



AIで生成した顔画像の微妙な不自然さを後から簡単に修正する方法

この記事では、Stable Diffusionのような画像生成AIによって生成した顔画像が部分的に不自然であったときに、後から簡単に修正し、自然な顔に見せる方法を紹介します。
概要
画像生成AIでポートレートを生成した際、プロンプトのイメージどおりですごく良いんだけど、顔の一部分だけが不自然になってしまって残念没…ということはままあると思います。
他の記事でも紹介されていますが、そのようなときは残念画像を高画質化AIにかけると劇的に改善することが多いです。
デモ
実際に、どの程度改善するか確認してみましょう。
まずは、以下の記事に従って女性のポートレートを生成してみます。
プロンプトはこちらの記事を参考にさせていただき、"Photographic portrait of beautiful women, glowing skin, Sony α7, 35mm Lens, f1.8, film grain, golden hour, soft lighting, by Daniel F Gerhartz"としました。
まずは、うまくいった結果から。

美しいですね。素晴らしいプロンプトだと思います。
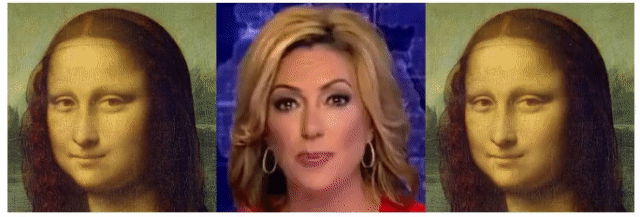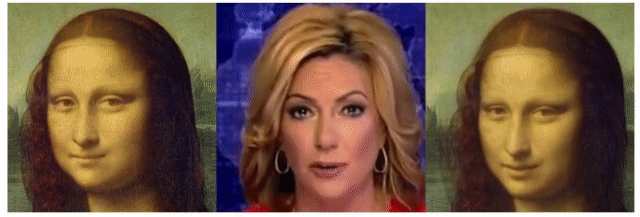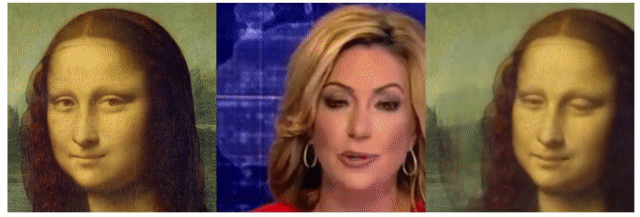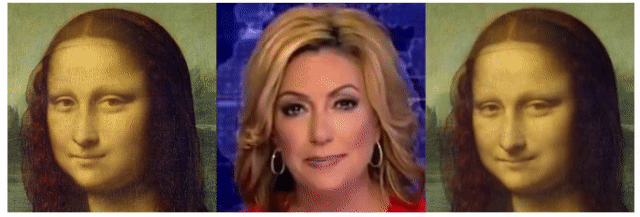
次に、微妙な残念画像がこちら。

雰囲気はとても良いのですが、いずれも顔がやや不自然です。
この画像をCodeFormerという高画質化AIで処理してみます。CodeFormerの概要や実行方法については、以下の記事をご覧ください。
結果はこちら。左が処理前、右が処理後です。

目の付近を中心に、不自然さが解消されていることが分かります。これは、元画像中の不自然な部分が、高画質化AIによって「不鮮明」だと判断され、人の顔として自然になるように情報が復元されたことによります。
ちなみに、これでも修正しきれない場合、CodeFormerのパラメータである元画像への忠実度(CODEFORMER_FIDELITY)を下げると不自然さが解消されることが多いですが、この方法では大きく雰囲気が変わってしまします。
その場合は、画像サイズを小さくし、復元領域を増やしてから高画質化することで、元画像の雰囲気をキープしたまま、自然な仕上がりにできることがあります。併せて試してみてください。

参考文献
High-Resolution Image Synthesis with Latent Diffusion Models
【公開】Stable Diffusionで美しい女性のポートレートを描くprompt(呪文)を公開するチュートリアル🚀【入門編】
CodeFormerによる顔画像のハイクオリティな高画質化

この記事では、CodeFomerを用いて、低画質の顔画像をハイクオリティに高画質化する方法を紹介します。
CodeFormerとは

CodeFormerは、低画質の画像から高画質の画像を復元するためのネットワークで、情報の多くが欠落している低画質画像から情報を復元するために、2段階の学習を行います。
1段階目は、高画質の画像を入力とし、あえて情報を落とした上で、その情報を復元するself-reconstructionを学習します。エンコーダーでベクトル化した各セルの情報を(四捨五入のようなイメージで)離散化して情報量を落とし、デコーダーで元の画像を復元します。ここで学習した離散化ルールとデコーダーは、2段階目に引き継がれます。
2段階目は、低画質画像から高画質画像の復元を学習します。低画質画像をエンコーダーでベクトル化した後、1段階目で学習した離散化ルールに対応づけるために、Transformerが用いられます。離散化されたあとは、1段階目で学習したデコーダーで情報が復元され、高画質化されます。
ちなみに、このようにベクトル化した画像の離散化(ベクトル量子化)に用いられるルールをコードブック(Codebook)と呼び、そのマッピングにTransformerを用いていることが、CodeFormerの名前の由来となっています。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
環境設定
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、推論時にGPUを利用することができます。
続いて、公式リポジトリのクローンとライブラリのインストールを行います。
# リポジトリのクローン !git clone https://github.com/sczhou/CodeFormer.git %cd CodeFormer # ライブラリのインストール !pip install -r requirements.txt !python basicsr/setup.py develop
モデル設定
学習済みパラメータが公開されているので、ダウンロードします。
!python scripts/download_pretrained_models.py facelib !python scripts/download_pretrained_models.py CodeFormer
推論
colab上に推論対象のファイルをアップロードします。
続いて、元画像への忠実度CODEFORMER_FIDELITY(高いほど忠実だが低クオリティ)、背景も高画質化するかどうかBACKGROUND_ENHANCEを選択し、アップロードした画像をtest_pathに指定して推論を実行します。
CODEFORMER_FIDELITY = 0.7 BACKGROUND_ENHANCE = True if BACKGROUND_ENHANCE: !python inference_codeformer.py -w $CODEFORMER_FIDELITY -i inputs/user_upload --bg_upsampler realesrgan else: !python inference_codeformer.py -w $CODEFORMER_FIDELITY -i inputs/user_upload
リポジトリ内に用意されているサンプル画像に対する結果がこちらです。

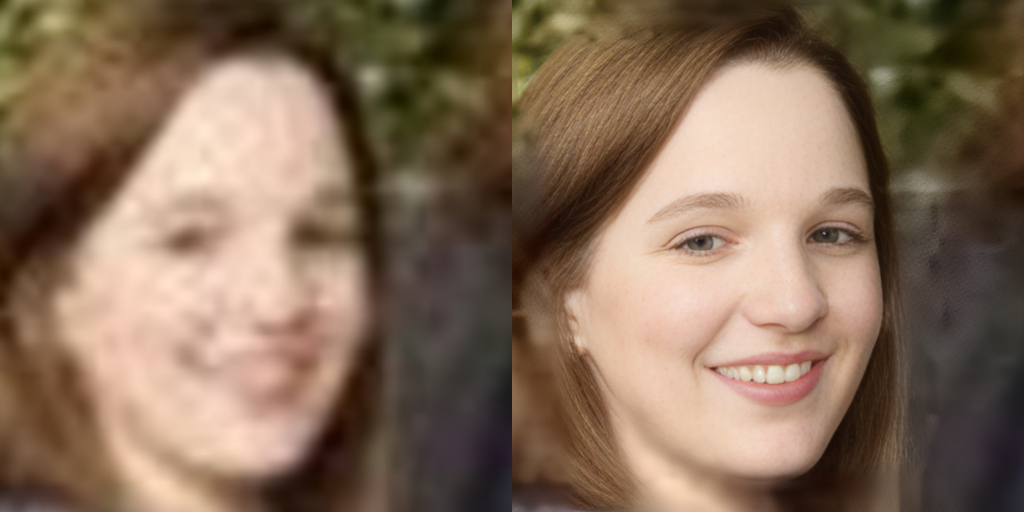



オリジナルの画像でも試してみます。引用元はこちらです。


学習データに引っ張られてやや欧米よりの顔立ちに復元されているものの、(美男美女に限る可能性はありますが)不自然さはほぼなく、かなり高品質に復元できているように見えます。
なお、高画質化以外にも、色の復元や欠損の補完にも利用できるようです。

以下の記事では、CodeFormerを利用して、画像生成AIによる生成画像の不自然さを解消する方法を紹介しています。併せてご覧ください。
まとめ
私用でも商用でもいくらでも応用が考えられる技術です。これ以外の手法にも当てはまりますが、品質を保ちつつ自分や近しい人の画像でいかに違和感を感じさせないように復元できるかがこれからの焦点でしょうか。

チーム・カルポ 秀和システム 2021年08月31日頃
参考文献
YOLOPv2による走行車線・白線・他車の同時検知

 GitHub - CAIC-AD/YOLOPv2: YOLOPv2: Better, Faster, Stronger for Panoptic driving Perception
GitHub - CAIC-AD/YOLOPv2: YOLOPv2: Better, Faster, Stronger for Panoptic driving Perception
この記事では、YOLOPv2を用いて、ドライブレコーダーの映像から、走行(可能)車線、白線、そして他車を同時に検知する方法を紹介します。
YOLOPv2とは

YOLOPv2は、自動運転での応用を見据え、ドライブレコーダーの映像を入力として、1つのネットワークで、走行車線、白線のセグメンテーション、そして他車の検知を同時に行うモデルです。
ネットワークは、入力画像から特徴量を抽出するタスク共通のエンコーダー(Backbone)と、タスクに応じた3つのデコーダー(Drivable area segment head, Lane segment head, Detect head)から構成されます。
3者を同時に推定するネットワーク構成の根本は、YOLOPやHybridNetsといった先行研究と変わらないものの、エンコーダーをE-ELANに変更し、(先行研究では走行車線と白線は共通であった)デコーダーを3タスク分それぞれ準備することで、精度の向上と高速化を実現しています。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
環境設定
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、推論時にGPUを利用することができます。
続いて、公式リポジトリのクローンとライブラリのインストールを行います。
# リポジトリのクローン !git clone https://github.com/CAIC-AD/YOLOPv2.git %cd YOLOPv2 # ライブラリのインストール !pip install -r requirements.txt
モデル設定
学習済みパラメータが公開されているので、ダウンロードします。
!wget -P data/weights https://github.com/CAIC-AD/YOLOPv2/releases/download/V0.0.1/yolopv2.pt
推論
colab上に推論対象のファイルをアップロードします。ファイルは静止画、動画のいずれでも大丈夫です。
demo.pyによって推論が実行され、YOLOPv2/runs/detect/expに入力ファイルと同じ名前で結果が保存されます。
# 対象ファイルの指定 source = 'アップロードしたファイルのパス' # 推論 !python demo.py --source $source
YouTube、PIXTAから取得したドライブレコーダーの映像に対して推論を実行した結果がこちらです。左がオリジナル、右が推論結果です。
夜間の結果がこちら。
colabも面倒だよ、という方は、以下のリンクからブラウザ上で簡単に試すこともできます。
まとめ
手元の動画に対しても、昼夜問わず精度良く検知できていることが確認できました。
自動運転の根幹をなす非常に重要な技術でありながら、比較的シンプルな作りなので、ぜひコードを追いながら試してみてください。
参考文献
GitHub - CAIC-AD/YOLOPv2: YOLOPv2: Better, Faster, Stronger for Panoptic driving Perception
Dream Fieldsによるテキストから3Dオブジェクトの自動生成(text-to-3D synthesis)

この記事では、Dream Fieldsを用いて、テキストから3Dオブジェクトを生成する方法を紹介します。
Dream Fieldsとは
背景
3Dオブジェクトモデルは、ゲームやVRなどあらゆるシーンで必要とされるため、大量かつ多様なニーズがありますが、現在はアーティストの高コストな職人技に頼らざるをえない状況です。
一方、3Dオブジェクトを自動で生成する方法の一つとして、Neural Radiance Field(NeRF)があります。NeRFは対象の写った画像を入力として学習し、新たな視点からの画像を自由に生成することのできる技術ですが、一定数の入力画像を準備する必要があるため、大量の3Dオブジェクト生成には向きません。
そこで、NeRFの構造をベースとして、入力画像を使わず、テキストから自由に3Dオブジェクトを生成できないかという考えから提案されたのが、Dream Fieldsです。
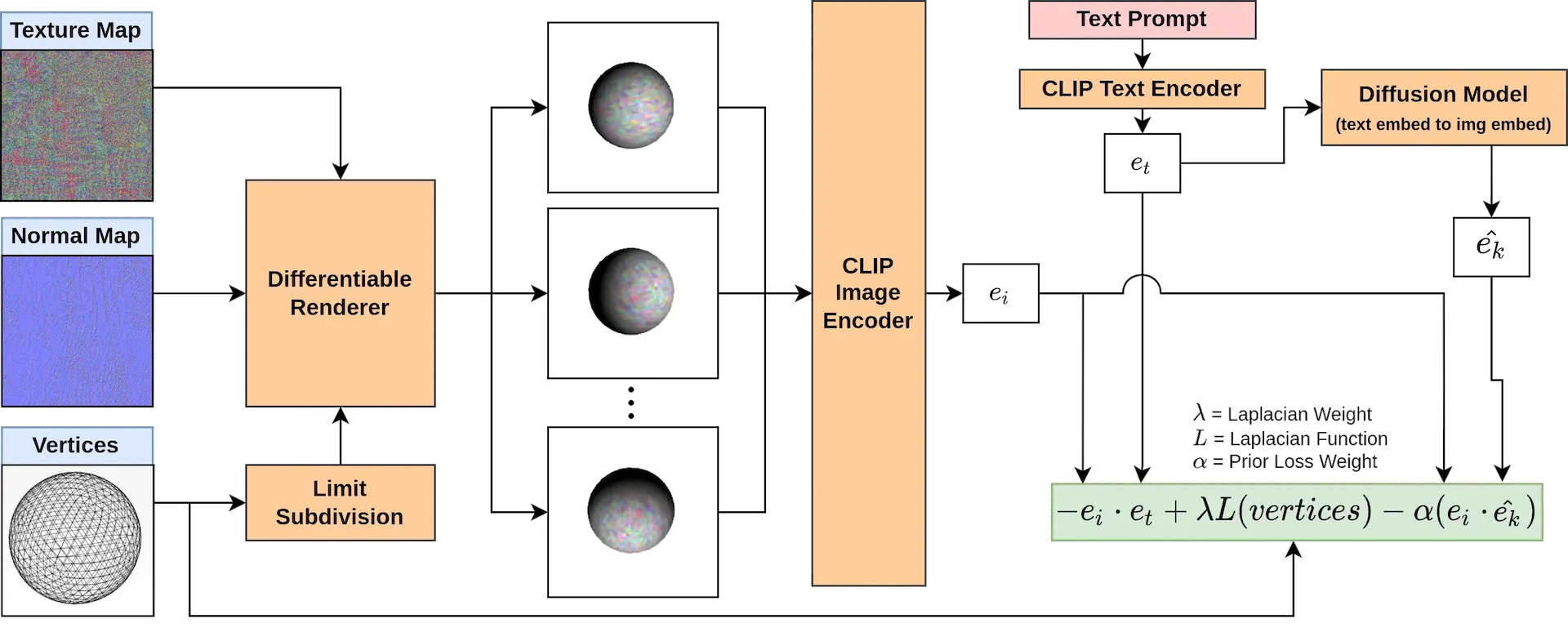
概要

通常のNeRFでは、生成した3Dオブジェクトをある視点から2D化(レンダリング)した結果と、入力画像を比較して、損失関数を計算します。Dream Fieldsは、入力したテキストから3Dオブジェクトを生成することを目的とするため、入力画像の代わりにCLIPにより画像と比較可能な形式でベクトル化したテキストと、同様にベクトル化されたNeRFのレンダリング結果を比較して、損失関数を計算します。また、視点ごとのオブジェクトの(透過率としての)シルエットも併せて最適化することで、視点間の形状の一貫性が補強され、3Dオブジェクトとしてより自然な出来上がりとなります。
CLIPについての詳細や、CLIPを用いた別の3Dモデル生成手法については、以下の記事をご覧ください。
デモ
それでは、Google Colaboratoryを使って実際に3Dオブジェクトを生成してみます。
以下のリンク先で配布されているノートブックをベースに、プロンプト(入力テキスト)だけ設定すれば生成結果がダウンロードされるお試しバージョンを作成したので、こちらを使っていきます。
お試しバージョンノートブックは以下のリンクよりご参照ください。
![]()
プロンプトの設定
ここでは、「a beautiful illustration of castle in style of Ghibli studio, trending on artstation, 8k HD, cgsociety」と入力します。
3Dオブジェクトの生成
上部メニューの「ランタイム」から「すべてのセルを実行」します。
これで、環境設定から3Dオブジェクトの生成、結果のダウンロードまで自動で行われます。
生成結果
生成された任意視点の画像を動画化した結果がこちらです。

雰囲気のある城が生成できました。「Ghibli studio」ワードの影響かトトロ風の何かも配置されています。
まとめ
CLIP-Meshと比較すると、色の塗り分けや形状の非対称性の再現が精細な印象です。 もっとも、それぞれ全く異なるアプローチであり、取得できる要素の違いなどから一長一短あるので、今後どのように発展していくのか要注目です。
参考文献
Thin Plate Spline Motion Modelによる好きな動画から好きな画像へのモーショントレース

この記事では、Thin Plate Spline Motion Modelによって、任意の動画のモーションを任意の静止画にトレースする方法を紹介します。
Thin Plate Spline Motion Modelとは

モデルの構成は下図のとおりです。

まず、トレース元動画(Driving)とトレース先画像(Source)を入力として、BG Motion PredictorがSourceからDrivingへの背景の動きを表すアフィン変換を予測します。同時に、Keypoint DetectorがKセットのキーポイントを推定します。
次に、Dense Motion Networkが、上記の予測結果を入力として、 Optical Flow(オプティカルフロー)とMuti-resolution Occlusion Masks(複数解像度のオクルージョンマスク)を推定します。
最後に、Sourceを入力して、エンコーダで抽出した特徴マップを推定したオプティカルフローでワープし、対応する解像度のオクルージョンマスクでマスクします。
つまり、背景の変化と人の変化をそれぞれ推定し、それらの組み合わせからSource全体をどのように変形すればDrivingに近づくか、という推定と、人の動き部分のマスクの推定を行います。そして、それらの情報によってSourceを変換して動画化することで、モーションのトレースを実現しています。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
環境設定
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、推論時にGPUを利用することができます。
次に、公式リポジトリのクローンと、必要なライブラリのインストール・インポートを行います。
# リポジトリのクローン !git clone https://github.com/yoyo-nb/Thin-Plate-Spline-Motion-Model.git %cd Thin-Plate-Spline-Motion-Model # ライブラリのインストール・インポート !pip install imageio-ffmpeg !pip install --upgrade gdown import imageio import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation from skimage.transform import resize from IPython.display import HTML import warnings import torch import os import gdown from demo import load_checkpoints from demo import make_animation from skimage import img_as_ubyte warnings.filterwarnings('ignore')
学習済みのパラメータもダウンロードしておきます。
!mkdir -p checkpoints !wget -c https://cloud.tsinghua.edu.cn/f/da8d61d012014b12a9e4/?dl=1 -O checkpoints/vox.pth.tar
サンプルの画像と動画はGoogle Driveからダウンロードできます(こちらからお借りしたものを含みます)。
url = 'https://drive.google.com/drive/folders/1XRPg76eXhP_gQIhaGXsS6_c4o4DvDe4_' gdown.download_folder(url, quiet=True, use_cookies=False)
モデル設定
先ほどダウンロードした画像と動画は./assets配下に保存されています。好きな組み合わせを選んで指定します。
device = torch.device('cuda:0') dataset_name = 'vox' # ['vox', 'taichi', 'ted', 'mgif'] source_image_path = './assets/01.jpg' # Source画像のパスを指定 driving_video_path = './assets/04.mp4' # Driving動画のパスを指定 output_video_path = './generated_01_04.mp4' # 生成動画の保存パスを指定 config_path = 'config/vox-256.yaml' checkpoint_path = 'checkpoints/vox.pth.tar' predict_mode = 'relative' # ['standard', 'relative', 'avd'] find_best_frame = False # when use the relative mode to animate a face, use 'find_best_frame=True' can get better quality result pixel = 256 # for vox, taichi and mgif, the resolution is 256*256 if(dataset_name == 'ted'): # for ted, the resolution is 384*384 pixel = 384 if find_best_frame: !pip install face_alignment
オリジナルのものを利用する場合は、正方形にクロップしたものをcolab上にアップロードし、上記の方法によりファイルを指定してください。
推論
モーションのトレースを行います。
# 画像・動画の読込 source_image = imageio.imread(source_image_path) reader = imageio.get_reader(driving_video_path) source_image = resize(source_image, (pixel, pixel))[..., :3] fps = reader.get_meta_data()['fps'] driving_video = [] try: for im in reader: driving_video.append(im) except RuntimeError: pass reader.close() driving_video = [resize(frame, (pixel, pixel))[..., :3] for frame in driving_video] # 学習済みパラメータのロード inpainting, kp_detector, dense_motion_network, avd_network = load_checkpoints(config_path = config_path, checkpoint_path = checkpoint_path, device = device) # トレースの実行 if predict_mode=='relative' and find_best_frame: from demo import find_best_frame as _find i = _find(source_image, driving_video, device.type=='cpu') print ("Best frame: " + str(i)) driving_forward = driving_video[i:] driving_backward = driving_video[:(i+1)][::-1] predictions_forward = make_animation(source_image, driving_forward, inpainting, kp_detector, dense_motion_network, avd_network, device = device, mode = predict_mode) predictions_backward = make_animation(source_image, driving_backward, inpainting, kp_detector, dense_motion_network, avd_network, device = device, mode = predict_mode) predictions = predictions_backward[::-1] + predictions_forward[1:] else: predictions = make_animation(source_image, driving_video, inpainting, kp_detector, dense_motion_network, avd_network, device = device, mode = predict_mode) # 結果の保存 imageio.mimsave(output_video_path, [img_as_ubyte(frame) for frame in predictions], fps=fps) # 描画 def display(source, driving, generated=None): fig = plt.figure(figsize=(8 + 4 * (generated is not None), 6)) ims = [] for i in range(len(driving)): cols = [source] cols.append(driving[i]) if generated is not None: cols.append(generated[i]) im = plt.imshow(np.concatenate(cols, axis=1), animated=True) plt.axis('off') ims.append([im]) ani = animation.ArtistAnimation(fig, ims, interval=50, repeat_delay=1000) plt.close() return ani HTML(display(source_image, driving_video, predictions).to_html5_video())
サンプルからいくつかの組み合わせを試してみた結果はこちらです(ブログ用に画質を落としています)。 左がトレース先画像(Source)、中央がトレース元動画(Driving)で、右がトレース結果です。



colabも面倒だよ、という方は、以下のリンクからブラウザ上で簡単に試すこともできます。
まとめ
非常に簡単かつ高速に、クオリティの高いトレースが実現できました。 イラストやCGへのモーション付加など、どのように応用されていくのか楽しみな技術です。
参考文献
Stable Diffusionを手塚治虫のキャラクターでファインチューニングしてみる(Textual Inversion)

この記事では、Textual Inversionによって、数枚のオリジナル画像でStable Diffusionをファインチューニングし、新たに好きなキャラクターや画風を学習させる方法を紹介します。
Stable Diffusionを用いたtext-to-image、image-to-image、image inpaintingの方法は以下の記事をご覧ください。
Textual Inversionとは
 An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Textual Inversionは、好きなコンセプトを表す3~5枚の画像を用いて、新たにそのコンセプトをモデルに学習させる手法です。
それらの画像によってStable Diffusionのようなtext-to-imageモデルの単語埋め込み層をファインチューニングし、画像の画風やモチーフを新しいワードに圧縮します。そして、そのワードを使って画像生成のための指示を与えれば、圧縮された情報を再現することができるようになります。
以下の例では、左端の画像の画風が「S*」という単語に圧縮されており、「S*風の○○」といった指示を与えるだけで似た画風の画像が生成されています。

デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
事前準備
まず、モデルが公開されているHugging Faceのアカウントを作成します。
Hugging Faceのトップページから右上の「Sign Up」に進みます。アドレスとパスワードを入力すると、登録したアドレスに認証メールが届くので、メール内のリンクをクリックして作成は完了です。
次に、Stable Diffusionのリポジトリを開き「Access repository」をクリックします。
最後に、学習済みモデルをダウンロードするためのアクセストークンを取得します。
トップページから先ほど作成したアカウントでログイン後、右上のアカウントのアイコンをクリックし、「Settings」、「Access Tokens」と進みます。画面中央の「New Token」をクリックしてアクセストークンを発行し、コピーしておきます。
これで事前準備は完了です。
環境設定
ここからは、Google Colaboratory上で作業を行います。
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、推論時にGPUを利用することができます。
続いて、必要となるライブラリのインストール、インポートを行います。
# ライブラリのインストール !pip install -qq diffusers['training']==0.3.0 transformers accelerate ftfy # ライブラリのインポート import os import re import glob from matplotlib import pyplot as plt from PIL import Image import torch from diffusers import StableDiffusionPipeline from torch import autocast
先ほど取得したアクセストークンを用いて、Hugging Faceにログインします。 以下の内容を記載したセルを実行後、表示される指示にしたがってアクセストークンを入力してください。
from huggingface_hub import notebook_login notebook_login()
次に、HuggingFace Accelerateを初期化します。セル実行後、表示される質問に対して、colabの環境に対応するように「0, 0, NO, NO, NO」と順に入力します。
!accelerate config
最後に、diffusersリポジトリをクローンして環境設定は完了です。
!git clone https://github.com/huggingface/diffusers.git %cd diffusers
ファインチューニング
新しいコンセプトの画像をcolab上にアップロードします。
アップロードの方法は下記の記事をご覧ください。
今回は、こちらからお借りした、手塚治虫先生のキャラクター画像5枚を利用します(※ 利用規約を遵守しています。再配布時にはご留意ください)。

続いて、学習用の設定を行います。
まず、画像に含まれる「対象」を学習させるのか、「画風」を学習させるのか選択します。今回は「画風」を学習させたいので「style」を選択します。
what_to_teach = 'style' # 'object' or 'style'
次に、学習させるコンセプトを表すカテゴリや、要約した単語を指定します。この値は学習の初期値として利用されます。ここでは、漫画絵というカテゴリを意識して「comic」と指定します。
initializer_token = 'comic'
以下のコードで学習を実行します。これにより、「new_concept」というワードに画像群の画風が圧縮されます。
!accelerate launch examples/textual_inversion/textual_inversion.py \ --pretrained_model_name_or_path="CompVis/stable-diffusion-v1-4" \ --use_auth_token \ --train_data_dir="画像を保存したディレクトリ" \ --learnable_property=$what_to_teach \ --placeholder_token="<new_concept>" \ --initializer_token=$initializer_token \ --resolution=512 \ --train_batch_size=1 \ --gradient_accumulation_steps=4 \ --max_train_steps=3000 \ --learning_rate=5.0e-04 \ --scale_lr \ --lr_scheduler="constant" \ --lr_warmup_steps=0 \ --output_dir="result"
学習結果は、カレントディレクトリのresultに保存されます。
推論
学習したコンセプトを用いて画像を生成してみます。
# StableDiffusionパイプラインの準備 pipe = StableDiffusionPipeline.from_pretrained('./result', torch_dtype=torch.float16).to('cuda') # プロンプトの設定 prompt = 'a man of <new_concept> style' # 画像の生成 with autocast('cuda'): image = pipe(prompt)['images'][0] image.save('test.png')
9枚生成した結果がこちらです。

まとめ
Textual Inversionは、text-to-imageモデルを自由にパーソナライズできる非常に強力な手法ですが、上記のとおりとても簡単に試すことができます。
ぜひ、手元の好きな画像を使って遊んでみてください。
参考文献
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
CLIP-Meshによるテキストから3Dモデルの自動生成(text-to-mesh)

この記事では、CLIP-Meshを用いて、テキストからテクスチャ付きの3Dモデルを生成する方法を紹介します。
CLIP-Meshとは

CLIP-MeshとはCLIPを用いて、入力したテキストから3Dモデルの生成に必要なパラメータを自動生成する手法です。
CLIPは、OpenAIによって開発された一種の事前学習方法であり、ネット上から取得した4億枚の画像とその画像を表すテキストのペアを入力として、画像とテキストの関連付けを学習します。
CLIPの特徴としては、以下の点が挙げられます。
大量の画像ペアを使っているため、zero-shot(初めてみるデータセット)でも上手く分類できるケースがある。
画像とテキストの両方の埋め込み(ベクトル化)が可能であることから、画像から類似画像の検索、テキストから類似テキストの検索ができることはもちろん、画像とテキストの一方から、もう一方を検索することもできる。
そして、CLIP-Meshはこれらの特徴を活かし、
入力されたテキストを埋め込み('apple' → 'apple'ベクトル)
テキストベクトルを画像ベクトルに変換('apple'ベクトル → 🍎ベクトル)
ランダムに生成した3Dモデルから生成した画像を画像ベクトルに変換
2と3のベクトルを比較
4の誤差が最小となるように3Dモデルを調整
といった流れで3Dモデルを生成していきます。
論文内でも強調されていますが、利用しているモデルは事前学習済みのCLIPのみで、3Dモデルを教師データとして用いたモデルを利用しているわけではない点が従来手法との大きな違いです。
CLIPを用いた別の3Dオブジェクト生成手法を以下の記事で紹介しています。
デモ
それでは、Google Colaboratoryを使って実際に3Dモデルを生成してみます。
以下の公式リポジトリで配布されているノートブックをベースに、プロンプトだけ入力すれば生成結果がダウンロードされるお試しバージョンを作成したので、こちらを使っていきます。
お試しバージョンノートブックは以下のリンクよりご参照ください。
![]()
プロンプトの設定
ここでは、「an apple」と入力します。
3Dモデルの生成
上部メニューの「ランタイム」から「すべてのセルを実行」します。
これで、環境設定から3Dモデルの生成、結果のダウンロードまで自動で行われます。
生成結果
こちらが、3Dモデル生成のパラメータが最適化されていく様子の動画です。
リンゴの色はお国柄があると思うので置いておくとして、それらしき形と質感は再現できているように見えます。
さらに、出力されたメッシュとテクスチャ(色、質感、光沢)の情報を3DCGソフトのBlenderで読み込み、ライトを当ててレンダリングした結果がこちらです。
「APPLE」と書こうとしたであろう葛藤の跡が涙ぐましいです。

まとめ
現在は、Stable Diffusionのようなモデルにより、ほとんど自由にテキストから画像を生成できるようになったと言っていいと思いますが、CLIP-Meshのような技術が成熟すれば、テキストから仮想現実そのものを生成するtext-to-VRが当たり前となる世界が実現するのでしょうか。
これからの動向に注目です。
チーム・カルポ 秀和システム 2021年08月31日頃
参考文献
YOLOv7による物体検知とカスタムデータセットを用いた学習

この記事では、YOLOv7の事前学習済みモデルを用いて物体を検知する方法、そして、自前のカスタムデータセットを用いて、YOLOv7ベースのオリジナルの検知モデルを学習する方法を紹介します。
YOLOv7とは
2022年7月に発表された「You Only Look Once」の名を冠する最新のモデルです。
v7とついていますが、v6とは異なる開発チームによるプロダクトであり、YOLOの特徴である「速さ」と「正確さ」において既存の検出器を上回る結果となっています。
今回はこちらの公式リポジトリの実装をベースに、Google Colaboratoryでモデルの転移学習を試してみたいと思います。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
環境設定
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、推論・学習時にGPUを利用することができます。
次に、colab上にリポジトリをクローンし、必要なパッケージをインストールします。
!git clone https://github.com/WongKinYiu/yolov7 %cd yolov7 !pip install -r requirements.txt
環境設定に必要な作業はこれだけです。
モデル設定
続いて、学習済みのパラメータをダウンロードします。
YOLOv7には、モデルサイズによっていくつか種類がありますが、今回はYOLOv7-Xを使ってみます。
# モデルの指定 checkpoint = 'yolov7x.pt' # パラメータのダウンロード !wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/$checkpoint
推論
では、学習済みのパラメータをそのまま用いて推論を行ってみます。 ここでは以下の画像を入力とします。

from google.colab import files from PIL import Image # 画像のアップロード files.upload() # 入力パラメータの設定 img_file = 'アップロードした画像のファイル名' img_size = 640 conf_thres = .25 # 推論 !python detect.py --weights $checkpoint --conf $conf_thres --img-size $img_size --source $img_file # 描画 result = Image.open(f'/content/yolov7/runs/detect/exp/{img_file}') result
結果はこちらです。
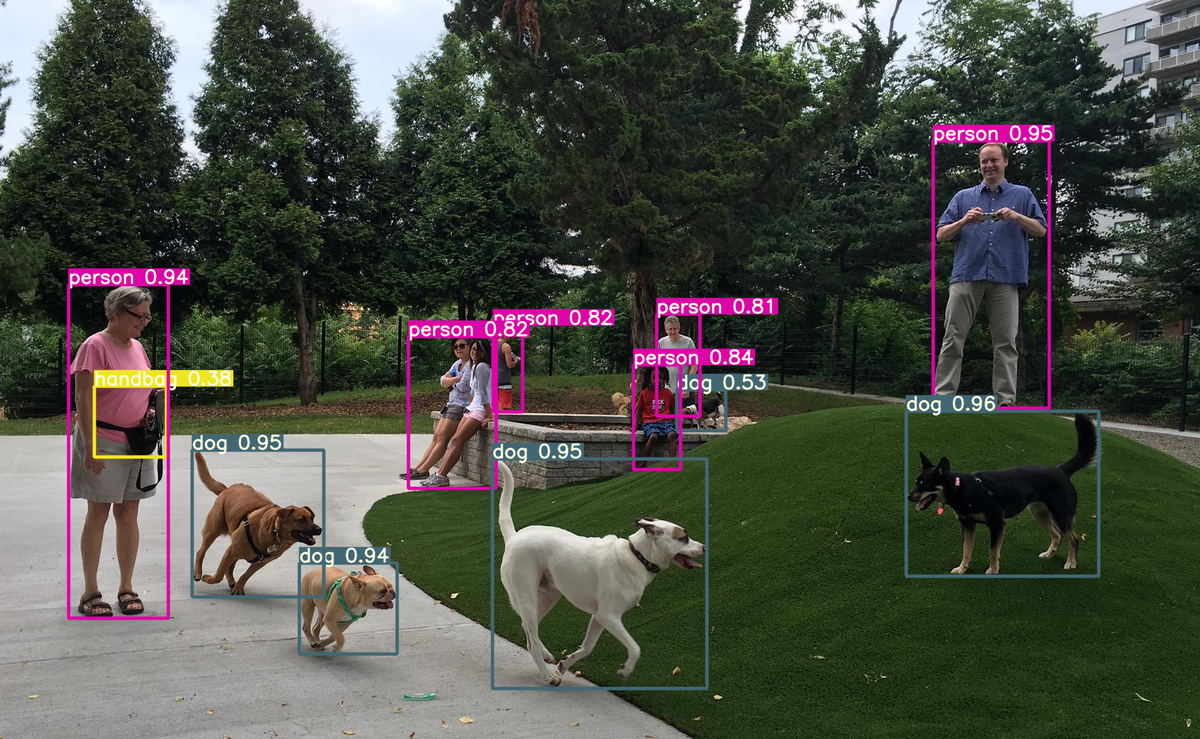
正確に検出することができています。
なお、学習済みモデルを試したいだけであれば、こちらのページでweb上で実行することも可能です。
カスタムデータセット準備
ここから、独自のデータセットを用いてモデルを転移学習します。
学習用のデータセットはYOLOフォーマットである必要があります。
画像ごとのラベル情報は、以下の方法でテキストファイルとして作成し、1枚の画像に複数のバウンディングボックスがある場合は、改行して1ファイルに複数行記入します。
# class_id center_x center_y bbox_width bbox_height 1 0.408 0.30266666666666664 0.104 0.15733333333333333
画像とラベルが準備できたら、学習用とバリデーション用に分割します。ディレクトリ構造は、trainとvalid(必要に応じてtest)、それぞれのimagesとlablesが分かれていればどのように配置しても問題ありません。
ここでは、以下の構造で配置します。
└─dataset
├─train
│ ├─images
│ │ 00001.jpg
│ │ ...
│ └─labels
│ 00001.txt
│ ...
└─valid
├─images
│ 00001.jpg
│ ...
└─labels
00001.txt
...
最後にラベル情報、ディレクトリ構造と平仄を合わせてconfigファイル(custom.yaml)を作成し、データセットの準備は完了です。
# train and val data directory train: ./dataset/train val: ./dataset/valid # number of classes nc: 2 # class names names: ['1つ目のクラス名', '2つ目のクラス名']
今回は、以下のマスク着用判定の公開データセットを利用してモデルを学習してみます。
学習
以下のコードで学習を実行します。
!python train.py --workers 2 \
--device 0 \
--batch-size 16 \
--data data/mask_wearing.yaml \
--img 640 640 \
--cfg cfg/training/yolov7x.yaml \
--weights 'yolov7x.pt' \
--name yolov7x-custom \
--epochs 300 \
--hyp data/hyp.scratch.p5.yaml
学習ログは以下のように出力されます。

テストデータに対する推論結果はこちらです。

わずか100数枚のデータによる学習ですが、非常に正確に検知できていることが分かります。
まとめ
YOLOのような物体検知モデルは、研究がさかんで最新の技術が盛り込まれている一方で、APIが整備されており、かつ使いどころが直感的に分かりやすいため、応用しやすいのが特徴です。
Google Colaboratoyの無料環境でも十分動かすことができるので、ぜひ試してみてください。
チーム・カルポ 秀和システム 2021年08月31日頃
参考文献
DreamBoothによる好きな対象を主役にした画像生成

この記事では、DreamBoothを用いて、自分の持ち物や飼い犬といった任意の対象を主役として、好きなシチュエーションをテキストで指定して画像を生成する方法を紹介します。
DreamBoothとは
概要
DreamBoothとは、Google Researchによる研究で、自分の持ち物や飼い犬といった特定の対象を含む画像を数枚用いて、テキストから画像を生成するモデルをファインチューニングすることで、「ビーチにいるその犬」や「カラフルなカーペットの上を歩くその犬」のような、その対象を含む画像を自由に生成することができるフレームワークです。
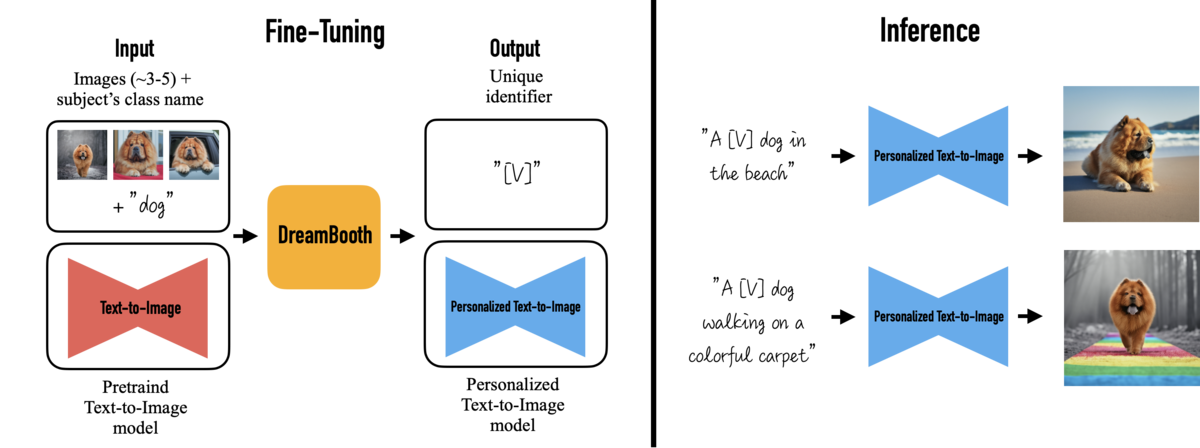

テキストから画像を生成するモデルでは、例えば「ビーチにいる犬」という指定をすれば、その通りの画像を生成することができますが、学習データに多数含まれるような世界的に有名な犬でもない限り、特定の犬を指定することはできません。
しかし、DreamBoothを使えば、自分の飼い犬の数枚の画像でモデルをファインチューニングすることで、その犬を主役に、テキストで好きなシチュエーションを指定して画像を生成できるようになります。
Textual Inversionとの違い
似た考え方にTextual Inversionがあります。
こちらも、数枚のオリジナル画像を用いてモデルをファインチューニングする点ではDreamBoothと同様ですが、Textual Inversionはその対象を示すキーワードのベクトル化部分(embedding)の重みのみを更新するのに対し、DreamBoothではモデル全体を更新します。
つまり、前者では、○○風といった追加した対象の「ニュアンス」を表現することができるようになるのに対し、後者では、追加した対象「そのもの」を忠実に生成することができるようになる点に大きな違いがあります。
Textual Inversionの詳細はこちらの記事をご覧ください。
Stable Diffusionへの置換え
もっとも、Google ResearchによるDreamBoothはテキストから画像を生成するモデルとしてImagenを採用していましたが、Imagenはモデルのネットワークも学習済みの重みも公開されていません。そのため、オリジナルのDreamBoothを個人が自由にファインチューニングすることはできませんでした。
しかし、最近になって別のチームがDreamBoothをオープンソースのStable Diffusionベースに置き換えたことにより、そのネックが解消されつつあります。
例えば、上記リポジトリのissueには、こちらのようなギターの画像13枚を学習データとしてファインチューニングした結果が投稿されています。

学習後に対象のギターを生成するプロンプトを実行した結果がこちら。

ジミ・ヘンドリックスが対象のギターを弾いている画像を生成するプロンプトを実行した結果がこちら。

かなり高精度に対象そのものが再現されているように見えます。
今回はこの実装をGoogle Colaboratoryで試してみたいと思います。
Stable Diffusionの概要や通常の使い方については以下の記事をご覧ください。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
※ 2022年9月時点において、公式リポジトリのコードを利用した本記事の方法は、Google Colaboratoryで提供されているプランのうち、Pro+で割り当てられることのあるA100以外では、GPUメモリが不足することを確認しています。それ以外のプランをご利用の方はこちらをお試しください。
事前準備
まず、モデルが公開されているHugging Faceのアカウントを作成します。
Hugging Faceのトップページから右上の「Sign Up」に進みます。アドレスとパスワードを入力すると、登録したアドレスに認証メールが届くので、メール内のリンクをクリックして作成は完了です。
そして、学習済みパラメータをダウンロードできるようにするために、Stable Diffusionのリポジトリを開き「Access repository」をクリックします。
これで事前準備は完了です。
環境設定
ここからは、Google Colaboratory上で作業を行います。
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、学習・推論時にGPUを利用することができます。
次に、ファインチューニングしたパラメータを保存するために、Googleドライブをマウントしておきます。
#Googleドライブのマウントと作業フォルダの作成 from google.colab import drive drive.mount('/content/drive') !mkdir -p /content/drive/MyDrive/Dreambooth'
続いて、リポジトリのクローンとライブラリのインストールを行います。環境構築の方法は様々ですが、今回はcolab上にMinicondaをインストールし、conda環境を作成します。
# リポジトリのクローン !git clone https://github.com/XavierXiao/Dreambooth-Stable-Diffusion.git %cd Dreambooth-Stable-Diffusion # condacolabのインストール !pip install -q condacolab import condacolab condacolab.install() # 仮想環境の作成 !conda env create -f environment.yaml
モデル設定
ファインチューニングのベースとなる、Stable Diffusionの学習済みのパラメータをダウンロードします。
# Hugging Faceのログイン情報の設定 username = 'ユーザーネームを記載' password = 'パスワードを記載' # Stable Diffusionの学習済みパラメータのダウンロード !mkdir -p weights !wget --http-user=$username --http-passwd=$password https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4-full-ema.ckpt -P weights/sd-v1-4-full-ema.ckpt
学習
今回は、片桐仁さんをDreamBoothの対象にしたいと思います。ファインチューニングに利用する学習用の画像はこちらです。結果に応じて、だいたい10枚から50枚程度準備するのが良さそうです。

これらは、colab上の任意のディレクトリにアップロードしておきます。
もっとも、もともとベースのStable Diffusionの学習データに片桐仁さんの画像が含まれており、ファインチューニングしなくても指名が可能であるとすると意味がありません。そこで、念のため"photo of JIN KATAGIRI"で画像を生成してみます。詳しい生成方法はこちらの記事をご覧ください。

存じ上げない方々です。これは、含まれていないといってよいかと思います。
では、ファインチューニングの準備を進めます。まず、DreamBoothの対象が属するカテゴリの画像を生成します。これは、ファインチューニングの際に、基準画像としてモデルに渡されます。今回は、manの画像を以下のコードで生成します。枚数は、リポジトリで推奨されている200枚とします(対象によっては300枚~400枚程度の方が生成結果が安定するケースもあるようです)。
%%bash
eval "$(conda shell.bash hook)"
conda activate ldm
python scripts/stable_txt2img.py --ddim_eta 0.0 \
--n_samples 200 \
--n_iter 1 \
--scale 10.0 \
--ddim_steps 50 \
--ckpt weights/sd-v1-4-full-ema.ckpt/sd-v1-4-full-ema.ckpt \
--prompt "a photo of a man"
conda deactivate
このような画像が生成されます。

ファインチューニングを実行します。
%%bash
eval "$(conda shell.bash hook)"
conda activate ldm
python main.py --base configs/stable-diffusion/v1-finetune_unfrozen.yaml \
-t \
-n test \
--actual_resume weights/sd-v1-4-full-ema.ckpt/sd-v1-4-full-ema.ckpt \
--gpus 0, \
--data_root "ファインチューニング用の画像を配置したディレクトリ" \
--reg_data_root "/content/Dreambooth-Stable-Diffusion/outputs/txt2img-samples/samples" \
--class_word man \
--no-test
conda deactivate
OSError: cannot open resourceが表示される場合は、こちらのissueをご参照ください。
学習したパラメータは、/content/Dreambooth-Stable-Diffusion/logs以下に保存されるので、必要に応じてGoogleドライブにコピーしておきます。
!cp /content/Dreambooth-Stable-Diffusion/logs/<ckptファイルが保存された場所>/checkpoints/last.ckpt /content/drive/MyDrive/Dreambooth/last.ckpt
推論
では、ファインチューニングしたパラメータで画像を生成してみます。プロンプト内のsksは、DreamBoothの対象を指すランダムな文字列で、リポジトリのデフォルトの文字列をそのまま利用しているものです。ここでは、sks manで片桐仁さんを指定しています。
%%bash
eval "$(conda shell.bash hook)"
conda activate ldm
python scripts/stable_txt2img.py --ddim_eta 0.0 \
--n_samples 8 \
--n_iter 1 \
--scale 10.0 \
--ddim_steps 100 \
--ckpt "ファインチューニング後のパラメータのパス" \
--prompt 'photo of a sks man'
conda deactivate
結果はこちら。

なかなか良い感じです。8枚生成したうちの4枚なので、人の顔としての自然さ自体は、大量に生成して厳選することで向上するものと思われます。または、以下の記事の方法で修正することも可能です。
続いて、"photo of a sks man on the beach"で生成してみます。

なぜ自画像抱えてるの…。
次は、"High quality concept art of a sks man, cinematic lighting, atmospheric, highly detailed, in the style of craig mullins"でイラスト化してみます。

少し離れましたが、特徴は捉えているように見えます。
最後は、"marble statue of a sks man"です。

こちらは特徴を残して生成できているものの、もう少し似せたいところ。
まとめ
自分の好きな対象を主役にして、好きなシチュエーションで画像を生成できる、名前のとおりまさに夢のような技術だと思います。GPUの制約がやや大きいですが、準備する画像の数は非常に少ないので、環境が整う方はぜひ試してみてください。
参考文献
GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
Stable Diffusionによる画像修復(image inpainting)

この記事では、Stable Diffusionを用いて、画像の指定領域をテキストによって修復(inpainting)する方法を紹介します。
Stable Diffusionを用いたtext-to-image、image-to-imageの方法は以下の記事をご覧ください。
Stable Diffusionとは
Stable Diffusionは、High-Resolution Image Synthesis with Latent Diffusion Modelsで提案されたLatent Diffusionという特殊なタイプのDiffusionモデル(拡散モデル)に基づく画像生成モデルです。
拡散モデルは、画像生成タスクにおいて非常に優れた精度を発揮することが知られていますが、一般的にメモリ消費量が膨大であるため、学習や推論が困難でした。
Latent Diffusionは、GANの一種と同様に低次元の潜在表現を活用することでこの点を克服し、メモリの消費を軽減することに成功したため、より汎用的なモデルとなっています。
デモ
それでは、Google Colaboratoryを使って実際に実行していきます。
なお、記事内で紹介したコードをすべて含むノートブックは、以下のリンクから直接参照することができます。
![]()
事前準備
まず、モデルが公開されているHugging Faceのアカウントを作成します。
Hugging Faceのトップページから右上の「Sign Up」に進みます。アドレスとパスワードを入力すると、登録したアドレスに認証メールが届くので、メール内のリンクをクリックして作成は完了です。
次に、Stable Diffusionのリポジトリを開き「Access repository」をクリックします。
最後に、学習済みモデルをダウンロードするためのアクセストークンを取得します。
トップページから先ほど作成したアカウントでログイン後、右上のアカウントのアイコンをクリックし、「Settings」、「Access Tokens」と進みます。画面中央の「New Token」をクリックしてアクセストークンを発行し、コピーしておきます。
これで事前準備は完了です。
環境設定
ここからは、Google Colaboratory上で作業を行います。
はじめに、画面上部のメニューから、「ランタイム」、「ランタイムのタイプを変更」と進み、「ハードウェアアクセラレータ」を「GPU」に変更しておきます。これにより、推論時にGPUを利用することができます。
続いて、必要となるライブラリのインストール、インポートを行います。 diffusersライブラリのバージョン0.3.0時点ではimage inpaintingに試験的にしか対応していないため、githubから直接コードを取得します。
# ライブラリのインストール !pip install git+https://github.com/huggingface/diffusers.git !pip install transformers scipy ftfy # インポート import matplotlib.pyplot as plt from PIL import Image, ImageDraw from google.colab import files import numpy as np import torch from torch import autocast from diffusers import StableDiffusionInpaintPipeline
モデル設定
次に、コピーしておいたアクセストークンを利用して、Hugging Faceから学習済みモデルをダウンロードします。
# 学習済みモデルのダウンロード access_token = 'ここにアクセストークンをペースト' pipe = StableDiffusionInpaintPipeline.from_pretrained( 'CompVis/stable-diffusion-v1-4', revision='fp16', torch_dtype=torch.float16, use_auth_token=access_token ).to('cuda')
画像修復
それでは、画像修復を行っていきます。
image inpaintingでは、元の画像をベースとして、修復範囲を指定し、そこにどのような変更を加えたいかをprompt(プロンプト)と呼ばれる文字列で指示します。
今回は以下の写真をベースにします。

Reuters | Breaking International News & Views
はじめに、服をアロハシャツに変更する指示を与えてみます。 顔から下の修復範囲が白、それ以外が黒となるようなマスク画像を作成し、プロンプトと合わせてモデルに渡します。
# 画像のアップロード files.upload() # ファイル名の設定 image_file = 'アップロードした画像のファイル名' # ベース画像の読込 original_image = Image.open(image_file).convert('RGB') init_image = original_image.resize((512, 512)) # 修復領域の指定 x1 = 60 # 領域の左上のx座標 y1 = 170 # 領域の左上のy座標 x2 = 512 # 領域の右下のx座標 y2 = 512 # 領域の右下のy座標 mask = init_image.copy() draw = ImageDraw.Draw(mask) draw.rectangle([(x1, y1), (x2, y2)], outline=(0, 255, 0), width=3) mask

# マスク画像の作成 draw.rectangle([(0, 0), (512, 512)], outline=(0, 0, 0), fill=(0, 0, 0)) # 全面を黒に draw.rectangle([(x1, y1), (x2, y2)], outline=(255, 255, 255), fill=(255, 255, 255)) # 修復領域を白に # プロンプトの設定 prompt = 'hawaiian shirt' # 画像の修復 with autocast('cuda'): image = pipe(prompt=prompt, init_image=init_image, mask_image=mask)['sample'][0] image.save('test.png')
出力結果はこちらです。

次は、顔を置き換えてみます。 同様に顔部分のマスクを作成し、"Albert Einstein" というプロンプトと合わせてモデルの入力とします。
修復領域がこちら。

出力結果がこちらです。Einsteinのソース画像はモノクロのはずなので、周りに合わせて着色されたようです。

まとめ
本記事では、限られたパターンを生成しただけですが、Stable Diffusionは膨大なテーマのイメージをハイクオリティに生成することができる非常に発展性のある技術です。
これからの動向にもぜひ注目してみてください。
参考文献
High-Resolution Image Synthesis with Latent Diffusion Models
GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model