



CLIP-Meshによるテキストから3Dモデルの自動生成(text-to-mesh)

この記事では、CLIP-Meshを用いて、テキストからテクスチャ付きの3Dモデルを生成する方法を紹介します。
CLIP-Meshとは

CLIP-MeshとはCLIPを用いて、入力したテキストから3Dモデルの生成に必要なパラメータを自動生成する手法です。
CLIPは、OpenAIによって開発された一種の事前学習方法であり、ネット上から取得した4億枚の画像とその画像を表すテキストのペアを入力として、画像とテキストの関連付けを学習します。
CLIPの特徴としては、以下の点が挙げられます。
大量の画像ペアを使っているため、zero-shot(初めてみるデータセット)でも上手く分類できるケースがある。
画像とテキストの両方の埋め込み(ベクトル化)が可能であることから、画像から類似画像の検索、テキストから類似テキストの検索ができることはもちろん、画像とテキストの一方から、もう一方を検索することもできる。
そして、CLIP-Meshはこれらの特徴を活かし、
入力されたテキストを埋め込み('apple' → 'apple'ベクトル)
テキストベクトルを画像ベクトルに変換('apple'ベクトル → 🍎ベクトル)
ランダムに生成した3Dモデルから生成した画像を画像ベクトルに変換
2と3のベクトルを比較
4の誤差が最小となるように3Dモデルを調整
といった流れで3Dモデルを生成していきます。
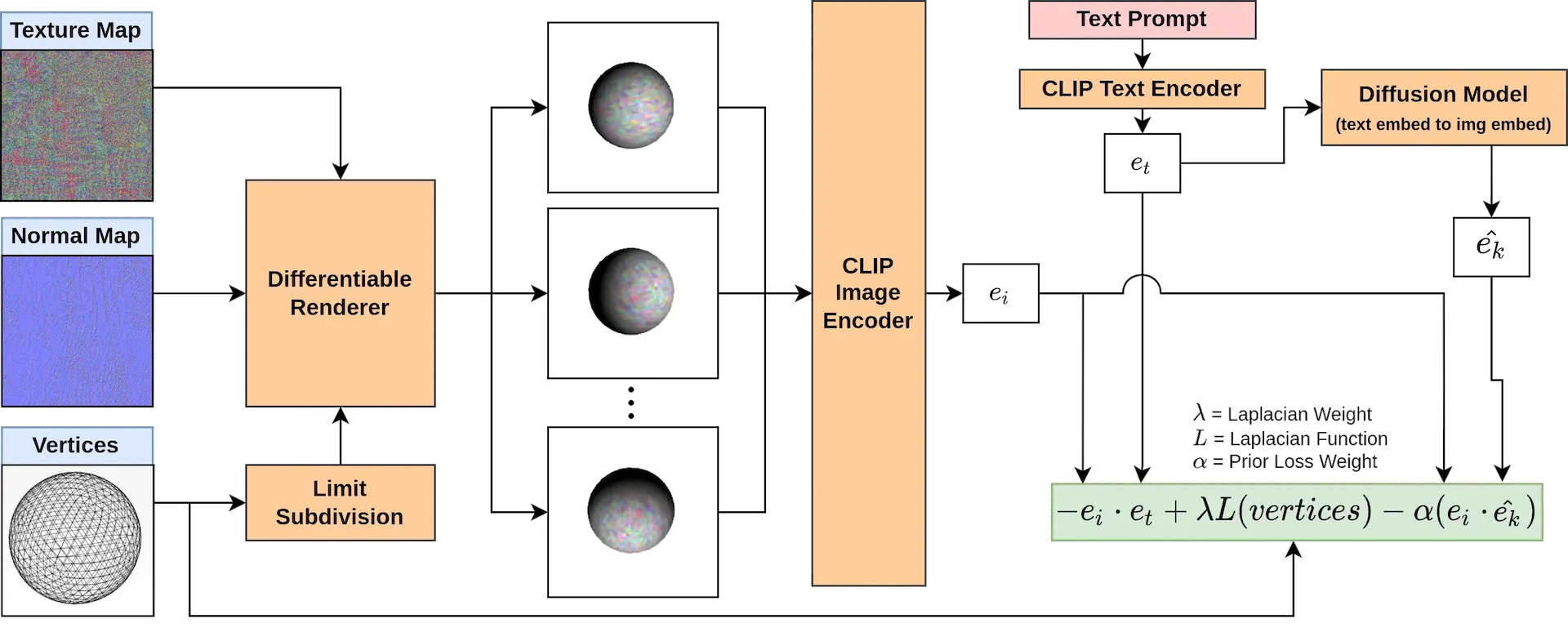
論文内でも強調されていますが、利用しているモデルは事前学習済みのCLIPのみで、3Dモデルを教師データとして用いたモデルを利用しているわけではない点が従来手法との大きな違いです。
CLIPを用いた別の3Dオブジェクト生成手法を以下の記事で紹介しています。
デモ
それでは、Google Colaboratoryを使って実際に3Dモデルを生成してみます。
以下の公式リポジトリで配布されているノートブックをベースに、プロンプトだけ入力すれば生成結果がダウンロードされるお試しバージョンを作成したので、こちらを使っていきます。
お試しバージョンノートブックは以下のリンクよりご参照ください。
![]()
プロンプトの設定
ここでは、「an apple」と入力します。
3Dモデルの生成
上部メニューの「ランタイム」から「すべてのセルを実行」します。
これで、環境設定から3Dモデルの生成、結果のダウンロードまで自動で行われます。
生成結果
こちらが、3Dモデル生成のパラメータが最適化されていく様子の動画です。
リンゴの色はお国柄があると思うので置いておくとして、それらしき形と質感は再現できているように見えます。
さらに、出力されたメッシュとテクスチャ(色、質感、光沢)の情報を3DCGソフトのBlenderで読み込み、ライトを当ててレンダリングした結果がこちらです。
「APPLE」と書こうとしたであろう葛藤の跡が涙ぐましいです。

まとめ
現在は、Stable Diffusionのようなモデルにより、ほとんど自由にテキストから画像を生成できるようになったと言っていいと思いますが、CLIP-Meshのような技術が成熟すれば、テキストから仮想現実そのものを生成するtext-to-VRが当たり前となる世界が実現するのでしょうか。
これからの動向に注目です。

チーム・カルポ 秀和システム 2021年08月31日頃