



【言語処理100本ノック 2020】第4章: 形態素解析【Python】

自然言語処理の問題集として有名な言語処理100本ノックの2020年版の解答例です。 この記事では、以下の第1章から第10章のうち、「第4章: 形態素解析」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNNとCNN
- 第10章: 機械翻訳
環境設定
コードの実行はGoogle Colaboratoryで行います。 以降の解答の実行結果をすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
第4章: 形態素解析
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
まずは指定のデータをダウンロードします。 Google Colaboratoryのセル上で下記のコマンドを実行すると、現在のディレクトリに対象のファイルがダウンロードされます。
!wget https://nlp100.github.io/data/neko.txt
続いて、MeCabをインストールします。
!apt install mecab libmecab-dev mecab-ipadic-utf8
インストールが完了したら、早速形態素解析を行います。
以下のコマンドを実行することにより、neko.txtを形態素解析した結果が、neko.txt.mecabとして出力されます。
!mecab -o ./neko.txt.mecab ./neko.txt
出力結果を確認します。
# 行数の確認 !wc -l ./neko.txt.mecab
--- 出力 --- 226266 ./neko.txt.mecab
# 先頭15行の確認 !head -15 ./neko.txt.mecab
--- 出力 ---
一 名詞,数,*,*,*,*,一,イチ,イチ
記号,一般,*,*,*,*,*
EOS
記号,一般,*,*,*,*,*
EOS
記号,空白,*,*,*,*, , ,
吾輩 名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
猫 名詞,一般,*,*,*,*,猫,ネコ,ネコ
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
ある 助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル
。 記号,句点,*,*,*,*,。,。,。
記号,一般,*,*,*,*,*
EOS
名前 名詞,一般,*,*,*,*,名前,ナマエ,ナマエ
30. 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
filename = './neko.txt.mecab' sentences = [] morphs = [] with open(filename, mode='r') as f: for line in f: # 1行ずつ読込 if line != 'EOS\n': # 文末以外:形態素解析情報を辞書型に格納して形態素リストに追加 fields = line.split('\t') if len(fields) != 2 or fields[0] == '': # 文頭以外の空白と改行文字はスキップ continue else: attr = fields[1].split(',') morph = {'surface': fields[0], 'base': attr[6], 'pos': attr[0], 'pos1': attr[1]} morphs.append(morph) else: # 文末:形態素リストを文リストに追加 sentences.append(morphs) morphs = [] # 確認 for morph in sentences[2]: print(morph)
--- 出力 ---
{'surface': '\u3000', 'base': '\u3000', 'pos': '記号', 'pos1': '空白'}
{'surface': '吾輩', 'base': '吾輩', 'pos': '名詞', 'pos1': '代名詞'}
{'surface': 'は', 'base': 'は', 'pos': '助詞', 'pos1': '係助詞'}
{'surface': '猫', 'base': '猫', 'pos': '名詞', 'pos1': '一般'}
{'surface': 'で', 'base': 'だ', 'pos': '助動詞', 'pos1': '*'}
{'surface': 'ある', 'base': 'ある', 'pos': '助動詞', 'pos1': '*'}
{'surface': '。', 'base': '。', 'pos': '記号', 'pos1': '句点'}
31. 動詞
動詞の表層形をすべて抽出せよ.
以降、30で作成したsentencesに対して処理を行っていきます。
ここで結果を格納しているset型は、集合を表すデータ型であり重複を許しません。ですので、何も考えずに要素を追加していっても自然と重複のない結果を得られるため、本問のようなケースで便利です。
ans = set() for sentence in sentences: for morph in sentence: if morph['pos'] == '動詞': ans.add(morph['surface']) # set型なので重複しない要素のみ保持していく # 確認 print(f'動詞の表層形の種類: {len(ans)}\n') for v in list(ans)[:10]: print(v)
--- 出力 --- 動詞の表層形の種類: 3893 儲け 忍ん 並べる 気がつい 候え やい 隔て 保っ まつわっ から
32. 動詞の原形
動詞の基本形をすべて抽出せよ.
ans = set() for sentence in sentences: for morph in sentence: if morph['pos'] == '動詞': ans.add(morph['base']) # 確認 print(f'動詞の基本形の種類: {len(ans)}\n') for v in list(ans)[:10]: print(v)
--- 出力 --- 動詞の基本形の種類: 2300 並べる 待ち受ける 拗じる 打てる 応ずる 引き受ける 畳み込む 刺し通す 生える 言い付ける
33. 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
ans = set() for sentence in sentences: for i in range(1, len(sentence) - 1): if sentence[i - 1]['pos'] == '名詞' and sentence[i]['surface'] == 'の' and sentence[i + 1]['pos'] == '名詞': ans.add(sentence[i - 1]['surface'] + sentence[i]['surface'] + sentence[i + 1]['surface']) # 確認 print(f'「名詞+の+名詞」の種類: {len(ans)}\n') for n in list(ans)[:10]: print(n)
--- 出力 --- 「名詞+の+名詞」の種類: 4924 辟易の体 介の半面 自分の嫌い 警察の厄介 法のうち 事物の適 世人の探偵 護の恐れ 二つの要素 立てのフロック
34. 名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
文ごとに、最初の形態素から順に以下のルールを適用し、名詞の連接を最長一致で抽出しています。
- 名詞であれば
nounsに連結し、連結数(num)をカウント - 名詞以外の場合、ここまでの連結数が2以上であれば出力し、
nounsとnumを初期化 - それ以外の場合、
nounsとnumを初期化
ans = set() for sentence in sentences: nouns = '' num = 0 for morph in sentence: if morph['pos'] == '名詞': # 最初の形態素から順に、名詞であればnounsに連結し、連結数(num)をカウント nouns = ''.join([nouns, morph['surface']]) num += 1 elif num >= 2: # 名詞以外、かつここまでの連結数が2以上の場合は出力し、nounsとnumを初期化 ans.add(nouns) nouns = '' num = 0 else: # それ以外の場合、nounsとnumを初期化 nouns = '' num = 0 if num >= 2: ans.add(nouns) # 確認 print(f'連接名詞の種類: {len(ans)}\n') for n in list(ans)[:10]: print(n)
--- 出力 --- 連接名詞の種類: 4454 かん猪口 通り今日 必竟世間 二枚かけ 君シャンパン 近付 ばかよう 木槿垣 今十年 刺激以外
35. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
from collections import defaultdict ans = defaultdict(int) for sentence in sentences: for morph in sentence: if morph['pos'] != '記号': ans[morph['base']] += 1 # 単語数の更新(初登場の単語であれば1をセット) ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) # 確認 for w in ans[:10]: print(w)
--- 出力 ---
('の', 9194)
('て', 6848)
('は', 6420)
('に', 6243)
('を', 6071)
('だ', 5972)
('と', 5508)
('が', 5337)
('た', 4267)
('する', 3657)
36. 頻度上位10語
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
matplotlibで日本語を表示させるため、japanize_matplotlibをインストールしておきます。
!pip install japanize_matplotlib
そして、35と同様に出現頻度を集計し、棒グラフで視覚化します。
import matplotlib.pyplot as plt import japanize_matplotlib ans = defaultdict(int) for sentence in sentences: for morph in sentence: if morph['pos'] != '記号': ans[morph['base']] += 1 # 単語数の更新(初登場の単語であれば1をセット) ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) keys = [a[0] for a in ans[0:10]] values = [a[1] for a in ans[0:10]] plt.figure(figsize=(8, 4)) plt.bar(keys, values) plt.show()
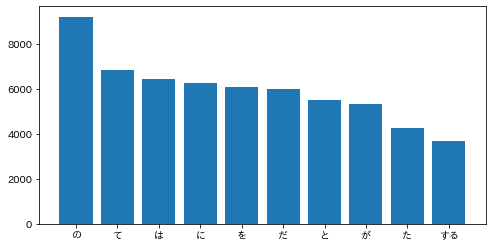
37. 「猫」と共起頻度の高い上位10語
「猫」とよく共起する(共起頻度が高い)10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
ここでは特に指示がないため品詞を選択していませんが、目的によっては助詞等を除くことによって、より意味のありそうな結果になると思います。
ans = defaultdict(int) for sentence in sentences: if '猫' in [morph['surface'] for morph in sentence]: # 文章の形態素に「猫」が含まれる場合のみ辞書に追加 for morph in sentence: if morph['pos'] != '記号': ans[morph['base']] += 1 # 単語数の更新(初登場の単語であれば1をセット) del ans['猫'] ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) keys = [a[0] for a in ans[0:10]] values = [a[1] for a in ans[0:10]] plt.figure(figsize=(8, 4)) plt.bar(keys, values) plt.show()
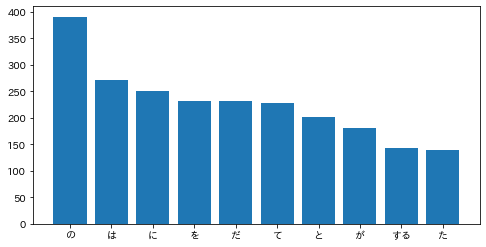
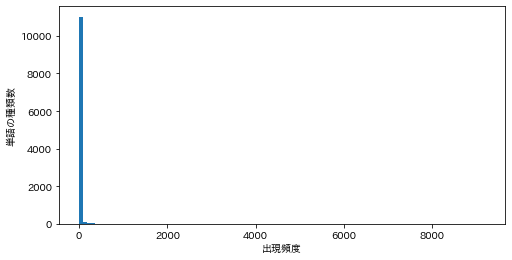
38. ヒストグラム
単語の出現頻度のヒストグラム(横軸に出現頻度,縦軸に出現頻度をとる単語の種類数を棒グラフで表したもの)を描け.
ans = defaultdict(int) for sentence in sentences: for morph in sentence: if morph['pos'] != '記号': ans[morph['base']] += 1 # 単語数の更新(初登場の単語であれば1をセット) ans = ans.values() plt.figure(figsize=(8, 4)) plt.hist(ans, bins=100) plt.xlabel('出現頻度') plt.ylabel('単語の種類数') plt.show()
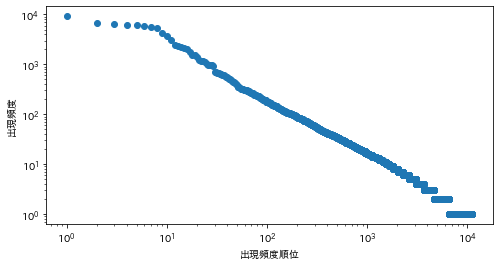
39. Zipfの法則
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
import math ans = defaultdict(int) for sentence in sentences: for morph in sentence: if morph['pos'] != '記号': ans[morph['base']] += 1 ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) ranks = [r + 1 for r in range(len(ans))] values = [a[1] for a in ans] plt.figure(figsize=(8, 4)) plt.scatter(ranks, values) plt.xscale('log') plt.yscale('log') plt.xlabel('出現頻度順位') plt.ylabel('出現頻度') plt.show()
理解を深めるためのオススメ教材


youwht 翔泳社 2021年12月06日頃
全100問の解答はこちら