
・・・
28. MediaWikiマークアップの除去
27の処理に加えて,テンプレートの値からMediaWikiマークアップを可能な限り除去し,国の基本情報を整形せよ.
def remove_markup(text): # 強調マークアップの除去 pattern = r'\'{2,5}' text = re.sub(pattern, '', text) # 内部リンクマークアップの除去 pattern = r'\[\[(?:[^|]*?\|)??([^|]*?)\]\]' text = re.sub(pattern, r'\1', text) # 外部リンクマークアップの除去 pattern = r'https?://[\w!?/\+\-_~=;\.,*&@#$%\(\)\'\[\]]+' text = re.sub(pattern, '', text) # htmlタグの除去 pattern = r'<.+?>' text = re.sub(pattern, '', text) # テンプレートの除去 pattern = r'\{\{(?:lang|仮リンク)(?:[^|]*?\|)*?([^|]*?)\}\}' text = re.sub(pattern, r'\1', text) return text result_rm = {k: remove_markup(v) for k, v in result.items()} for k, v in result_rm.items(): print(k + ': ' + v)
--- 出力 ---
・・・
標語: Dieu et mon droit(フランス語:神と我が権利)
国歌: [[女王陛下万歳|God Save the Queen]]{{en icon}}神よ女王を護り賜え{{center|ファイル:United States Navy Band - God Save the Queen.ogg}}
地図画像: Europe-UK.svg
位置画像: United Kingdom (+overseas territories) in the World (+Antarctica claims).svg
公用語: 英語
・・・
29. 国旗画像のURLを取得する
テンプレートの内容を利用し,国旗画像のURLを取得せよ.(ヒント: MediaWiki APIのimageinfoを呼び出して,ファイル参照をURLに変換すればよい)
import requests def get_url(text): url_file = text['国旗画像'].replace(' ', '_') url = 'https://commons.wikimedia.org/w/api.php?action=query&titles=File:' + url_file + '&prop=imageinfo&iiprop=url&format=json' data = requests.get(url) return re.search(r'"url":"(.+?)"', data.text).group(1) print(get_url(result))
--- 出力 --- https://upload.wikimedia.org/wikipedia/commons/a/ae/Flag_of_the_United_Kingdom.svg
理解を深めるためのオススメ教材

全100問の解答はこちら
FILMによる動きの大きいフレーム間の高品質な補間(Frame interpolation)

この記事では、FILMによって、連続したビデオフレームとは異なるような差分の大きいフレーム間でも滑らかに補間する方法を紹介します。
FLIMとは
FILM(Frame Interpolation for Large Motion)は、画像間、特に動きの大きい画像間を滑らかに補間するための手法です。
まずは、イメージをつかむために、公式プロジェクトページのサンプル動画をご覧ください。
かなり自然に補間されています。
続いて、フレームワークの概要です。

FILMは、2枚の画像から特徴量を抽出するFeature Extraction、画像間のピクセルレベルの対応関係を推定するFlow Estimation、補間イメージを生成するFusionの3要素で構成されています。
従来手法との大きな違いは、「高い解像度における大きな動きは、低い解像度における小さな動きと同視できる」という直感的な仮定のもの、スケールを下げながら生成される特徴量ピラミッド間において重みを共有することにより、スケールに依存しない動きの推定を可能にした点にあります。
この仕組みにより、FILMは比較的小さな動きだけでなく、大きな動きに対しても最良の補間結果を実現しています。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
環境設定
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、推論時にGPUを利用することができます。
※ 2022年10月よりGoogle Colaboratoryの料金プランがこちらの内容に変更されました。ご利用の際はご注意ください。
続いて、リポジトリのクローン、ライブラリのインストール・インポート、学習済みモデルのダウンロードを行います。
import os from pathlib import Path # リポジトリのクローン if not Path('./frame-interpolation').exists(): !git clone https://github.com/pytti-tools/frame-interpolation # ライブラリのインストール・インポート try: import frame_interpolation except ModuleNotFoundError: %pip install -r ./frame-interpolation/requirements_colab.txt %pip install ./frame-interpolation # 学習済みモデルのダウンロード share_id = '1GhVNBPq20X7eaMsesydQ774CgGcDGkc6' local_path = '/content' if not (Path(local_path) / 'saved_model').exists(): !pip install --upgrade gdown !gdown --folder {share_id}
次に、推論対象の画像をアップロードします。任意のフォルダを作成し、画像を格納しておきます。
frames_dir = 'frames'
!mkdir -p $frames_dir
モデル設定
パラメータを設定します。アップロードしたフレーム数を、recursive_interpolation_passesを
とすると、補間後のフレーム数は
となります。
output_videoを有効にすると、output_video_fpsに従って動画が出力されます。
recursive_interpolation_passes = 1 output_video = True output_video_fps = 30
推論
補間を実行します。frames_dir下に結果が保存されます。
from loguru import logger logger.info("Beginning interpolation...") if output_video: !python -m frame_interpolation.eval.interpolator_cli \ --model_path ./saved_model \ --pattern {frames_dir} \ --fps {output_video_fps} \ --output_video else: !python -m frame_interpolation.eval.interpolator_cli \ --model_path ./saved_model \ --pattern {frames_dir} \ logger.info("Interpolation comlpete.")
まずはサンプル画像に対する結果です。入力はこちらの2枚です。

補間結果がこちら。
言われてもまったく気づかないレベルで自然に補間されていることが分かります。
次に、Stable Diffusionで生成した画像を以下の記事の方法で動画化し、動画の離れた2フレーム間を対象として試してみます。
入力フレームはこちらの2枚です。

結果がこちら。
こちらも割と自然に繋がっているのではないでしょうか。
色々な用途に使えそうです。
チーム・カルポ 秀和システム 2021年08月31日頃
参考文献
【言語処理100本ノック 2020】第2章: UNIXコマンド【Python】

自然言語処理の問題集として有名な言語処理100本ノックの2020年版の解答例です。 この記事では、以下の第1章から第10章のうち、「第2章: UNIXコマンド」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNNとCNN
- 第10章: 機械翻訳
環境設定
コードの実行はGoogle Colaboratoryで行います。 以降の解答の実行結果をすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
第2章: UNIXコマンド
popular-names.txtは,アメリカで生まれた赤ちゃんの「名前」「性別」「人数」「年」をタブ区切り形式で格納したファイルである.以下の処理を行うプログラムを作成し,popular-names.txtを入力ファイルとして実行せよ.さらに,同様の処理をUNIXコマンドでも実行し,プログラムの実行結果を確認せよ.
指定のデータをダウンロードします。 Google Colaboratoryのセル上で下記のコマンドを実行すると、現在のディレクトリに対象のテキストファイルがダウンロードされます。
!wget https://nlp100.github.io/data/popular-names.txt
10. 行数のカウント
行数をカウントせよ.確認にはwcコマンドを用いよ.
本章の趣旨とは異なる気がしますが、今回は実際のデータ分析のシーンで出会うことが多いと思われるpandasを利用します。 まずは、データフレームとして読み込んでから各問の処理を行っていきます。また、問題文の指示に従い、コマンドでの結果の確認も行っています。
import pandas as pd df = pd.read_table('./popular-names.txt', header=None, sep='\t', names=['name', 'sex', 'number', 'year']) len(df)
--- 出力 --- 2780
wcはテキストファイルの行数や単語数を数えるためのコマンドです。ここでは-lを指定して、改行数(=行数)をカウントしています。
# 確認 !wc -l ./popular-names.txt
--- 出力 --- 2780 ./popular-names.txt
11. タブをスペースに置換
タブ1文字につきスペース1文字に置換せよ.確認にはsedコマンド,trコマンド,もしくはexpandコマンドを用いよ.
確認のみ行います。
sedコマンドを利用します。-eは処理内容の指定、最初のs/は正規表現を用いるための指示で、最後の/gは正規表現にマッチしたすべての文字列を置換することを意味します。そして、\t/ /でタブをスペースに変換することを表します(変換前 / 変換後)。また、head -n 5で最初の5行を表示しています。間の|はsedの出力をheadに渡すための記号です。
!sed -e 's/\t/ /g' ./popular-names.txt | head -n 5
--- 出力 --- Mary F 7065 1880 Anna F 2604 1880 Emma F 2003 1880 Elizabeth F 1939 1880 Minnie F 1746 1880
12. 1列目をcol1.txtに,2列目をcol2.txtに保存
各行の1列目だけを抜き出したものをcol1.txtに,2列目だけを抜き出したものをcol2.txtとしてファイルに保存せよ.確認にはcutコマンドを用いよ.
col1 = df['name'] col1.to_csv('./col1.txt', index=False) print(col1.head()) col2 = df['sex'] col2.to_csv('./col2.txt', index=False) print(col2.head())
--- 出力 --- 0 Mary 1 Anna 2 Emma 3 Elizabeth 4 Minnie Name: name, dtype: object 0 F 1 F 2 F 3 F 4 F Name: sex, dtype: object
# 確認 !cut -f 1 ./popular-names.txt | head -n 5 # popular-names.txtの1列目の最初の5行
--- 出力 --- Mary Anna Emma Elizabeth Minnie
!cut -f 2 ./popular-names.txt | head -n 5 # popular-names.txtの2列目の最初の5行
--- 出力 --- F F F F F
13. col1.txtとcol2.txtをマージ
12で作ったcol1.txtとcol2.txtを結合し,元のファイルの1列目と2列目をタブ区切りで並べたテキストファイルを作成せよ.確認にはpasteコマンドを用いよ.
col1 = pd.read_table('./col1.txt') col2 = pd.read_table('./col2.txt') merged_1_2 = pd.concat([col1, col2], axis=1) merged_1_2.to_csv('./merged_1_2.txt', sep='\t', index=False) merged_1_2.head()
--- 出力 ---
name sex
0 Mary F
1 Anna F
2 Emma F
3 Elizabeth F
4 Minnie F
# 確認 !paste ./col1_chk.txt ./col2_chk.txt | head -n 5
--- 出力 --- Mary F Anna F Emma F Elizabeth F Minnie F
14. 先頭からN行を出力
自然数Nをコマンドライン引数などの手段で受け取り,入力のうち先頭のN行だけを表示せよ.確認にはheadコマンドを用いよ.
N = input('>> ') df.head(int(N))
--- 出力 ---
name sex number year
1340 Linda F 99689 1947
1360 Linda F 96211 1948
1350 James M 94757 1947
1550 Michael M 92704 1957
1351 Robert M 91640 1947
# 確認 !head -n 5 ./popular-names.txt
--- 出力 --- Mary F 7065 1880 Anna F 2604 1880 Emma F 2003 1880 Elizabeth F 1939 1880 Minnie F 1746 1880
15. 末尾のN行を出力
自然数Nをコマンドライン引数などの手段で受け取り,入力のうち末尾のN行だけを表示せよ.確認にはtailコマンドを用いよ.
N = input('>> ') df.tail(int(N))
--- 出力 ---
name sex number year
2775 Benjamin M 13381 2018
2776 Elijah M 12886 2018
2777 Lucas M 12585 2018
2778 Mason M 12435 2018
2779 Logan M 12352 2018
# 確認 !tail -n 5 ./popular-names.txt
--- 出力 --- Benjamin M 13381 2018 Elijah M 12886 2018 Lucas M 12585 2018 Mason M 12435 2018 Logan M 12352 2018
16. ファイルをN分割する
自然数Nをコマンドライン引数などの手段で受け取り,入力のファイルを行単位でN分割せよ.同様の処理をsplitコマンドで実現せよ.
いろいろなやり方があると思いますが、ここではレコードの通番に対して、N分位点を算出するqcutを適用することでファイルをN分割するフラグを付与しています。
def split_file(N): tmp = df.reset_index(drop=False) df_cut = pd.qcut(tmp.index, N, labels=[i for i in range(N)]) df_cut = pd.concat([df, pd.Series(df_cut, name='sp')], axis=1) return df_cut N = input('>> ') df_cut = split_file(int(N)) df_cut['sp'].value_counts()
--- 出力 --- 9 278 8 278 7 278 6 278 5 278 4 278 3 278 2 278 1 278 0 278 Name: sp, dtype: int64
df_cut.head()
--- 出力 ---
name sex number year sp
0 Mary F 7065 1880 0
1 Anna F 2604 1880 0
2 Emma F 2003 1880 0
3 Elizabeth F 1939 1880 0
4 Minnie F 1746 1880 0
# コマンドによる分割 !split -l 200 -d ./popular-names.txt sp
17. 1列目の文字列の異なり
1列目の文字列の種類(異なる文字列の集合)を求めよ.確認にはcut, sort, uniqコマンドを用いよ.
指定の列で重複を除き、行数をカウントしています。
len(df.drop_duplicates(subset='name'))
--- 出力 --- 136
# 確認 !cut -f 1 ./popular-names.txt | sort | uniq | wc -l
--- 出力 --- 136
18. 各行を3コラム目の数値の降順にソート
各行を3コラム目の数値の逆順で整列せよ(注意: 各行の内容は変更せずに並び替えよ).確認にはsortコマンドを用いよ(この問題はコマンドで実行した時の結果と合わなくてもよい).
df.sort_values(by='number', ascending=False, inplace=True) df.head()
--- 出力 ---
name sex number year
1340 Linda F 99689 1947
1360 Linda F 96211 1948
1350 James M 94757 1947
1550 Michael M 92704 1957
1351 Robert M 91640 1947
# 確認 !cat ./popular-names.txt | sort -rnk 3 | head -n 5
--- 出力 --- Linda F 99689 1947 Linda F 96211 1948 James M 94757 1947 Michael M 92704 1957 Robert M 91640 1947
19. 各行の1コラム目の文字列の出現頻度を求め,出現頻度の高い順に並べる
各行の1列目の文字列の出現頻度を求め,その高い順に並べて表示せよ.確認にはcut, uniq, sortコマンドを用いよ.
df['name'].value_counts()
--- 出力 ---
James 118
William 111
Robert 108
John 108
Mary 92
...
Crystal 1
Rachel 1
Scott 1
Lucas 1
Carolyn 1
Name: name, Length: 136, dtype: int64
# 確認 !cut -f 1 ./popular-names.txt | sort | uniq -c | sort -rn
--- 出力 ---
118 James
111 William
108 Robert
108 John
92 Mary
理解を深めるためのオススメ教材


全100問の解答はこちら
【言語処理100本ノック 2020】第1章: 準備運動【Python】

自然言語処理の問題集として有名な言語処理100本ノックの2020年版の解答例です。 この記事では、以下の第1章から第10章のうち、「第1章: 準備運動」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNNとCNN
- 第10章: 機械翻訳
環境設定
コードの実行はGoogle Colaboratoryで行います。 以降の解答の実行結果をすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
第1章: 準備運動
00. 文字列の逆順
文字列”stressed”の文字を逆に(末尾から先頭に向かって)並べた文字列を得よ.
スライスは[開始位置:終了位置:移動幅]を指定して文字列を抽出します。このとき、開始位置を省略すると先頭から、終了位置を省略すると末尾までの範囲となります。また、移動幅にマイナスを指定すると、終了位置から順番に抽出されます。
str = 'stressed' ans = str[::-1] # 「先頭」から「末尾」まで「逆順の移動幅1」で ans
--- 出力 --- desserts
01. 「パタトクカシーー」
「パタトクカシーー」という文字列の1,3,5,7文字目を取り出して連結した文字列を得よ.
str = 'パタトクカシーー' ans = str[::2] # 「先頭」から「末尾」まで「移動幅2」で ans
--- 出力 --- パトカー
02. 「パトカー」+「タクシー」=「パタトクカシーー」
「パトカー」+「タクシー」の文字を先頭から交互に連結して文字列「パタトクカシーー」を得よ.
str1 = 'パトカー' str2 = 'タクシー' ans = ''.join([i + j for i, j in zip(str1, str2)]) # str1とstr2を同時にループ ans
--- 出力 --- パタトクカシーー
03. 円周率
“Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics.”という文を単語に分解し,各単語の(アルファベットの)文字数を先頭から出現順に並べたリストを作成せよ.
import re str = 'Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics.' str = re.sub('[,\.]', '', str) # ,と.を除去 splits = str.split() # スペースで区切って単語ごとのリストを作成 ans = [len(i) for i in splits] ans
--- 出力 --- [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8, 9, 7, 9]
04. 元素記号
“Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can.”という文を単語に分解し,1, 5, 6, 7, 8, 9, 15, 16, 19番目の単語は先頭の1文字,それ以外の単語は先頭に2文字を取り出し,取り出した文字列から単語の位置(先頭から何番目の単語か)への連想配列(辞書型もしくはマップ型)を作成せよ.
str = 'Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can.' splits = str.split() one_ch = [1, 5, 6, 7, 8, 9, 15, 16, 19] # 1文字を取り出す単語の番号リスト ans = {} for i, word in enumerate(splits): if i + 1 in one_ch: ans[word[:1]] = i + 1 # リストにあれば1文字を取得 else: ans[word[:2]] = i + 1 # なければ2文字を取得 ans
--- 出力 ---
{'H': 1, 'He': 2, 'Li': 3, 'Be': 4, 'B': 5, 'C': 6, 'N': 7, 'O': 8, 'F': 9, 'Ne': 10, 'Na': 11, 'Mi': 12, 'Al': 13, 'Si': 14, 'P': 15, 'S': 16, 'Cl': 17, 'Ar': 18, 'K': 19, 'Ca': 20}
05. n-gram
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,”I am an NLPer”という文から単語bi-gram,文字bi-gramを得よ.
ここでは、[lst[i:] for i in range(n)]で、1要素目始まり、2要素目始まり、…、n要素目始まりの要素列のリストを作成し、それらをzip関数に渡して前から順番に要素を抽出することで、連続するn要素からなる組を作っています。
なお、[lst[i:] for i in range(n)]の結果は1つのリストであるため、前に*をつけることでリストを展開し、それぞれの要素列に分けた上でzip関数に渡す必要があります。
def ngram(n, lst): # ex. # [str[i:] for i in range(2)] -> ['I am an NLPer', ' am an NLPer'] # zip(*[str[i:] for i in range(2)]) -> zip('I am an NLPer', ' am an NLPer') return list(zip(*[lst[i:] for i in range(n)])) str = 'I am an NLPer' words_bi_gram = ngram(2, str.split()) chars_bi_gram = ngram(2, str) print('単語bi-gram:', words_bi_gram) print('文字bi-gram:', chars_bi_gram)
--- 出力 ---
単語bi-gram: [('am', 'an'), ('I', 'am'), ('an', 'NLPer')]
文字bi-gram: [('I', ' '), (' ', 'N'), ('e', 'r'), ('a', 'm'), (' ', 'a'), ('n', ' '), ('L', 'P'), ('m', ' '), ('P', 'e'), ('N', 'L'), ('a', 'n')]
06. 集合
“paraparaparadise”と”paragraph”に含まれる文字bi-gramの集合を,それぞれ, XとYとして求め,XとYの和集合,積集合,差集合を求めよ.さらに,’se’というbi-gramがXおよびYに含まれるかどうかを調べよ.
前問で作成した関数ngramを利用します。また、返り値をset型に変換することで、重複があれば削除され、集合として扱うことができるようになります。
str1 = 'paraparaparadise' str2 = 'paragraph' X = set(ngram(2, str1)) Y = set(ngram(2, str2)) union = X | Y intersection = X & Y difference = X - Y print('X:', X) print('Y:', Y) print('和集合:', union) print('積集合:', intersection) print('差集合:', difference) print('Xにseが含まれるか:', {('s', 'e')} <= X) print('Yにseが含まれるか:', {('s', 'e')} <= Y)
--- 出力 ---
X: {('a', 'r'), ('a', 'p'), ('s', 'e'), ('p', 'a'), ('r', 'a'), ('i', 's'), ('d', 'i'), ('a', 'd')}
Y: {('p', 'h'), ('a', 'r'), ('a', 'p'), ('p', 'a'), ('g', 'r'), ('r', 'a'), ('a', 'g')}
和集合: {('p', 'h'), ('a', 'r'), ('a', 'p'), ('s', 'e'), ('p', 'a'), ('g', 'r'), ('r', 'a'), ('i', 's'), ('a', 'g'), ('d', 'i'), ('a', 'd')}
積集合: {('p', 'a'), ('r', 'a'), ('a', 'r'), ('a', 'p')}
差集合: {('d', 'i'), ('i', 's'), ('a', 'd'), ('s', 'e')}
Xにseが含まれるか: True
Yにseが含まれるか: False
07. テンプレートによる文生成
引数x, y, zを受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y=”気温”, z=22.4として,実行結果を確認せよ.
def generate_sentence(x, y, z): print(f'{x}時のとき{y}は{z}') generate_sentence(12, '気温', 22.4)
--- 出力 --- 12時のとき気温は22.4
08. 暗号文
与えられた文字列の各文字を,以下の仕様で変換する関数cipherを実装せよ. 英小文字ならば(219 - 文字コード)の文字に置換 その他の文字はそのまま出力 この関数を用い,英語のメッセージを暗号化・復号化せよ.
def cipher(str): rep = [chr(219 - ord(x)) if x.islower() else x for x in str] return ''.join(rep) message = 'the quick brown fox jumps over the lazy dog' message = cipher(message) print('暗号化:', message) message = cipher(message) print('復号化:', message)
--- 出力 --- 暗号化: gsv jfrxp yildm ulc qfnkh levi gsv ozab wlt 復号化: the quick brown fox jumps over the lazy dog
09. Typoglycemia
スペースで区切られた単語列に対して,各単語の先頭と末尾の文字は残し,それ以外の文字の順序をランダムに並び替えるプログラムを作成せよ.ただし,長さが4以下の単語は並び替えないこととする.適当な英語の文(例えば”I couldn’t believe that I could actually understand what I was reading : the phenomenal power of the human mind .”)を与え,その実行結果を確認せよ.
import random def shuffle(words): result = [] for word in words.split(): if len(word) > 4: # 長さが4超であればシャッフル word = word[:1] + ''.join(random.sample(word[1:-1], len(word) - 2)) + word[-1:] result.append(word) return ' '.join(result) words = "I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind ." ans = shuffle(words) ans
--- 出力 --- I conuld't bivelee that I cloud actlaluy utnensardd what I was radineg : the pheanomnel peowr of the hmaun mind .
理解を深めるためのオススメ教材


全100問の解答はこちら
Stable Diffusionを使った顔動画の自由なスタイル変換

この記事では、Stable Diffusionによるスタイル変換とThin Plate Spline Motion Modelによるモーショントレースを組み合わせて、人の顔の動画を簡単にスタイル変換する方法を紹介します。
概要
Stable DIffusionのimage-to-imageは、任意のプロンプトに合わせて元画像をハイクオリティに変換することができます。ここでは、これを利用して、好きな動画の1フレーム目だけをimage-to-imageで変換後、元動画のモーションをThin Plate Spline Motion Modelでトレースすることで、動画全体を様々なスタイルに変換してみます。
image-to-image、Thin Plate Spline Motion Modelの詳細は、それぞれ以下の記事をご覧ください。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
環境設定
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、推論時にGPUを利用することができます。
※ 2022年10月よりGoogle Colaboratoryの料金プランがこちらの内容に変更されました。ご利用の際はご注意ください。
次に、必要なライブラリのインストール、インポート、リポジトリのクローン、関数の定義を行います。
# ライブラリのインストール !pip install -qq diffusers==0.3.0 transformers scipy ftfy !pip install -qq imageio-ffmpeg # リポジトリのクローン !git clone https://github.com/yoyo-nb/Thin-Plate-Spline-Motion-Model.git # ライブラリのインポート import os import shutil import warnings import numpy as np from PIL import Image import imageio from skimage import img_as_ubyte import matplotlib.pyplot as plt import matplotlib.animation as animation from skimage.transform import resize from IPython.display import HTML import cv2 import torch from torch import autocast from diffusers import StableDiffusionImg2ImgPipeline warnings.filterwarnings('ignore') # 描画関数の定義 def image_grid(imgs, rows, cols): assert len(imgs) == rows * cols w, h = imgs[0].size grid = Image.new('RGB', size=(cols * w, rows * h)) grid_w, grid_h = grid.size for i, img in enumerate(imgs): grid.paste(img, box=(i % cols * w, i // cols * h)) return grid # 前処理関数の定義 def preprocess(image): w, h = image.size w, h = map(lambda x: x - x % 32, (w, h)) image = image.resize((w, h), resample=Image.LANCZOS) image = np.array(image).astype(np.float32) / 255.0 image = image[None].transpose(0, 3, 1, 2) image = torch.from_numpy(image) return 2. * image - 1.
続いて、Stable Diffusionの学習済みモデルを利用するために、Hugging Faceにログインしておきます。以下のセルを実行後、表示される入力欄にアクセストークンを入力します。アクセストークンの取得方法はこちらの記事をご確認ください。
from huggingface_hub import notebook_login notebook_login()
対象動画の準備
対象の動画をアップロードします。以下のコードでは正方形に近いものを想定しています。
uploaded = files.upload()
動画をフレームに分割します。
# 動画ファイルパスの取得 video_path = os.path.join('/content', list(uploaded.keys())[0]) # 保存ディレクトリの作成 frame_dir = '/content/frames/' if os.path.exists(frame_dir): shutil.rmtree(frame_dir) if not os.path.exists(frame_dir): os.makedirs(frame_dir) # 動画のフレーム分割 cmd = "ffmpeg -i %s -start_number 0 -vsync 0 %s/%%03d.png" % ( video_path, frame_dir, ) os.system(cmd)
今回の対象動画の1フレーム目はこちら。この記事よりお借りしています。

これで動画の準備は完了です。
Stable Diffusionによるimage-to-image
では、image-to-imageを実施します。ここではアニメ調に変換してみます。
# プロンプトの設定 prompt = 'Portrait of a female, defined facial features, highly detailed, animation cel, official Kyoto Animation and Studio Ghibli anime screenshot, by Makoto Shinkai and Range Murata' # 学習済みモデルのダウンロード pipe = StableDiffusionImg2ImgPipeline.from_pretrained( 'CompVis/stable-diffusion-v1-4', revision='fp16', torch_dtype=torch.float16, use_auth_token=True ).to('cuda') # 出力ディレクトリの作成 output_dir = '/content/output' !mkdir -p $output_dir if os.path.exists(output_dir): shutil.rmtree(output_dir) if not os.path.exists(output_dir): os.makedirs(output_dir) # 生成画像数の設定 num = 30 # 初期画像の読込 image_file = '/content/frames/000.png' original_image = Image.open(image_file).convert('RGB') resized_image = original_image.resize((512, 512)) init_image = preprocess(resized_image) plt.imshow(resized_image) plt.axis('off') plt.title('before processing') # 画像の生成 images = [] for i in range(num): with autocast('cuda'): image = pipe(prompt=prompt, init_image=init_image, strength=0.7)['images'][0] image.save(os.path.join(output_dir, f'{i:03d}.png')) images.append(image) # 結果の描画 image_grid(images, 6, 5)
上記のコードでは30枚を生成しています。枚数は求める完成度に応じて増減してください。
ここでは、以下の1枚を採用しました。
# 画像番号の指定 image_idx = '009' # 選択した画像の通番 # 選択画像の読込 image_file = os.path.join(output_dir, f'{image_idx}.png') image = Image.open(image_file).convert('RGB') plt.imshow(image) plt.axis('off') plt.title('selected image');

Thin Plate Spline Motion Modelによるモーショントレース
変換した1フレームに対して、元動画からモーションをコピーします。
# パッケージのインポート %cd Thin-Plate-Spline-Motion-Model from demo import load_checkpoints from demo import make_animation # パラメータ設定 device = torch.device('cuda:0') dataset_name = 'vox' source_image_path = image_file driving_video_path = video_path output_video_path = '/content/result.mp4' config_path = 'config/vox-256.yaml' checkpoint_path = 'checkpoints/vox.pth.tar' predict_mode = 'relative' find_best_frame = False pixel = 256 # トレース先の画像・トレース元の動画の読込 source_image = imageio.imread(source_image_path) reader = imageio.get_reader(driving_video_path) fps = reader.get_meta_data()['fps'] source_image = resize(source_image, (pixel, pixel))[..., :3] driving_video = [] try: for im in reader: driving_video.append(im) except RuntimeError: pass reader.close() driving_video = [resize(frame, (pixel, pixel))[..., :3] for frame in driving_video] def display(source, driving, generated=None): fig = plt.figure(figsize=(8 + 4 * (generated is not None), 6)) ims = [] for i in range(len(driving)): cols = [source] cols.append(driving[i]) if generated is not None: cols.append(generated[i]) im = plt.imshow(np.concatenate(cols, axis=1), animated=True) plt.axis('off') ims.append([im]) ani = animation.ArtistAnimation(fig, ims, interval=50, repeat_delay=1000) plt.close() return ani # 学習済みパラメータのダウンロード !mkdir -p checkpoints !wget -c https://cloud.tsinghua.edu.cn/f/da8d61d012014b12a9e4/?dl=1 -O checkpoints/vox.pth.tar # 学習済みパラメータのロード inpainting, kp_detector, dense_motion_network, avd_network = load_checkpoints(config_path = config_path, checkpoint_path = checkpoint_path, device = device) # トレースの実行 predictions = make_animation(source_image, driving_video, inpainting, kp_detector, dense_motion_network, avd_network, device = device, mode = predict_mode) # 結果の保存 result_dir = '/content/result' if os.path.exists(result_dir): shutil.rmtree(result_dir) if not os.path.exists(result_dir): os.makedirs(result_dir) for i, frame in enumerate(predictions): cv2.imwrite(os.path.join(result_dir, f'{i:03d}.png'), img_as_ubyte(frame)[:, :, ::-1]) imageio.mimsave(output_video_path, [img_as_ubyte(frame) for frame in predictions], fps=fps) # 描画 HTML(display(source_image, driving_video, predictions).to_html5_video())
結果は、フレームごとに/content/resultに保存されます。
別途実行した、ヒューマノイド風、少女風も含めた最終的な結果がこちらです。
まとめ
動画スタイル変換の数ある手法のうちの一つですが、1枚目のみをスタイル変換の基準とするため、Stable Diffusionの結果を厳選しやすい点、全体的に高速である点でオススメです。リンク先のcolabファイルでは、動画をアップロードするだけで上記のすべての処理を再現可能なので、ぜひ試してみてください。
参考文献
High-Resolution Image Synthesis with Latent Diffusion Models
VToonifyによる実写動画の好きなスタイルでのアニメ化

この記事では、VToonifyを用いて、人の顔の画像や動画を、好きなスタイルでアニメ化する方法を紹介します。
VToonifyとは
VToonifyは、パラメータを自由に調整しながら、動画のスタイル変換を高解像度で行うフレームワークです。
実際のイメージはこちらの3分の公式動画をぜひご覧ください。パラメータをぐりぐり動かして結果が変わっていく様子がよく分かります。
VToonifyのネットワークのイメージは下図のとおりです。Eはencoder、Gはgeneratorを表します。
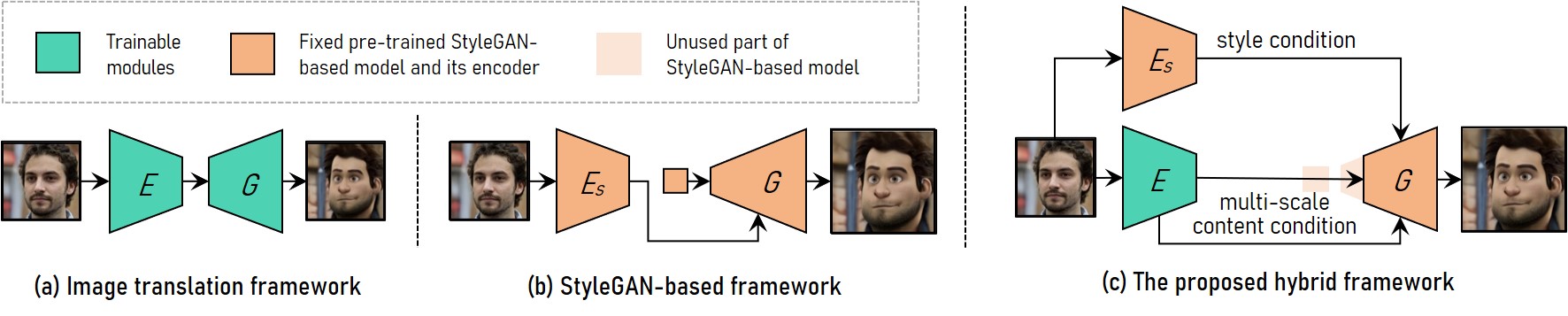
従来のStyleGANベースのフレームワーク(b)は、高解像度のスタイル変換を実現することはできたものの、あらかじめ固定されたサイズにクロップする必要があるという制約がありました。一方、StyleGANから学習用のペア画像を生成し、それによってスタイル変換を学習するというフレームワーク(a)は、入力サイズの制限はないものの、StyleGANの特徴である柔軟なコントロールができません。
そこで、本手法では、(b)のベースは維持したまま、サイズに依存しない(a)のencoderを組み合わせることで、双方のメリットを取り入れたフレームワーク(c)を実現しています。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、環境設定等のすべてのコードを含むノートブックは、以下のリンクから直接参照することができます。
![]()
モデル設定
上記のcolabファイルに沿って環境設定が完了したら、利用するモデルを選択します。提供されている学習済みモデルは7種類あるので、変換後のイメージに合わせて選んでいきます。
style_type = "pixar052" # cartoon026: balanced # cartoon299: big eyes # arcane000: for female # arcane077: for male # pixar052 # caricature039: big mouth # caricature068: balanced
選択したモデルをダウンロードします。
# ダウンロード用関数定義 def get_download_model_command(file_id, file_name): """ Get wget download command for downloading the desired model and save to directory ../checkpoint/. """ current_directory = os.getcwd() save_path = MODEL_DIR if not os.path.exists(save_path): os.makedirs(save_path) url = r"""wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id={FILE_ID}' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id={FILE_ID}" -O {SAVE_PATH}/{FILE_NAME} && rm -rf /tmp/cookies.txt""".format(FILE_ID=file_id, FILE_NAME=file_name, SAVE_PATH=save_path) return url MODEL_PATHS = { "encoder": {"id": "1NgI4mPkboYvYw3MWcdUaQhkr0OWgs9ej", "name": "encoder.pt"}, "faceparsing": {"id": "1jY0mTjVB8njDh6e0LP_2UxuRK3MnjoIR", "name": "faceparsing.pth"}, "arcane_exstyle": {"id": "1TC67wRJkdmNRZTqYMUEFkrhWRKKZW40c", "name": "exstyle_code.npy"}, "caricature_exstyle": {"id": "1xr9sx_WmRYJ4qHGTtdVQCSxSo4HP3-ip", "name": "exstyle_code.npy"}, "cartoon_exstyle": {"id": "1BuCeLk3ASZcoHlbfT28qNru4r5f-hErr", "name": "exstyle_code.npy"}, "pixar_exstyle": {"id": "1yTaKuSrL7I0i0RYEEK5XD6GI-y5iNUbj", "name": "exstyle_code.npy"}, "arcane000": {"id": "1pF4fJ8acmawMsjjXo4HXRIOXeZR8jLVh", "name": "generator.pt"}, "arcane077": {"id": "16rLTF2oC0ZeurnM6hjrfrc8BxtW8P8Qf", "name": "generator.pt"}, "caricature039": {"id": "1C1E4WEoDWzl0nAxR9okKffFmlMOENbeF", "name": "generator.pt"}, "caricature068": {"id": "1B1ko1x8fX2aJ4BYCL12AnknVAi3qQc8W", "name": "generator.pt"}, "cartoon026": {"id": "1YJYODh_vEyUrL0q02okjcicpJhdYY8An", "name": "generator.pt"}, "cartoon299": {"id": "101qMUMfcI2qDxEbfCBt5mOg2aSqdTaIt", "name": "generator.pt"}, "pixar052": {"id": "16j_l1x0DD0PjwO8YdplAk69sh3-v95rr", "name": "generator.pt"}, "cartoon": {"id": "11s0hwhZWTLacMAzZH4OU-o3Qkp54h30J", "name": "generator.pt"}, } # download pSp encoder and face parsinf network path = MODEL_PATHS["encoder"] download_command = get_download_model_command(file_id=path["id"], file_name=path["name"]) !{download_command} path = MODEL_PATHS["faceparsing"] download_command = get_download_model_command(file_id=path["id"], file_name=path["name"]) !{download_command} # download vtoonify path = MODEL_PATHS[style_type] download_command = get_download_model_command(file_id=path["id"], file_name = style_type + '_' + path["name"]) !{download_command} # download extrinsic style code path = MODEL_PATHS[style_type[:-3]+'_exstyle'] download_command = get_download_model_command(file_id=path["id"], file_name = style_type[:-3] + '_' + path["name"]) !{download_command}
ダウンロードしたモデル群をロードします。
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5],std=[0.5,0.5,0.5]),
])
vtoonify = VToonify(backbone = 'dualstylegan')
vtoonify.load_state_dict(torch.load(os.path.join(MODEL_DIR, style_type+'_generator.pt'), map_location=lambda storage, loc: storage)['g_ema'])
vtoonify.to(device)
parsingpredictor = BiSeNet(n_classes=19)
parsingpredictor.load_state_dict(torch.load(os.path.join(MODEL_DIR, 'faceparsing.pth'), map_location=lambda storage, loc: storage))
parsingpredictor.to(device).eval()
modelname = './checkpoint/shape_predictor_68_face_landmarks.dat'
if not os.path.exists(modelname):
import wget, bz2
wget.download('http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2', modelname+'.bz2')
zipfile = bz2.BZ2File(modelname+'.bz2')
data = zipfile.read()
open(modelname, 'wb').write(data)
landmarkpredictor = dlib.shape_predictor(modelname)
pspencoder = load_psp_standalone(os.path.join(MODEL_DIR, 'encoder.pt'), device)
exstyles = np.load(os.path.join(MODEL_DIR, style_type[:-3]+'_exstyle_code.npy'), allow_pickle='TRUE').item()
stylename = list(exstyles.keys())[int(style_type[-3:])]
exstyle = torch.tensor(exstyles[stylename]).to(device)
with torch.no_grad():
exstyle = vtoonify.zplus2wplus(exstyle)
推論
まずは、静止画をスタイル変換してみます。
import os from google.colab import files # 画像のアップロード uploaded = files.upload() # ファイルパスの取得 image_path = list(uploaded.keys())[0] # 画像の読込 original_image = load_image(image_path) # 顔の切出し frame = cv2.imread(image_path) frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) scale = 1 kernel_1d = np.array([[0.125],[0.375],[0.375],[0.125]]) paras = get_video_crop_parameter(frame, landmarkpredictor, padding=[200,200,200,200]) if paras is not None: h, w, top, bottom, left, right, scale = paras H, W = int(bottom-top), int(right-left) if scale <= 0.75: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) if scale <= 0.375: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) frame = cv2.resize(frame, (w, h))[top:bottom, left:right] x = transform(frame).unsqueeze(dim=0).to(device) # 描画 visualize(original_image[0], 30)
元画像はこちらです。

ちなみに、このオリジナル画像自体もStable Diffusionで生成したものです。
推論を実行します。
with torch.no_grad(): I = align_face(frame, landmarkpredictor) I = transform(I).unsqueeze(dim=0).to(device) s_w = pspencoder(I) s_w = vtoonify.zplus2wplus(s_w) s_w[:,:7] = exstyle[:,:7] x_p = F.interpolate(parsingpredictor(2*(F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)))[0], scale_factor=0.5, recompute_scale_factor=False).detach() inputs = torch.cat((x, x_p/16.), dim=1) y_tilde = vtoonify(inputs, s_w.repeat(inputs.size(0), 1, 1), d_s = 0.5) y_tilde = torch.clamp(y_tilde, -1, 1) # 描画 visualize(y_tilde[0].cpu(), 60)
左上がオリジナルで、右上がcartoon026、左下がcartoon299、右下がpixar052による変換後です。

続いて、動画のスタイル変換を試してみます。
# 動画のアップロード uploaded = files.upload() # ファイルパスの取得 video_path = list(uploaded.keys())[0] # 動画の読込 video_cap = cv2.VideoCapture(video_path) num = int(video_cap.get(7)) success, frame = video_cap.read() if success == False: assert('load video frames error') frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 顔の切出し scale = 1 kernel_1d = np.array([[0.125],[0.375],[0.375],[0.125]]) paras = get_video_crop_parameter(frame, landmarkpredictor, padding=[200,200,200,200]) if paras is None: print('no face detected!') else: h,w,top,bottom,left,right,scale = paras H, W = int(bottom-top), int(right-left) if scale <= 0.75: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) if scale <= 0.375: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) frame = cv2.resize(frame, (w, h))[top:bottom, left:right]
# 推論 fourcc = cv2.VideoWriter_fourcc(*'mp4v') videoWriter = cv2.VideoWriter(os.path.join(OUT_DIR, 'result.mp4'), fourcc, video_cap.get(5), (4*W, 4*H)) batch_size = 4 with torch.no_grad(): batch_frames = [] for i in tqdm(range(num)): if i == 0: I = align_face(frame, landmarkpredictor) I = transform(I).unsqueeze(dim=0).to(device) s_w = pspencoder(I) s_w = vtoonify.zplus2wplus(s_w) s_w[:,:7] = exstyle[:,:7] else: success, frame = video_cap.read() frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) if scale <= 0.75: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) if scale <= 0.375: frame = cv2.sepFilter2D(frame, -1, kernel_1d, kernel_1d) frame = cv2.resize(frame, (w, h))[top:bottom, left:right] batch_frames += [transform(frame).unsqueeze(dim=0).to(device)] if len(batch_frames) == batch_size or (i+1) == num: x = torch.cat(batch_frames, dim=0) batch_frames = [] x_p = F.interpolate(parsingpredictor(2*(F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)))[0], scale_factor=0.5, recompute_scale_factor=False).detach() inputs = torch.cat((x, x_p/16.), dim=1) y_tilde = vtoonify(inputs, s_w.repeat(inputs.size(0), 1, 1), d_s = 0.5) y_tilde = torch.clamp(y_tilde, -1, 1) for k in range(y_tilde.size(0)): videoWriter.write(tensor2cv2(y_tilde[k].cpu())) videoWriter.release() video_cap.release() viz = torchvision.utils.make_grid(y_tilde, 2, 2) visualize(viz.cpu(), 120)
結果は ./output/result.mp4に保存されます。
先ほどと同様、左上がオリジナルで、右上がcartoon026、左下がcartoon299、右下がpixar052による変換後です。
かなり自然に変換されていることが分かります。
公開されているコードを使って、公式動画にあるように連続的にスタイルを変化させていくことも可能です。
まとめ
高速に推論できて、かつ好きなスタイルに調整できることで、従来に比べて応用範囲が大きく広がりそうな技術です。任意の動画をアップロードするだけで簡単に試すことができるので、ぜひ遊んでみてください。
チーム・カルポ 秀和システム 2021年08月31日頃