



YOLOv7による物体検知とカスタムデータセットを用いた学習

この記事では、YOLOv7の事前学習済みモデルを用いて物体を検知する方法、そして、自前のカスタムデータセットを用いて、YOLOv7ベースのオリジナルの検知モデルを学習する方法を紹介します。
YOLOv7とは
2022年7月に発表された「You Only Look Once」の名を冠する最新のモデルです。
v7とついていますが、v6とは異なる開発チームによるプロダクトであり、YOLOの特徴である「速さ」と「正確さ」において既存の検出器を上回る結果となっています。
今回はこちらの公式リポジトリの実装をベースに、Google Colaboratoryでモデルの転移学習を試してみたいと思います。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
環境設定
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、推論・学習時にGPUを利用することができます。
次に、colab上にリポジトリをクローンし、必要なパッケージをインストールします。
!git clone https://github.com/WongKinYiu/yolov7 %cd yolov7 !pip install -r requirements.txt
環境設定に必要な作業はこれだけです。
モデル設定
続いて、学習済みのパラメータをダウンロードします。
YOLOv7には、モデルサイズによっていくつか種類がありますが、今回はYOLOv7-Xを使ってみます。
# モデルの指定 checkpoint = 'yolov7x.pt' # パラメータのダウンロード !wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/$checkpoint
推論
では、学習済みのパラメータをそのまま用いて推論を行ってみます。 ここでは以下の画像を入力とします。

from google.colab import files from PIL import Image # 画像のアップロード files.upload() # 入力パラメータの設定 img_file = 'アップロードした画像のファイル名' img_size = 640 conf_thres = .25 # 推論 !python detect.py --weights $checkpoint --conf $conf_thres --img-size $img_size --source $img_file # 描画 result = Image.open(f'/content/yolov7/runs/detect/exp/{img_file}') result
結果はこちらです。
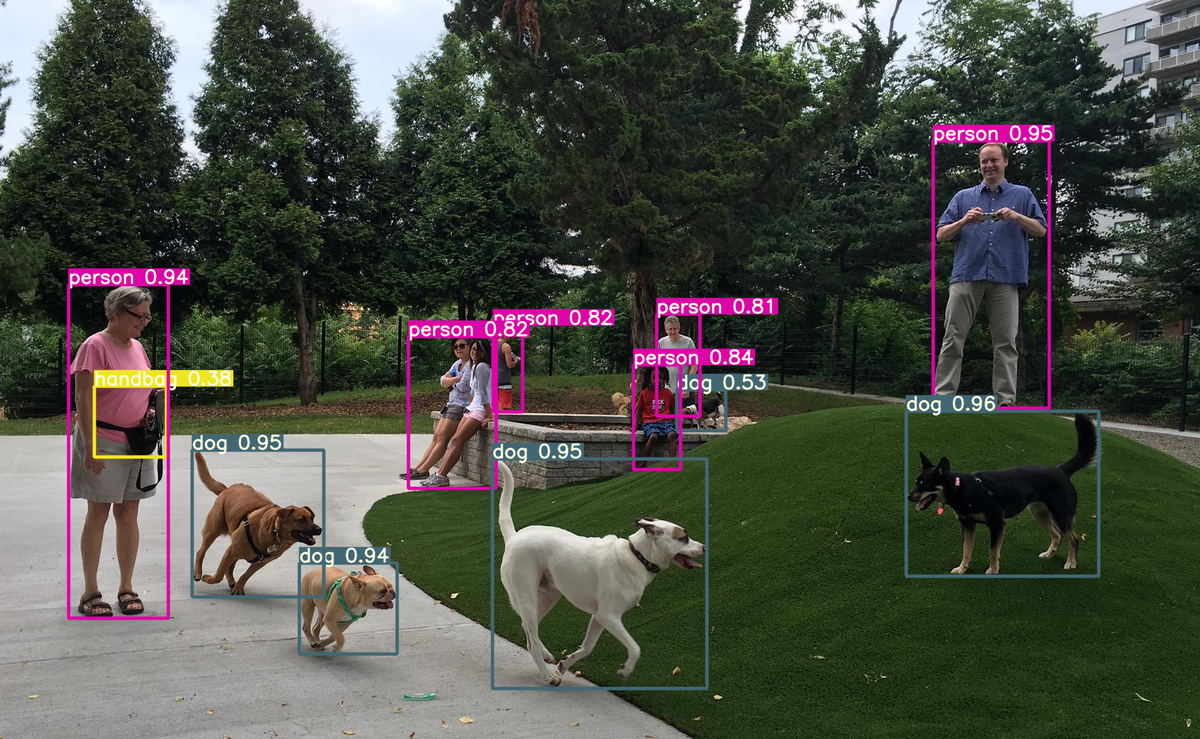
正確に検出することができています。
なお、学習済みモデルを試したいだけであれば、こちらのページでweb上で実行することも可能です。
カスタムデータセット準備
ここから、独自のデータセットを用いてモデルを転移学習します。
学習用のデータセットはYOLOフォーマットである必要があります。
画像ごとのラベル情報は、以下の方法でテキストファイルとして作成し、1枚の画像に複数のバウンディングボックスがある場合は、改行して1ファイルに複数行記入します。
# class_id center_x center_y bbox_width bbox_height 1 0.408 0.30266666666666664 0.104 0.15733333333333333
画像とラベルが準備できたら、学習用とバリデーション用に分割します。ディレクトリ構造は、trainとvalid(必要に応じてtest)、それぞれのimagesとlablesが分かれていればどのように配置しても問題ありません。
ここでは、以下の構造で配置します。
└─dataset
├─train
│ ├─images
│ │ 00001.jpg
│ │ ...
│ └─labels
│ 00001.txt
│ ...
└─valid
├─images
│ 00001.jpg
│ ...
└─labels
00001.txt
...
最後にラベル情報、ディレクトリ構造と平仄を合わせてconfigファイル(custom.yaml)を作成し、データセットの準備は完了です。
# train and val data directory train: ./dataset/train val: ./dataset/valid # number of classes nc: 2 # class names names: ['1つ目のクラス名', '2つ目のクラス名']
今回は、以下のマスク着用判定の公開データセットを利用してモデルを学習してみます。
学習
以下のコードで学習を実行します。
!python train.py --workers 2 \
--device 0 \
--batch-size 16 \
--data data/mask_wearing.yaml \
--img 640 640 \
--cfg cfg/training/yolov7x.yaml \
--weights 'yolov7x.pt' \
--name yolov7x-custom \
--epochs 300 \
--hyp data/hyp.scratch.p5.yaml
学習ログは以下のように出力されます。

テストデータに対する推論結果はこちらです。

わずか100数枚のデータによる学習ですが、非常に正確に検知できていることが分かります。
まとめ
YOLOのような物体検知モデルは、研究がさかんで最新の技術が盛り込まれている一方で、APIが整備されており、かつ使いどころが直感的に分かりやすいため、応用しやすいのが特徴です。
Google Colaboratoyの無料環境でも十分動かすことができるので、ぜひ試してみてください。

チーム・カルポ 秀和システム 2021年08月31日頃