



DreamBoothによる好きな対象を主役にした画像生成

この記事では、DreamBoothを用いて、自分の持ち物や飼い犬といった任意の対象を主役として、好きなシチュエーションをテキストで指定して画像を生成する方法を紹介します。
DreamBoothとは
概要
DreamBoothとは、Google Researchによる研究で、自分の持ち物や飼い犬といった特定の対象を含む画像を数枚用いて、テキストから画像を生成するモデルをファインチューニングすることで、「ビーチにいるその犬」や「カラフルなカーペットの上を歩くその犬」のような、その対象を含む画像を自由に生成することができるフレームワークです。
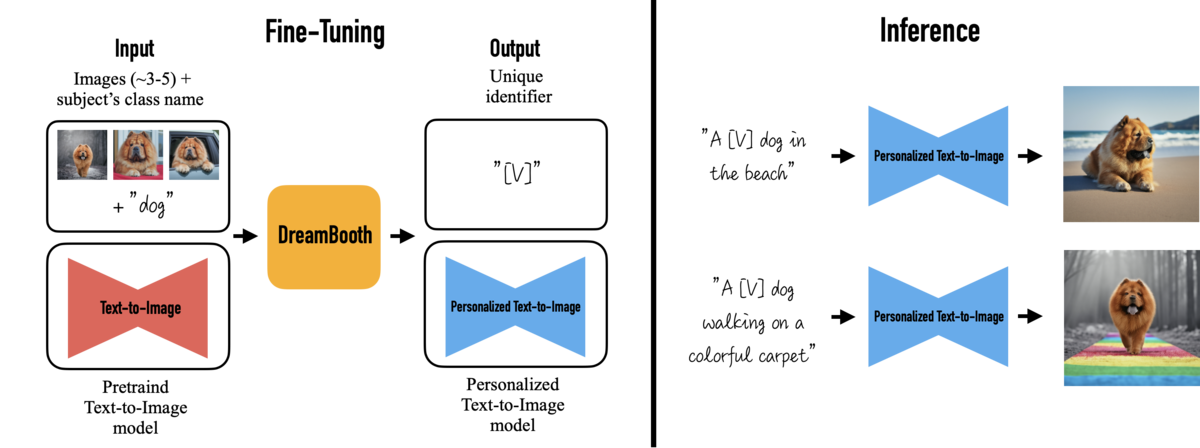

テキストから画像を生成するモデルでは、例えば「ビーチにいる犬」という指定をすれば、その通りの画像を生成することができますが、学習データに多数含まれるような世界的に有名な犬でもない限り、特定の犬を指定することはできません。
しかし、DreamBoothを使えば、自分の飼い犬の数枚の画像でモデルをファインチューニングすることで、その犬を主役に、テキストで好きなシチュエーションを指定して画像を生成できるようになります。
Textual Inversionとの違い
似た考え方にTextual Inversionがあります。
こちらも、数枚のオリジナル画像を用いてモデルをファインチューニングする点ではDreamBoothと同様ですが、Textual Inversionはその対象を示すキーワードのベクトル化部分(embedding)の重みのみを更新するのに対し、DreamBoothではモデル全体を更新します。
つまり、前者では、○○風といった追加した対象の「ニュアンス」を表現することができるようになるのに対し、後者では、追加した対象「そのもの」を忠実に生成することができるようになる点に大きな違いがあります。
Textual Inversionの詳細はこちらの記事をご覧ください。
Stable Diffusionへの置換え
もっとも、Google ResearchによるDreamBoothはテキストから画像を生成するモデルとしてImagenを採用していましたが、Imagenはモデルのネットワークも学習済みの重みも公開されていません。そのため、オリジナルのDreamBoothを個人が自由にファインチューニングすることはできませんでした。
しかし、最近になって別のチームがDreamBoothをオープンソースのStable Diffusionベースに置き換えたことにより、そのネックが解消されつつあります。
例えば、上記リポジトリのissueには、こちらのようなギターの画像13枚を学習データとしてファインチューニングした結果が投稿されています。

学習後に対象のギターを生成するプロンプトを実行した結果がこちら。

ジミ・ヘンドリックスが対象のギターを弾いている画像を生成するプロンプトを実行した結果がこちら。

かなり高精度に対象そのものが再現されているように見えます。
今回はこの実装をGoogle Colaboratoryで試してみたいと思います。
Stable Diffusionの概要や通常の使い方については以下の記事をご覧ください。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
※ 2022年9月時点において、公式リポジトリのコードを利用した本記事の方法は、Google Colaboratoryで提供されているプランのうち、Pro+で割り当てられることのあるA100以外では、GPUメモリが不足することを確認しています。それ以外のプランをご利用の方はこちらをお試しください。
事前準備
まず、モデルが公開されているHugging Faceのアカウントを作成します。
Hugging Faceのトップページから右上の「Sign Up」に進みます。アドレスとパスワードを入力すると、登録したアドレスに認証メールが届くので、メール内のリンクをクリックして作成は完了です。
そして、学習済みパラメータをダウンロードできるようにするために、Stable Diffusionのリポジトリを開き「Access repository」をクリックします。
これで事前準備は完了です。
環境設定
ここからは、Google Colaboratory上で作業を行います。
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、学習・推論時にGPUを利用することができます。
次に、ファインチューニングしたパラメータを保存するために、Googleドライブをマウントしておきます。
#Googleドライブのマウントと作業フォルダの作成 from google.colab import drive drive.mount('/content/drive') !mkdir -p /content/drive/MyDrive/Dreambooth'
続いて、リポジトリのクローンとライブラリのインストールを行います。環境構築の方法は様々ですが、今回はcolab上にMinicondaをインストールし、conda環境を作成します。
# リポジトリのクローン !git clone https://github.com/XavierXiao/Dreambooth-Stable-Diffusion.git %cd Dreambooth-Stable-Diffusion # condacolabのインストール !pip install -q condacolab import condacolab condacolab.install() # 仮想環境の作成 !conda env create -f environment.yaml
モデル設定
ファインチューニングのベースとなる、Stable Diffusionの学習済みのパラメータをダウンロードします。
# Hugging Faceのログイン情報の設定 username = 'ユーザーネームを記載' password = 'パスワードを記載' # Stable Diffusionの学習済みパラメータのダウンロード !mkdir -p weights !wget --http-user=$username --http-passwd=$password https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4-full-ema.ckpt -P weights/sd-v1-4-full-ema.ckpt
学習
今回は、片桐仁さんをDreamBoothの対象にしたいと思います。ファインチューニングに利用する学習用の画像はこちらです。結果に応じて、だいたい10枚から50枚程度準備するのが良さそうです。

これらは、colab上の任意のディレクトリにアップロードしておきます。
もっとも、もともとベースのStable Diffusionの学習データに片桐仁さんの画像が含まれており、ファインチューニングしなくても指名が可能であるとすると意味がありません。そこで、念のため"photo of JIN KATAGIRI"で画像を生成してみます。詳しい生成方法はこちらの記事をご覧ください。

存じ上げない方々です。これは、含まれていないといってよいかと思います。
では、ファインチューニングの準備を進めます。まず、DreamBoothの対象が属するカテゴリの画像を生成します。これは、ファインチューニングの際に、基準画像としてモデルに渡されます。今回は、manの画像を以下のコードで生成します。枚数は、リポジトリで推奨されている200枚とします(対象によっては300枚~400枚程度の方が生成結果が安定するケースもあるようです)。
%%bash
eval "$(conda shell.bash hook)"
conda activate ldm
python scripts/stable_txt2img.py --ddim_eta 0.0 \
--n_samples 200 \
--n_iter 1 \
--scale 10.0 \
--ddim_steps 50 \
--ckpt weights/sd-v1-4-full-ema.ckpt/sd-v1-4-full-ema.ckpt \
--prompt "a photo of a man"
conda deactivate
このような画像が生成されます。

ファインチューニングを実行します。
%%bash
eval "$(conda shell.bash hook)"
conda activate ldm
python main.py --base configs/stable-diffusion/v1-finetune_unfrozen.yaml \
-t \
-n test \
--actual_resume weights/sd-v1-4-full-ema.ckpt/sd-v1-4-full-ema.ckpt \
--gpus 0, \
--data_root "ファインチューニング用の画像を配置したディレクトリ" \
--reg_data_root "/content/Dreambooth-Stable-Diffusion/outputs/txt2img-samples/samples" \
--class_word man \
--no-test
conda deactivate
OSError: cannot open resourceが表示される場合は、こちらのissueをご参照ください。
学習したパラメータは、/content/Dreambooth-Stable-Diffusion/logs以下に保存されるので、必要に応じてGoogleドライブにコピーしておきます。
!cp /content/Dreambooth-Stable-Diffusion/logs/<ckptファイルが保存された場所>/checkpoints/last.ckpt /content/drive/MyDrive/Dreambooth/last.ckpt
推論
では、ファインチューニングしたパラメータで画像を生成してみます。プロンプト内のsksは、DreamBoothの対象を指すランダムな文字列で、リポジトリのデフォルトの文字列をそのまま利用しているものです。ここでは、sks manで片桐仁さんを指定しています。
%%bash
eval "$(conda shell.bash hook)"
conda activate ldm
python scripts/stable_txt2img.py --ddim_eta 0.0 \
--n_samples 8 \
--n_iter 1 \
--scale 10.0 \
--ddim_steps 100 \
--ckpt "ファインチューニング後のパラメータのパス" \
--prompt 'photo of a sks man'
conda deactivate
結果はこちら。

なかなか良い感じです。8枚生成したうちの4枚なので、人の顔としての自然さ自体は、大量に生成して厳選することで向上するものと思われます。または、以下の記事の方法で修正することも可能です。
続いて、"photo of a sks man on the beach"で生成してみます。

なぜ自画像抱えてるの…。
次は、"High quality concept art of a sks man, cinematic lighting, atmospheric, highly detailed, in the style of craig mullins"でイラスト化してみます。

少し離れましたが、特徴は捉えているように見えます。
最後は、"marble statue of a sks man"です。

こちらは特徴を残して生成できているものの、もう少し似せたいところ。
まとめ
自分の好きな対象を主役にして、好きなシチュエーションで画像を生成できる、名前のとおりまさに夢のような技術だと思います。GPUの制約がやや大きいですが、準備する画像の数は非常に少ないので、環境が整う方はぜひ試してみてください。

参考文献
GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model